 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhaoyang Zeng
T-Rex2: Towards Generic Object Detection via Text-Visual Prompt Synergy
Mar 21, 2024
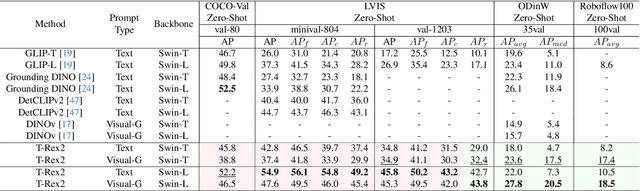

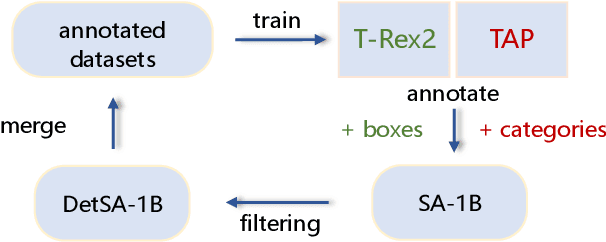

We present T-Rex2, a highly practical model for open-set object detection. Previous open-set object detection methods relying on text prompts effectively encapsulate the abstract concept of common objects, but struggle with rare or complex object representation due to data scarcity and descriptive limitations. Conversely, visual prompts excel in depicting novel objects through concrete visual examples, but fall short in conveying the abstract concept of objects as effectively as text prompts. Recognizing the complementary strengths and weaknesses of both text and visual prompts, we introduce T-Rex2 that synergizes both prompts within a single model through contrastive learning. T-Rex2 accepts inputs in diverse formats, including text prompts, visual prompts, and the combination of both, so that it can handle different scenarios by switching between the two prompt modalities. Comprehensive experiments demonstrate that T-Rex2 exhibits remarkable zero-shot object detection capabilities across a wide spectrum of scenarios. We show that text prompts and visual prompts can benefit from each other within the synergy, which is essential to cover massive and complicated real-world scenarios and pave the way towards generic object detection. Model API is now available at \url{https://github.com/IDEA-Research/T-Rex}.
TAPTR: Tracking Any Point with Transformers as Detection
Mar 19, 2024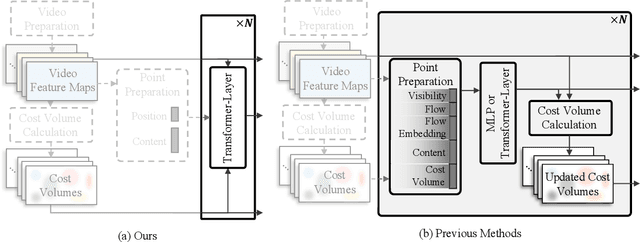
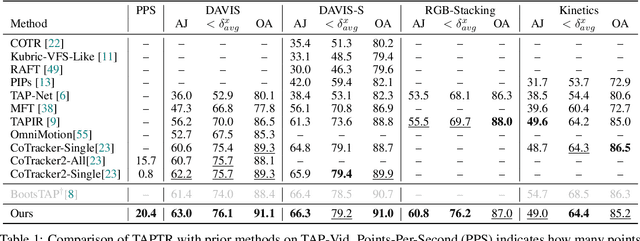
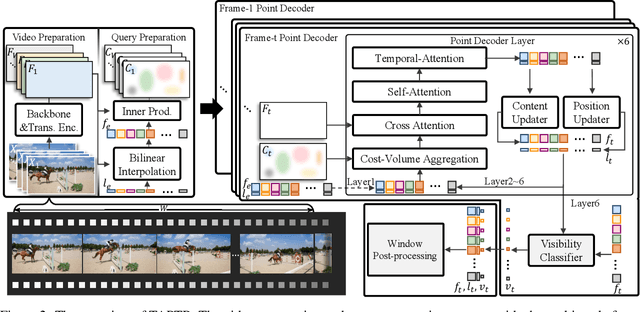

In this paper, we propose a simple and strong framework for Tracking Any Point with TRansformers (TAPTR). Based on the observation that point tracking bears a great resemblance to object detection and tracking, we borrow designs from DETR-like algorithms to address the task of TAP. In the proposed framework, in each video frame, each tracking point is represented as a point query, which consists of a positional part and a content part. As in DETR, each query (its position and content feature) is naturally updated layer by layer. Its visibility is predicted by its updated content feature. Queries belonging to the same tracking point can exchange information through self-attention along the temporal dimension. As all such operations are well-designed in DETR-like algorithms, the model is conceptually very simple. We also adopt some useful designs such as cost volume from optical flow models and develop simple designs to provide long temporal information while mitigating the feature drifting issue. Our framework demonstrates strong performance with state-of-the-art performance on various TAP datasets with faster inference speed.
