 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJing Lin
ChatHuman: Language-driven 3D Human Understanding with Retrieval-Augmented Tool Reasoning
May 07, 2024
Numerous methods have been proposed to detect, estimate, and analyze properties of people in images, including the estimation of 3D pose, shape, contact, human-object interaction, emotion, and more. Each of these methods works in isolation instead of synergistically. Here we address this problem and build a language-driven human understanding system -- ChatHuman, which combines and integrates the skills of many different methods. To do so, we finetune a Large Language Model (LLM) to select and use a wide variety of existing tools in response to user inputs. In doing so, ChatHuman is able to combine information from multiple tools to solve problems more accurately than the individual tools themselves and to leverage tool output to improve its ability to reason about humans. The novel features of ChatHuman include leveraging academic publications to guide the application of 3D human-related tools, employing a retrieval-augmented generation model to generate in-context-learning examples for handling new tools, and discriminating and integrating tool results to enhance 3D human understanding. Our experiments show that ChatHuman outperforms existing models in both tool selection accuracy and performance across multiple 3D human-related tasks. ChatHuman is a step towards consolidating diverse methods for human analysis into a single, powerful, system for 3D human reasoning.
A Novel Context driven Critical Integrative Levels (CIL) Approach: Advancing Human-Centric and Integrative Lighting Asset Management in Public Libraries with Practical Thresholds
Apr 26, 2024This paper proposes the context driven Critical Integrative Levels (CIL), a novel approach to lighting asset management in public libraries that aligns with the transformative vision of human-centric and integrative lighting. This approach encompasses not only the visual aspects of lighting performance but also prioritizes the physiological and psychological well-being of library users. Incorporating a newly defined metric, Mean Time of Exposure (MTOE), the approach quantifies user-light interaction, enabling tailored lighting strategies that respond to diverse activities and needs in library spaces. Case studies demonstrate how the CIL matrix can be practically applied, offering significant improvements over conventional methods by focusing on optimized user experiences from both visual impacts and non-visual effects.
NTIRE 2024 Challenge on Low Light Image Enhancement: Methods and Results
Apr 22, 2024This paper reviews the NTIRE 2024 low light image enhancement challenge, highlighting the proposed solutions and results. The aim of this challenge is to discover an effective network design or solution capable of generating brighter, clearer, and visually appealing results when dealing with a variety of conditions, including ultra-high resolution (4K and beyond), non-uniform illumination, backlighting, extreme darkness, and night scenes. A notable total of 428 participants registered for the challenge, with 22 teams ultimately making valid submissions. This paper meticulously evaluates the state-of-the-art advancements in enhancing low-light images, reflecting the significant progress and creativity in this field.
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Jan 25, 2024We introduce Grounded SAM, which uses Grounding DINO as an open-set object detector to combine with the segment anything model (SAM). This integration enables the detection and segmentation of any regions based on arbitrary text inputs and opens a door to connecting various vision models. As shown in Fig.1, a wide range of vision tasks can be achieved by using the versatile Grounded SAM pipeline. For example, an automatic annotation pipeline based solely on input images can be realized by incorporating models such as BLIP and Recognize Anything. Additionally, incorporating Stable-Diffusion allows for controllable image editing, while the integration of OSX facilitates promptable 3D human motion analysis. Grounded SAM also shows superior performance on open-vocabulary benchmarks, achieving 48.7 mean AP on SegInW (Segmentation in the wild) zero-shot benchmark with the combination of Grounding DINO-Base and SAM-Huge models.
