 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHe Cao
MoleculeQA: A Dataset to Evaluate Factual Accuracy in Molecular Comprehension
Mar 13, 2024
Large language models are playing an increasingly significant role in molecular research, yet existing models often generate erroneous information, posing challenges to accurate molecular comprehension. Traditional evaluation metrics for generated content fail to assess a model's accuracy in molecular understanding. To rectify the absence of factual evaluation, we present MoleculeQA, a novel question answering (QA) dataset which possesses 62K QA pairs over 23K molecules. Each QA pair, composed of a manual question, a positive option and three negative options, has consistent semantics with a molecular description from authoritative molecular corpus. MoleculeQA is not only the first benchmark for molecular factual bias evaluation but also the largest QA dataset for molecular research. A comprehensive evaluation on MoleculeQA for existing molecular LLMs exposes their deficiencies in specific areas and pinpoints several particularly crucial factors for molecular understanding.
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Jan 25, 2024We introduce Grounded SAM, which uses Grounding DINO as an open-set object detector to combine with the segment anything model (SAM). This integration enables the detection and segmentation of any regions based on arbitrary text inputs and opens a door to connecting various vision models. As shown in Fig.1, a wide range of vision tasks can be achieved by using the versatile Grounded SAM pipeline. For example, an automatic annotation pipeline based solely on input images can be realized by incorporating models such as BLIP and Recognize Anything. Additionally, incorporating Stable-Diffusion allows for controllable image editing, while the integration of OSX facilitates promptable 3D human motion analysis. Grounded SAM also shows superior performance on open-vocabulary benchmarks, achieving 48.7 mean AP on SegInW (Segmentation in the wild) zero-shot benchmark with the combination of Grounding DINO-Base and SAM-Huge models.
InstructMol: Multi-Modal Integration for Building a Versatile and Reliable Molecular Assistant in Drug Discovery
Nov 27, 2023
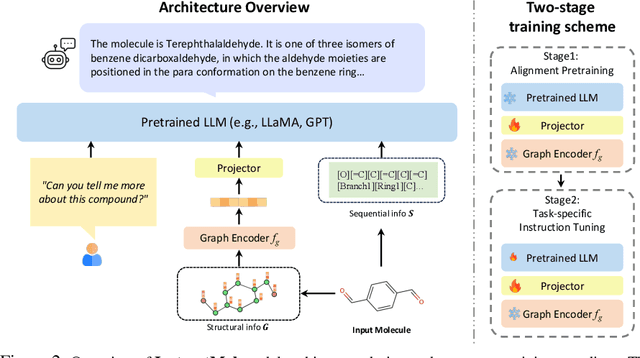
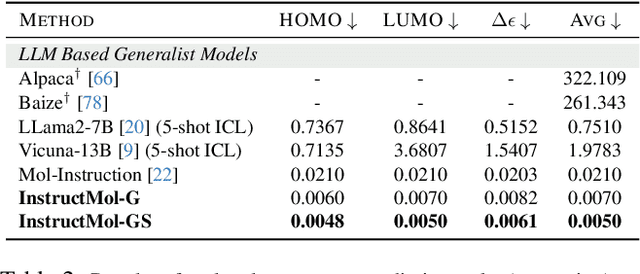
The rapid evolution of artificial intelligence in drug discovery encounters challenges with generalization and extensive training, yet Large Language Models (LLMs) offer promise in reshaping interactions with complex molecular data. Our novel contribution, InstructMol, a multi-modal LLM, effectively aligns molecular structures with natural language via an instruction-tuning approach, utilizing a two-stage training strategy that adeptly combines limited domain-specific data with molecular and textual information. InstructMol showcases substantial performance improvements in drug discovery-related molecular tasks, surpassing leading LLMs and significantly reducing the gap with specialized models, thereby establishing a robust foundation for a versatile and dependable drug discovery assistant.