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Jan 25, 2024We introduce Grounded SAM, which uses Grounding DINO as an open-set object detector to combine with the segment anything model (SAM). This integration enables the detection and segmentation of any regions based on arbitrary text inputs and opens a door to connecting various vision models. As shown in Fig.1, a wide range of vision tasks can be achieved by using the versatile Grounded SAM pipeline. For example, an automatic annotation pipeline based solely on input images can be realized by incorporating models such as BLIP and Recognize Anything. Additionally, incorporating Stable-Diffusion allows for controllable image editing, while the integration of OSX facilitates promptable 3D human motion analysis. Grounded SAM also shows superior performance on open-vocabulary benchmarks, achieving 48.7 mean AP on SegInW (Segmentation in the wild) zero-shot benchmark with the combination of Grounding DINO-Base and SAM-Huge models.
T-Rex: Counting by Visual Prompting
Nov 22, 2023We introduce T-Rex, an interactive object counting model designed to first detect and then count any objects. We formulate object counting as an open-set object detection task with the integration of visual prompts. Users can specify the objects of interest by marking points or boxes on a reference image, and T-Rex then detects all objects with a similar pattern. Guided by the visual feedback from T-Rex, users can also interactively refine the counting results by prompting on missing or falsely-detected objects. T-Rex has achieved state-of-the-art performance on several class-agnostic counting benchmarks. To further exploit its potential, we established a new counting benchmark encompassing diverse scenarios and challenges. Both quantitative and qualitative results show that T-Rex possesses exceptional zero-shot counting capabilities. We also present various practical application scenarios for T-Rex, illustrating its potential in the realm of visual prompting.
DFA3D: 3D Deformable Attention For 2D-to-3D Feature Lifting
Jul 24, 2023In this paper, we propose a new operator, called 3D DeFormable Attention (DFA3D), for 2D-to-3D feature lifting, which transforms multi-view 2D image features into a unified 3D space for 3D object detection. Existing feature lifting approaches, such as Lift-Splat-based and 2D attention-based, either use estimated depth to get pseudo LiDAR features and then splat them to a 3D space, which is a one-pass operation without feature refinement, or ignore depth and lift features by 2D attention mechanisms, which achieve finer semantics while suffering from a depth ambiguity problem. In contrast, our DFA3D-based method first leverages the estimated depth to expand each view's 2D feature map to 3D and then utilizes DFA3D to aggregate features from the expanded 3D feature maps. With the help of DFA3D, the depth ambiguity problem can be effectively alleviated from the root, and the lifted features can be progressively refined layer by layer, thanks to the Transformer-like architecture. In addition, we propose a mathematically equivalent implementation of DFA3D which can significantly improve its memory efficiency and computational speed. We integrate DFA3D into several methods that use 2D attention-based feature lifting with only a few modifications in code and evaluate on the nuScenes dataset. The experiment results show a consistent improvement of +1.41\% mAP on average, and up to +15.1\% mAP improvement when high-quality depth information is available, demonstrating the superiority, applicability, and huge potential of DFA3D. The code is available at https://github.com/IDEA-Research/3D-deformable-attention.git.
