 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJaeho Lee
NTIRE 2024 Challenge on Low Light Image Enhancement: Methods and Results
Apr 22, 2024
This paper reviews the NTIRE 2024 low light image enhancement challenge, highlighting the proposed solutions and results. The aim of this challenge is to discover an effective network design or solution capable of generating brighter, clearer, and visually appealing results when dealing with a variety of conditions, including ultra-high resolution (4K and beyond), non-uniform illumination, backlighting, extreme darkness, and night scenes. A notable total of 428 participants registered for the challenge, with 22 teams ultimately making valid submissions. This paper meticulously evaluates the state-of-the-art advancements in enhancing low-light images, reflecting the significant progress and creativity in this field.
Machine Learning-Assisted Thermoelectric Cooling for On-Demand Multi-Hotspot Thermal Management
Apr 20, 2024The rapid emergence of System-on-Chip (SoC) technology introduces multiple dynamic hotspots with spatial and temporal evolution to the system, necessitating a more efficient, sophisticated, and intelligent approach to achieve on-demand thermal management. In this study, we present a novel machine learning-assisted optimization algorithm for thermoelectric coolers (TECs) that can achieve global optimal temperature by individually controlling TEC units based on real-time multi-hotspot conditions across the entire domain. A convolutional neural network (CNN) with inception module is trained to comprehend the coupled thermal-electrical physics underlying the system and attain accurate temperature predictions with and without TECs. Due to the intricate interaction among passive thermal gradient, Peltier effect and Joule effect, a local optimal TEC control experiences spatial temperature trade-off which may not lead to a global optimal solution. To address this issue, a backtracking-based optimization algorithm is developed using the designed machine learning model to iterate all possible TEC assignments for attaining global optimal solutions. For arbitrary m by n matrix with NHS hotspots (n, m less than 10 and NHS less than 20), our algorithm is capable of providing global optimal temperature and its corresponding TEC array control in an average of 1.07 second while iterating through tens of temperature predictions behind-the-scenes. This represents a speed increase of over four orders of magnitude compared to traditional FEM strategies which take approximately 18 minutes.
SCANNER: Knowledge-Enhanced Approach for Robust Multi-modal Named Entity Recognition of Unseen Entities
Apr 02, 2024Recent advances in named entity recognition (NER) have pushed the boundary of the task to incorporate visual signals, leading to many variants, including multi-modal NER (MNER) or grounded MNER (GMNER). A key challenge to these tasks is that the model should be able to generalize to the entities unseen during the training, and should be able to handle the training samples with noisy annotations. To address this obstacle, we propose SCANNER (Span CANdidate detection and recognition for NER), a model capable of effectively handling all three NER variants. SCANNER is a two-stage structure; we extract entity candidates in the first stage and use it as a query to get knowledge, effectively pulling knowledge from various sources. We can boost our performance by utilizing this entity-centric extracted knowledge to address unseen entities. Furthermore, to tackle the challenges arising from noisy annotations in NER datasets, we introduce a novel self-distillation method, enhancing the robustness and accuracy of our model in processing training data with inherent uncertainties. Our approach demonstrates competitive performance on the NER benchmark and surpasses existing methods on both MNER and GMNER benchmarks. Further analysis shows that the proposed distillation and knowledge utilization methods improve the performance of our model on various benchmarks.
Neural Image Compression with Text-guided Encoding for both Pixel-level and Perceptual Fidelity
Mar 05, 2024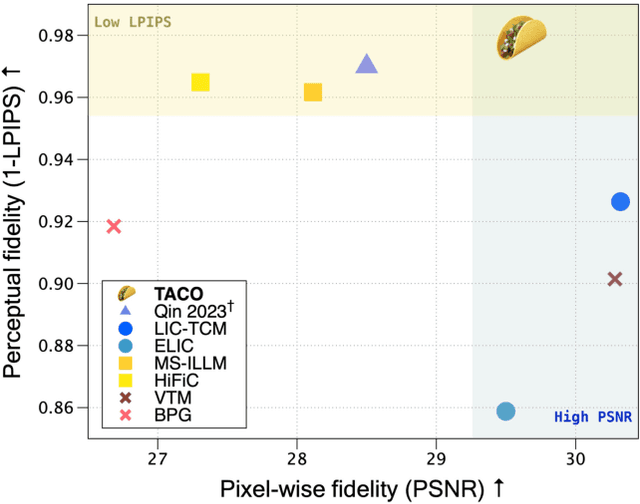
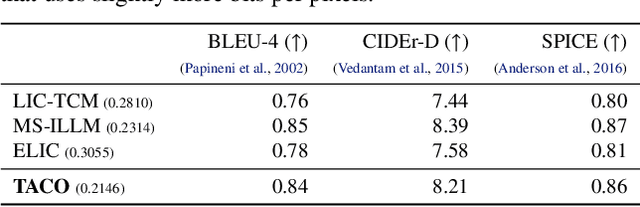