TOSS:High-quality Text-guided Novel View Synthesis from a Single Image
Oct 16, 2023In this paper, we present TOSS, which introduces text to the task of novel view synthesis (NVS) from just a single RGB image. While Zero-1-to-3 has demonstrated impressive zero-shot open-set NVS capability, it treats NVS as a pure image-to-image translation problem. This approach suffers from the challengingly under-constrained nature of single-view NVS: the process lacks means of explicit user control and often results in implausible NVS generations. To address this limitation, TOSS uses text as high-level semantic information to constrain the NVS solution space. TOSS fine-tunes text-to-image Stable Diffusion pre-trained on large-scale text-image pairs and introduces modules specifically tailored to image and camera pose conditioning, as well as dedicated training for pose correctness and preservation of fine details. Comprehensive experiments are conducted with results showing that our proposed TOSS outperforms Zero-1-to-3 with more plausible, controllable and multiview-consistent NVS results. We further support these results with comprehensive ablations that underscore the effectiveness and potential of the introduced semantic guidance and architecture design.
ChatCounselor: A Large Language Models for Mental Health Support
Sep 27, 2023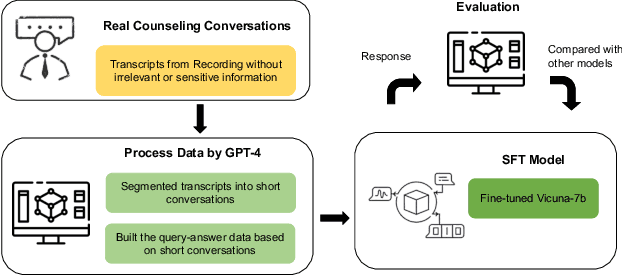
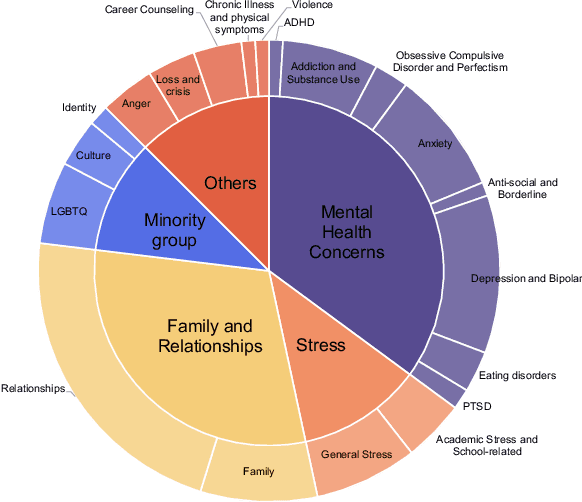


This paper presents ChatCounselor, a large language model (LLM) solution designed to provide mental health support. Unlike generic chatbots, ChatCounselor is distinguished by its foundation in real conversations between consulting clients and professional psychologists, enabling it to possess specialized knowledge and counseling skills in the field of psychology. The training dataset, Psych8k, was constructed from 260 in-depth interviews, each spanning an hour. To assess the quality of counseling responses, the counseling Bench was devised. Leveraging GPT-4 and meticulously crafted prompts based on seven metrics of psychological counseling assessment, the model underwent evaluation using a set of real-world counseling questions. Impressively, ChatCounselor surpasses existing open-source models in the counseling Bench and approaches the performance level of ChatGPT, showcasing the remarkable enhancement in model capability attained through high-quality domain-specific data.
detrex: Benchmarking Detection Transformers
Jun 13, 2023

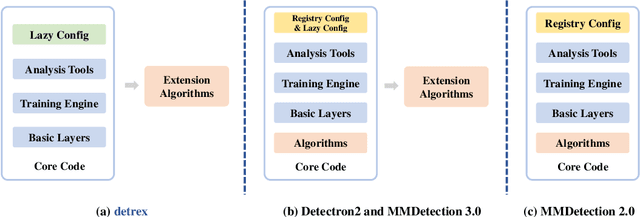
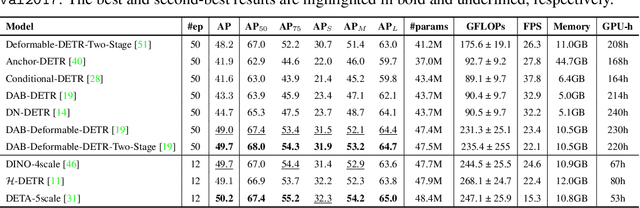
The DEtection TRansformer (DETR) algorithm has received considerable attention in the research community and is gradually emerging as a mainstream approach for object detection and other perception tasks. However, the current field lacks a unified and comprehensive benchmark specifically tailored for DETR-based models. To address this issue, we develop a unified, highly modular, and lightweight codebase called detrex, which supports a majority of the mainstream DETR-based instance recognition algorithms, covering various fundamental tasks, including object detection, segmentation, and pose estimation. We conduct extensive experiments under detrex and perform a comprehensive benchmark for DETR-based models. Moreover, we enhance the performance of detection transformers through the refinement of training hyper-parameters, providing strong baselines for supported algorithms.We hope that detrex could offer research communities a standardized and unified platform to evaluate and compare different DETR-based models while fostering a deeper understanding and driving advancements in DETR-based instance recognition. Our code is available at https://github.com/IDEA-Research/detrex. The project is currently being actively developed. We encourage the community to use detrex codebase for further development and contributions.