detrex: Benchmarking Detection Transformers
Jun 13, 2023

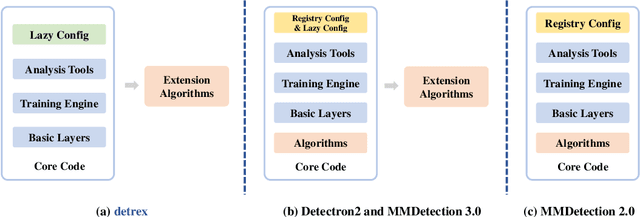
The DEtection TRansformer (DETR) algorithm has received considerable attention in the research community and is gradually emerging as a mainstream approach for object detection and other perception tasks. However, the current field lacks a unified and comprehensive benchmark specifically tailored for DETR-based models. To address this issue, we develop a unified, highly modular, and lightweight codebase called detrex, which supports a majority of the mainstream DETR-based instance recognition algorithms, covering various fundamental tasks, including object detection, segmentation, and pose estimation. We conduct extensive experiments under detrex and perform a comprehensive benchmark for DETR-based models. Moreover, we enhance the performance of detection transformers through the refinement of training hyper-parameters, providing strong baselines for supported algorithms.We hope that detrex could offer research communities a standardized and unified platform to evaluate and compare different DETR-based models while fostering a deeper understanding and driving advancements in DETR-based instance recognition. Our code is available at https://github.com/IDEA-Research/detrex. The project is currently being actively developed. We encourage the community to use detrex codebase for further development and contributions.
A Strong and Reproducible Object Detector with Only Public Datasets
Apr 25, 2023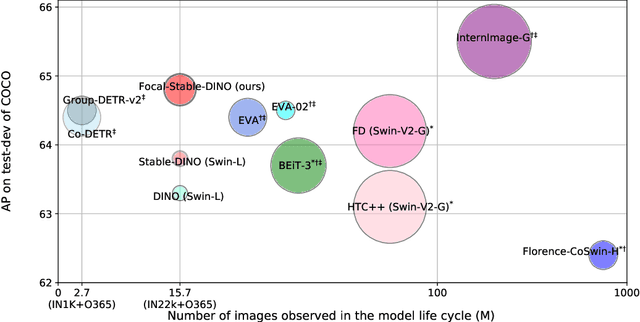

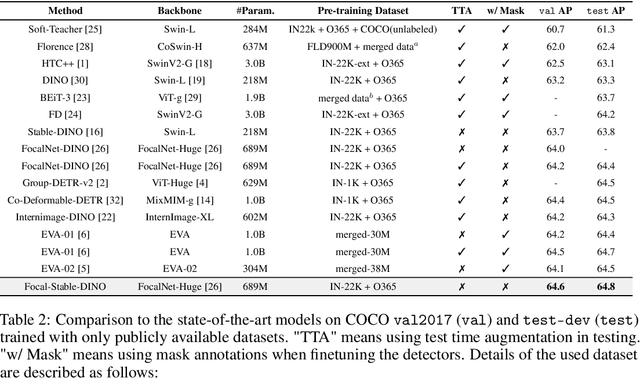
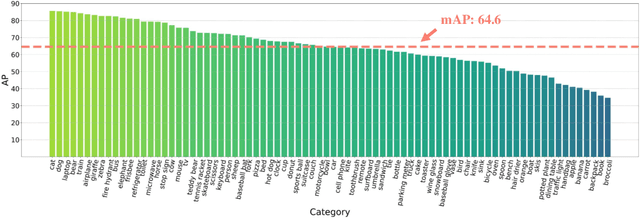
This work presents Focal-Stable-DINO, a strong and reproducible object detection model which achieves 64.6 AP on COCO val2017 and 64.8 AP on COCO test-dev using only 700M parameters without any test time augmentation. It explores the combination of the powerful FocalNet-Huge backbone with the effective Stable-DINO detector. Different from existing SOTA models that utilize an extensive number of parameters and complex training techniques on large-scale private data or merged data, our model is exclusively trained on the publicly available dataset Objects365, which ensures the reproducibility of our approach.