DPoser: Diffusion Model as Robust 3D Human Pose Prior
Dec 09, 2023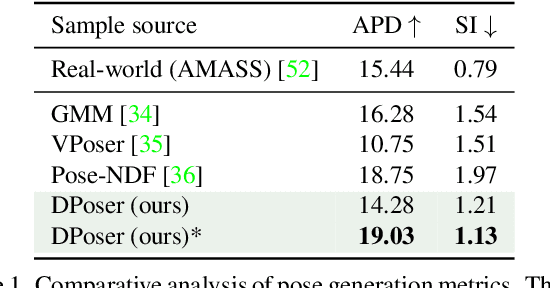
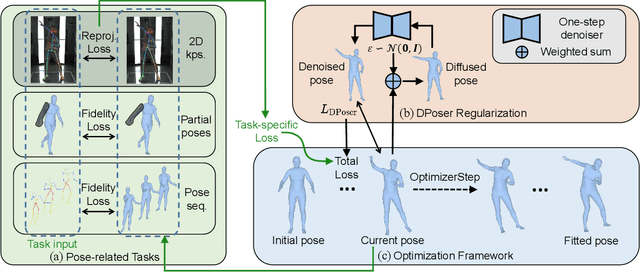
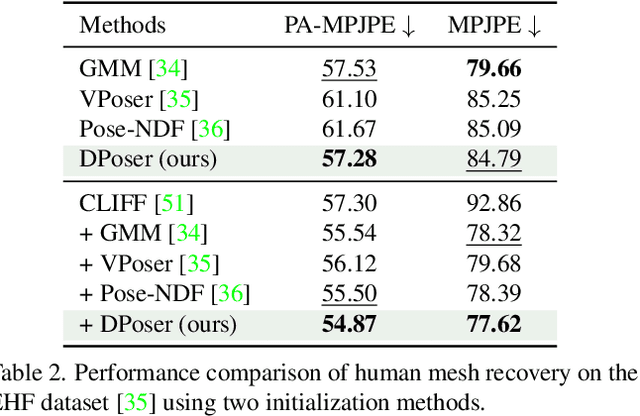
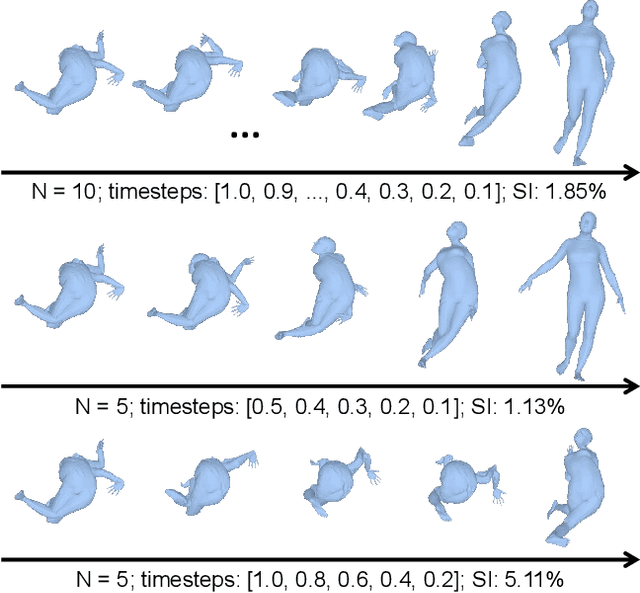
Modeling human pose is a cornerstone in applications from human-robot interaction to augmented reality, yet crafting a robust human pose prior remains a challenge due to biomechanical constraints and diverse human movements. Traditional priors like VAEs and NDFs often fall short in realism and generalization, especially in extreme conditions such as unseen noisy poses. To address these issues, we introduce DPoser, a robust and versatile human pose prior built upon diffusion models. Designed with optimization frameworks, DPoser seamlessly integrates into various pose-centric applications, including human mesh recovery, pose completion, and motion denoising. Specifically, by formulating these tasks as inverse problems, we employ variational diffusion sampling for efficient solving. Furthermore, acknowledging the disparity between the articulated poses we focus on and structured images in previous research, we propose a truncated timestep scheduling to boost performance on downstream tasks. Our exhaustive experiments demonstrate DPoser's superiority over existing state-of-the-art pose priors across multiple tasks.
PhysHOI: Physics-Based Imitation of Dynamic Human-Object Interaction
Dec 07, 2023Humans interact with objects all the time. Enabling a humanoid to learn human-object interaction (HOI) is a key step for future smart animation and intelligent robotics systems. However, recent progress in physics-based HOI requires carefully designed task-specific rewards, making the system unscalable and labor-intensive. This work focuses on dynamic HOI imitation: teaching humanoid dynamic interaction skills through imitating kinematic HOI demonstrations. It is quite challenging because of the complexity of the interaction between body parts and objects and the lack of dynamic HOI data. To handle the above issues, we present PhysHOI, the first physics-based whole-body HOI imitation approach without task-specific reward designs. Except for the kinematic HOI representations of humans and objects, we introduce the contact graph to model the contact relations between body parts and objects explicitly. A contact graph reward is also designed, which proved to be critical for precise HOI imitation. Based on the key designs, PhysHOI can imitate diverse HOI tasks simply yet effectively without prior knowledge. To make up for the lack of dynamic HOI scenarios in this area, we introduce the BallPlay dataset that contains eight whole-body basketball skills. We validate PhysHOI on diverse HOI tasks, including whole-body grasping and basketball skills.