DreamWaltz: Make a Scene with Complex 3D Animatable Avatars
May 21, 2023
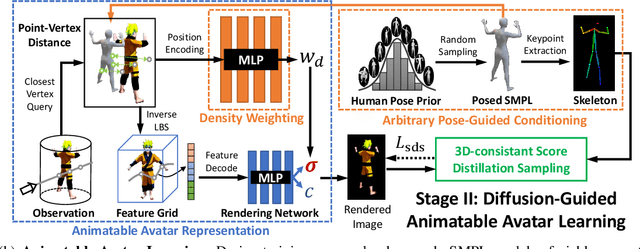

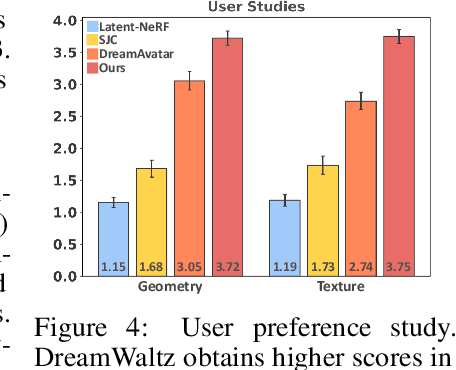
We present DreamWaltz, a novel framework for generating and animating complex avatars given text guidance and parametric human body prior. While recent methods have shown encouraging results in the text-to-3D generation of common objects, creating high-quality and animatable 3D avatars remains challenging. To create high-quality 3D avatars, DreamWaltz proposes 3D-consistent occlusion-aware Score Distillation Sampling (SDS) to optimize implicit neural representations with canonical poses. It provides view-aligned supervision via 3D-aware skeleton conditioning and enables complex avatar generation without artifacts and multiple faces. For animation, our method learns an animatable and generalizable avatar representation which could map arbitrary poses to the canonical pose representation. Extensive evaluations demonstrate that DreamWaltz is an effective and robust approach for creating 3D avatars that can take on complex shapes and appearances as well as novel poses for animation. The proposed framework further enables the creation of complex scenes with diverse compositions, including avatar-avatar, avatar-object and avatar-scene interactions.