Detection Transformer with Stable Matching
Apr 10, 2023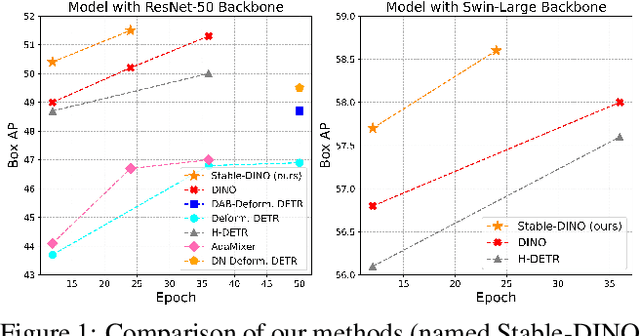
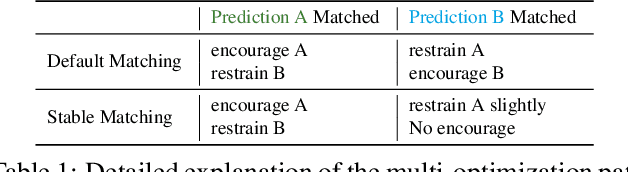
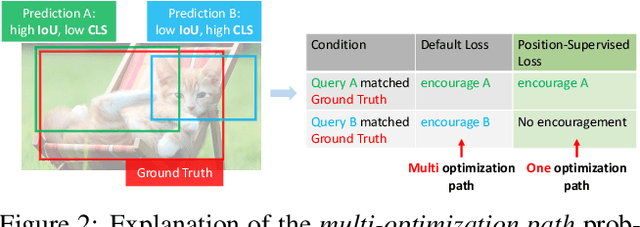
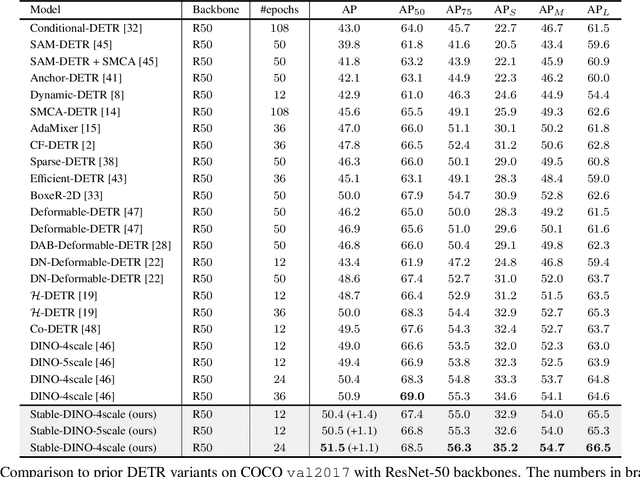
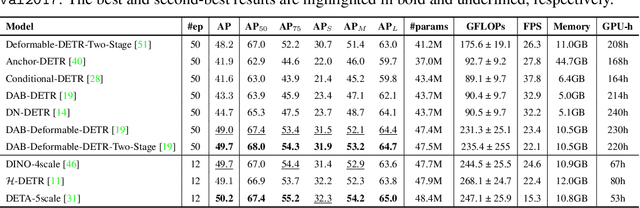
This paper is concerned with the matching stability problem across different decoder layers in DEtection TRansformers (DETR). We point out that the unstable matching in DETR is caused by a multi-optimization path problem, which is highlighted by the one-to-one matching design in DETR. To address this problem, we show that the most important design is to use and only use positional metrics (like IOU) to supervise classification scores of positive examples. Under the principle, we propose two simple yet effective modifications by integrating positional metrics to DETR's classification loss and matching cost, named position-supervised loss and position-modulated cost. We verify our methods on several DETR variants. Our methods show consistent improvements over baselines. By integrating our methods with DINO, we achieve 50.4 and 51.5 AP on the COCO detection benchmark using ResNet-50 backbones under 12 epochs and 24 epochs training settings, achieving a new record under the same setting. We achieve 63.8 AP on COCO detection test-dev with a Swin-Large backbone. Our code will be made available at https://github.com/IDEA-Research/Stable-DINO.