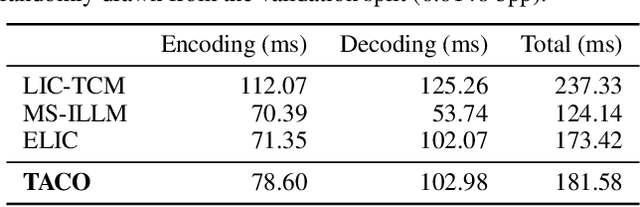
Recent advances in text-guided image compression have shown great potential to enhance the perceptual quality of reconstructed images. These methods, however, tend to have significantly degraded pixel-wise fidelity, limiting their practicality. To fill this gap, we develop a new text-guided image compression algorithm that achieves both high perceptual and pixel-wise fidelity. In particular, we propose a compression framework that leverages text information mainly by text-adaptive encoding and training with joint image-text loss. By doing so, we avoid decoding based on text-guided generative models -- known for high generative diversity -- and effectively utilize the semantic information of text at a global level. Experimental results on various datasets show that our method can achieve high pixel-level and perceptual quality, with either human- or machine-generated captions. In particular, our method outperforms all baselines in terms of LPIPS, with some room for even more improvements when we use more carefully generated captions.
Hybrid Neural Representations for Spherical Data
Feb 05, 2024In this paper, we study hybrid neural representations for spherical data, a domain of increasing relevance in scientific research. In particular, our work focuses on weather and climate data as well as comic microwave background (CMB) data. Although previous studies have delved into coordinate-based neural representations for spherical signals, they often fail to capture the intricate details of highly nonlinear signals. To address this limitation, we introduce a novel approach named Hybrid Neural Representations for Spherical data (HNeR-S). Our main idea is to use spherical feature-grids to obtain positional features which are combined with a multilayer perception to predict the target signal. We consider feature-grids with equirectangular and hierarchical equal area isolatitude pixelization structures that align with weather data and CMB data, respectively. We extensively verify the effectiveness of our HNeR-S for regression, super-resolution, temporal interpolation, and compression tasks.
In Search of a Data Transformation That Accelerates Neural Field Training
Nov 28, 2023Neural field is an emerging paradigm in data representation that trains a neural network to approximate the given signal. A key obstacle that prevents its widespread adoption is the encoding speed-generating neural fields requires an overfitting of a neural network, which can take a significant number of SGD steps to reach the desired fidelity level. In this paper, we delve into the impacts of data transformations on the speed of neural field training, specifically focusing on how permuting pixel locations affect the convergence speed of SGD. Counterintuitively, we find that randomly permuting the pixel locations can considerably accelerate the training. To explain this phenomenon, we examine the neural field training through the lens of PSNR curves, loss landscapes, and error patterns. Our analyses suggest that the random pixel permutations remove the easy-to-fit patterns, which facilitate easy optimization in the early stage but hinder capturing fine details of the signal.
Communication-Efficient Split Learning via Adaptive Feature-Wise Compression
Jul 20, 2023



This paper proposes a novel communication-efficient split learning (SL) framework, named SplitFC, which reduces the communication overhead required for transmitting intermediate feature and gradient vectors during the SL training process. The key idea of SplitFC is to leverage different dispersion degrees exhibited in the columns of the matrices. SplitFC incorporates two compression strategies: (i) adaptive feature-wise dropout and (ii) adaptive feature-wise quantization. In the first strategy, the intermediate feature vectors are dropped with adaptive dropout probabilities determined based on the standard deviation of these vectors. Then, by the chain rule, the intermediate gradient vectors associated with the dropped feature vectors are also dropped. In the second strategy, the non-dropped intermediate feature and gradient vectors are quantized using adaptive quantization levels determined based on the ranges of the vectors. To minimize the quantization error, the optimal quantization levels of this strategy are derived in a closed-form expression. Simulation results on the MNIST, CIFAR-10, and CelebA datasets demonstrate that SplitFC provides more than a 5.6% increase in classification accuracy compared to state-of-the-art SL frameworks, while they require 320 times less communication overhead compared to the vanilla SL framework without compression.
Debiased Distillation by Transplanting the Last Layer
Feb 22, 2023