PoseGPT: Chatting about 3D Human Pose
Nov 30, 2023We introduce PoseGPT, a framework employing Large Language Models (LLMs) to understand and reason about 3D human poses from images or textual descriptions. Our work is motivated by the human ability to intuitively understand postures from a single image or a brief description, a process that intertwines image interpretation, world knowledge, and an understanding of body language. Traditional human pose estimation methods, whether image-based or text-based, often lack holistic scene comprehension and nuanced reasoning, leading to a disconnect between visual data and its real-world implications. PoseGPT addresses these limitations by embedding SMPL poses as a distinct signal token within a multi-modal LLM, enabling direct generation of 3D body poses from both textual and visual inputs. This approach not only simplifies pose prediction but also empowers LLMs to apply their world knowledge in reasoning about human poses, fostering two advanced tasks: speculative pose generation and reasoning about pose estimation. These tasks involve reasoning about humans to generate 3D poses from subtle text queries, possibly accompanied by images. We establish benchmarks for these tasks, moving beyond traditional 3D pose generation and estimation methods. Our results show that PoseGPT outperforms existing multimodal LLMs and task-sepcific methods on these newly proposed tasks. Furthermore, PoseGPT's ability to understand and generate 3D human poses based on complex reasoning opens new directions in human pose analysis.
Binarized 3D Whole-body Human Mesh Recovery
Nov 24, 2023
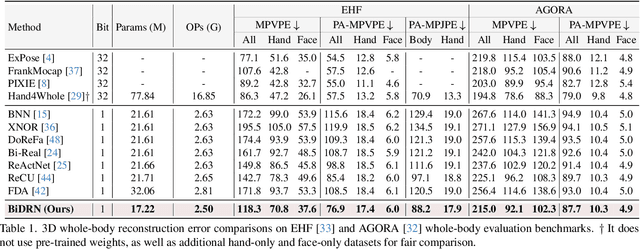
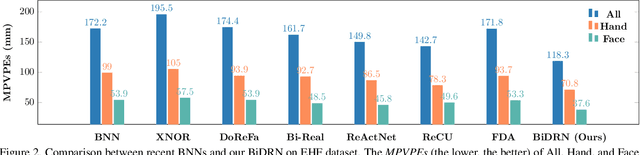
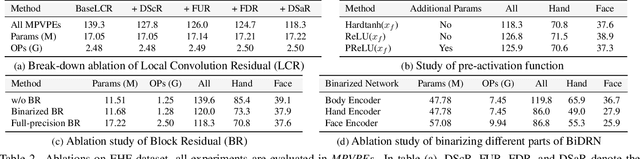
3D whole-body human mesh recovery aims to reconstruct the 3D human body, face, and hands from a single image. Although powerful deep learning models have achieved accurate estimation in this task, they require enormous memory and computational resources. Consequently, these methods can hardly be deployed on resource-limited edge devices. In this work, we propose a Binarized Dual Residual Network (BiDRN), a novel quantization method to estimate the 3D human body, face, and hands parameters efficiently. Specifically, we design a basic unit Binarized Dual Residual Block (BiDRB) composed of Local Convolution Residual (LCR) and Block Residual (BR), which can preserve full-precision information as much as possible. For LCR, we generalize it to four kinds of convolutional modules so that full-precision information can be propagated even between mismatched dimensions. We also binarize the face and hands box-prediction network as Binaried BoxNet, which can further reduce the model redundancy. Comprehensive quantitative and qualitative experiments demonstrate the effectiveness of BiDRN, which has a significant improvement over state-of-the-art binarization algorithms. Moreover, our proposed BiDRN achieves comparable performance with full-precision method Hand4Whole while using just 22.1% parameters and 14.8% operations. We will release all the code and pretrained models.