Inducing Neural Collapse in Deep Long-tailed Learning
Feb 24, 2023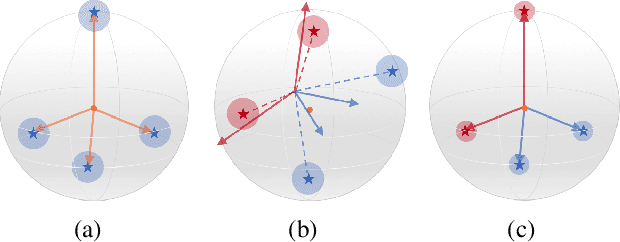

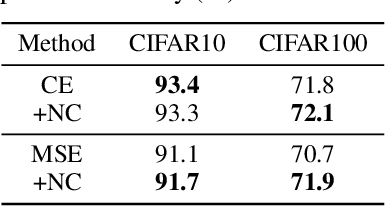
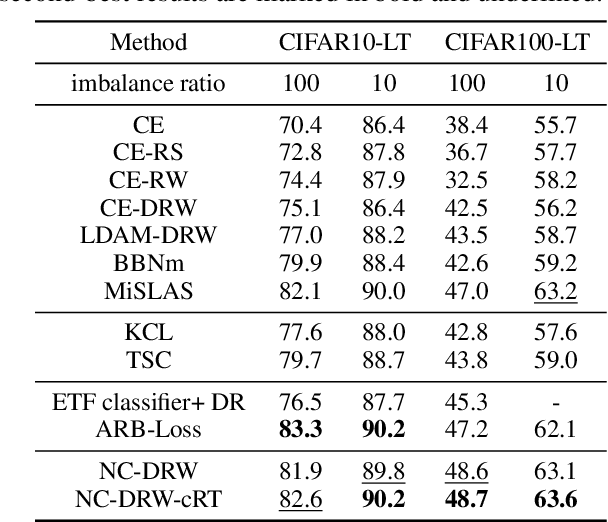
Although deep neural networks achieve tremendous success on various classification tasks, the generalization ability drops sheer when training datasets exhibit long-tailed distributions. One of the reasons is that the learned representations (i.e. features) from the imbalanced datasets are less effective than those from balanced datasets. Specifically, the learned representation under class-balanced distribution will present the Neural Collapse (NC) phenomena. NC indicates the features from the same category are close to each other and from different categories are maximally distant, showing an optimal linear separable state of classification. However, the pattern differs on imbalanced datasets and is partially responsible for the reduced performance of the model. In this work, we propose two explicit feature regularization terms to learn high-quality representation for class-imbalanced data. With the proposed regularization, NC phenomena will appear under the class-imbalanced distribution, and the generalization ability can be significantly improved. Our method is easily implemented, highly effective, and can be plugged into most existing methods. The extensive experimental results on widely-used benchmarks show the effectiveness of our method
Exploring Vision Transformers as Diffusion Learners
Dec 28, 2022
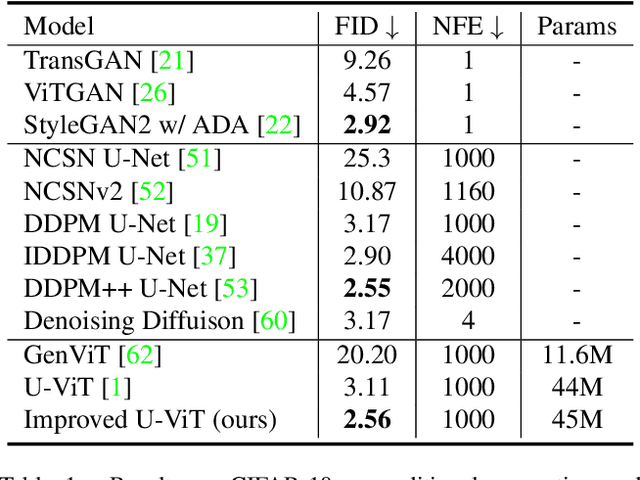

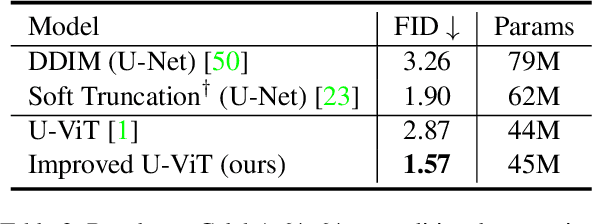
Score-based diffusion models have captured widespread attention and funded fast progress of recent vision generative tasks. In this paper, we focus on diffusion model backbone which has been much neglected before. We systematically explore vision Transformers as diffusion learners for various generative tasks. With our improvements the performance of vanilla ViT-based backbone (IU-ViT) is boosted to be on par with traditional U-Net-based methods. We further provide a hypothesis on the implication of disentangling the generative backbone as an encoder-decoder structure and show proof-of-concept experiments verifying the effectiveness of a stronger encoder for generative tasks with ASymmetriC ENcoder Decoder (ASCEND). Our improvements achieve competitive results on CIFAR-10, CelebA, LSUN, CUB Bird and large-resolution text-to-image tasks. To the best of our knowledge, we are the first to successfully train a single diffusion model on text-to-image task beyond 64x64 resolution. We hope this will motivate people to rethink the modeling choices and the training pipelines for diffusion-based generative models.