Deep models are susceptible to learning spurious correlations, even during the post-processing. We take a closer look at the knowledge distillation -- a popular post-processing technique for model compression -- and find that distilling with biased training data gives rise to a biased student, even when the teacher is debiased. To address this issue, we propose a simple knowledge distillation algorithm, coined DeTT (Debiasing by Teacher Transplanting). Inspired by a recent observation that the last neural net layer plays an overwhelmingly important role in debiasing, DeTT directly transplants the teacher's last layer to the student. Remaining layers are distilled by matching the feature map outputs of the student and the teacher, where the samples are reweighted to mitigate the dataset bias. Importantly, DeTT does not rely on the availability of extensive annotations on the bias-related attribute, which is typically not available during the post-processing phase. Throughout our experiments, DeTT successfully debiases the student model, consistently outperforming the baselines in terms of the worst-group accuracy.
MaskedKD: Efficient Distillation of Vision Transformers with Masked Images
Feb 21, 2023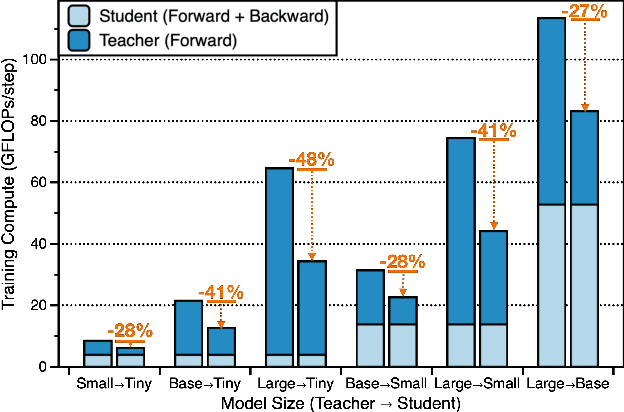
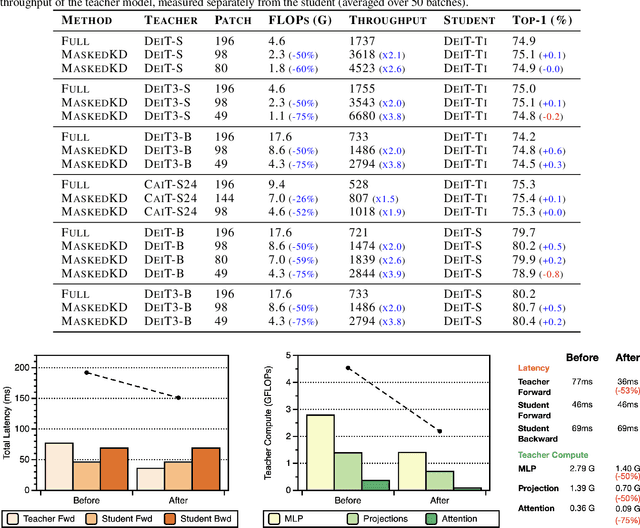
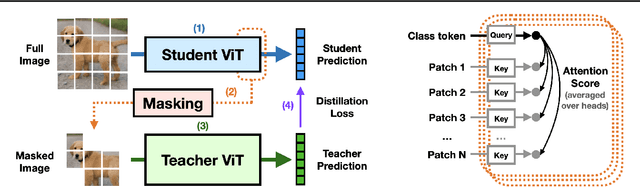

Knowledge distillation is a popular and effective regularization technique for training lightweight models, but it also adds significant overhead to the training cost. The drawback is most pronounced when we use large-scale models as our teachers, such as vision transformers (ViTs). We present MaskedKD, a simple yet effective method for reducing the training cost of ViT distillation. MaskedKD masks a fraction of image patch tokens fed to the teacher to save the teacher inference cost. The tokens to mask are determined based on the last layer attention score of the student model, to which we provide the full image. Without requiring any architectural change of the teacher or making sacrifices in the student performance, MaskedKD dramatically reduces the computations and time required for distilling ViTs. We demonstrate that MaskedKD can save up to $50\%$ of the cost of running inference on the teacher model without any performance drop on the student, leading to approximately $28\%$ drop in the teacher and student compute combined.
Efficient Meta-Learning via Error-based Context Pruning for Implicit Neural Representations
Feb 01, 2023



We introduce an efficient optimization-based meta-learning technique for learning large-scale implicit neural representations (INRs). Our main idea is designing an online selection of context points, which can significantly reduce memory requirements for meta-learning in any established setting. By doing so, we expect additional memory savings which allows longer per-signal adaptation horizons (at a given memory budget), leading to better meta-initializations by reducing myopia and, more crucially, enabling learning on high-dimensional signals. To implement such context pruning, our technical novelty is three-fold. First, we propose a selection scheme that adaptively chooses a subset at each adaptation step based on the predictive error, leading to the modeling of the global structure of the signal in early steps and enabling the later steps to capture its high-frequency details. Second, we counteract any possible information loss from context pruning by minimizing the parameter distance to a bootstrapped target model trained on a full context set. Finally, we suggest using the full context set with a gradient scaling scheme at test-time. Our technique is model-agnostic, intuitive, and straightforward to implement, showing significant reconstruction improvements for a wide range of signals. Code is available at https://github.com/jihoontack/ECoP