HumanTOMATO: Text-aligned Whole-body Motion Generation
Oct 19, 2023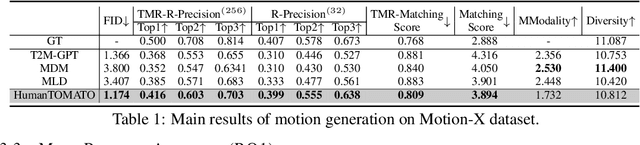
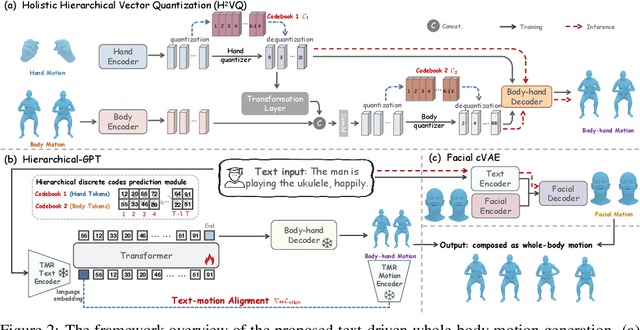

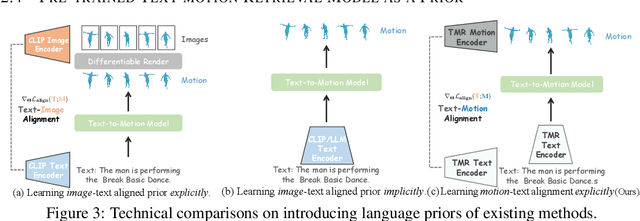
This work targets a novel text-driven whole-body motion generation task, which takes a given textual description as input and aims at generating high-quality, diverse, and coherent facial expressions, hand gestures, and body motions simultaneously. Previous works on text-driven motion generation tasks mainly have two limitations: they ignore the key role of fine-grained hand and face controlling in vivid whole-body motion generation, and lack a good alignment between text and motion. To address such limitations, we propose a Text-aligned whOle-body Motion generATiOn framework, named HumanTOMATO, which is the first attempt to our knowledge towards applicable holistic motion generation in this research area. To tackle this challenging task, our solution includes two key designs: (1) a Holistic Hierarchical VQ-VAE (aka H$^2$VQ) and a Hierarchical-GPT for fine-grained body and hand motion reconstruction and generation with two structured codebooks; and (2) a pre-trained text-motion-alignment model to help generated motion align with the input textual description explicitly. Comprehensive experiments verify that our model has significant advantages in both the quality of generated motions and their alignment with text.
Driving behavior-guided battery health monitoring for electric vehicles using machine learning
Sep 25, 2023

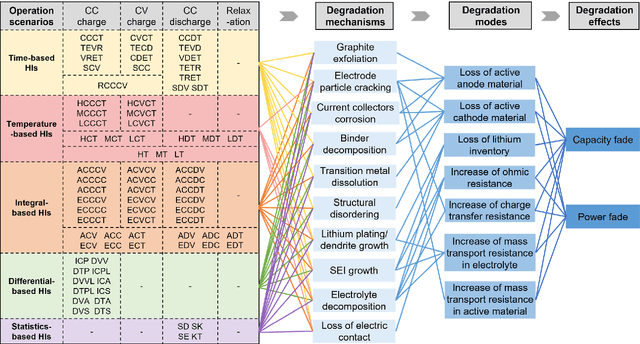

An accurate estimation of the state of health (SOH) of batteries is critical to ensuring the safe and reliable operation of electric vehicles (EVs). Feature-based machine learning methods have exhibited enormous potential for rapidly and precisely monitoring battery health status. However, simultaneously using various health indicators (HIs) may weaken estimation performance due to feature redundancy. Furthermore, ignoring real-world driving behaviors can lead to inaccurate estimation results as some features are rarely accessible in practical scenarios. To address these issues, we proposed a feature-based machine learning pipeline for reliable battery health monitoring, enabled by evaluating the acquisition probability of features under real-world driving conditions. We first summarized and analyzed various individual HIs with mechanism-related interpretations, which provide insightful guidance on how these features relate to battery degradation modes. Moreover, all features were carefully evaluated and screened based on estimation accuracy and correlation analysis on three public battery degradation datasets. Finally, the scenario-based feature fusion and acquisition probability-based practicality evaluation method construct a useful tool for feature extraction with consideration of driving behaviors. This work highlights the importance of balancing the performance and practicality of HIs during the development of feature-based battery health monitoring algorithms.