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Mar 20, 2023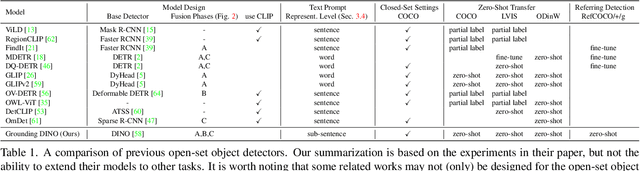
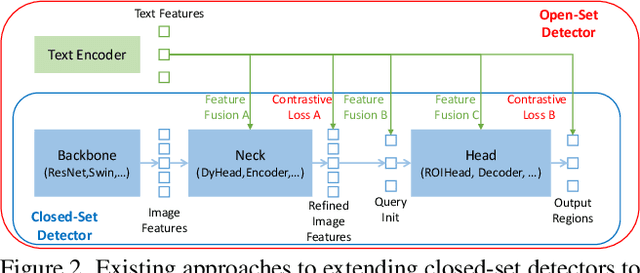
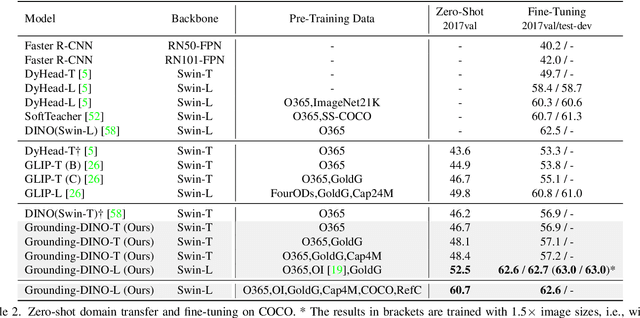
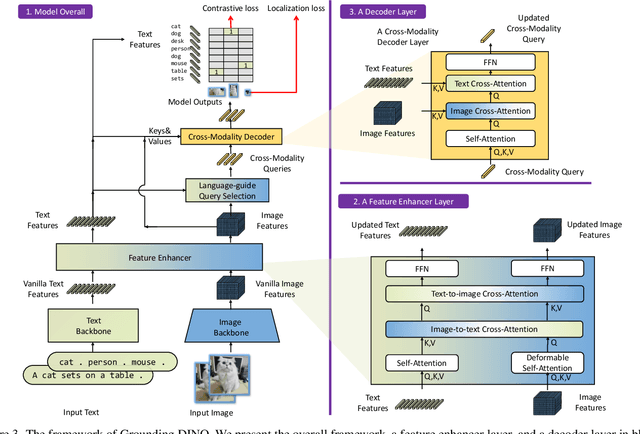
In this paper, we present an open-set object detector, called Grounding DINO, by marrying Transformer-based detector DINO with grounded pre-training, which can detect arbitrary objects with human inputs such as category names or referring expressions. The key solution of open-set object detection is introducing language to a closed-set detector for open-set concept generalization. To effectively fuse language and vision modalities, we conceptually divide a closed-set detector into three phases and propose a tight fusion solution, which includes a feature enhancer, a language-guided query selection, and a cross-modality decoder for cross-modality fusion. While previous works mainly evaluate open-set object detection on novel categories, we propose to also perform evaluations on referring expression comprehension for objects specified with attributes. Grounding DINO performs remarkably well on all three settings, including benchmarks on COCO, LVIS, ODinW, and RefCOCO/+/g. Grounding DINO achieves a $52.5$ AP on the COCO detection zero-shot transfer benchmark, i.e., without any training data from COCO. It sets a new record on the ODinW zero-shot benchmark with a mean $26.1$ AP. Code will be available at \url{https://github.com/IDEA-Research/GroundingDINO}.