 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChetan Arora
The Third Monocular Depth Estimation Challenge
Apr 27, 2024
This paper discusses the results of the third edition of the Monocular Depth Estimation Challenge (MDEC). The challenge focuses on zero-shot generalization to the challenging SYNS-Patches dataset, featuring complex scenes in natural and indoor settings. As with the previous edition, methods can use any form of supervision, i.e. supervised or self-supervised. The challenge received a total of 19 submissions outperforming the baseline on the test set: 10 among them submitted a report describing their approach, highlighting a diffused use of foundational models such as Depth Anything at the core of their method. The challenge winners drastically improved 3D F-Score performance, from 17.51% to 23.72%.
Model Generation from Requirements with LLMs: an Exploratory Study
Apr 09, 2024Complementing natural language (NL) requirements with graphical models can improve stakeholders' communication and provide directions for system design. However, creating models from requirements involves manual effort. The advent of generative large language models (LLMs), ChatGPT being a notable example, offers promising avenues for automated assistance in model generation. This paper investigates the capability of ChatGPT to generate a specific type of model, i.e., UML sequence diagrams, from NL requirements. We conduct a qualitative study in which we examine the sequence diagrams generated by ChatGPT for 28 requirements documents of various types and from different domains. Observations from the analysis of the generated diagrams have systematically been captured through evaluation logs, and categorized through thematic analysis. Our results indicate that, although the models generally conform to the standard and exhibit a reasonable level of understandability, their completeness and correctness with respect to the specified requirements often present challenges. This issue is particularly pronounced in the presence of requirements smells, such as ambiguity and inconsistency. The insights derived from this study can influence the practical utilization of LLMs in the RE process, and open the door to novel RE-specific prompting strategies targeting effective model generation.
ECoDepth: Effective Conditioning of Diffusion Models for Monocular Depth Estimation
Apr 01, 2024
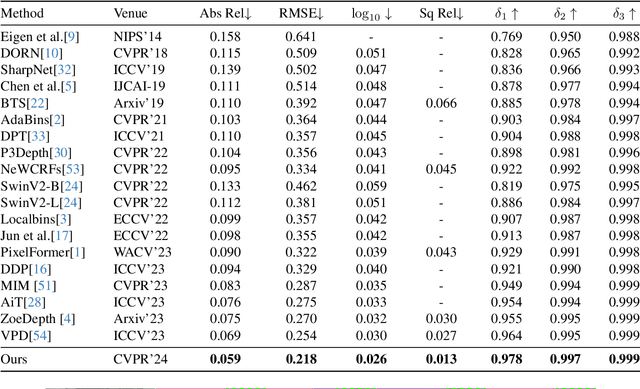
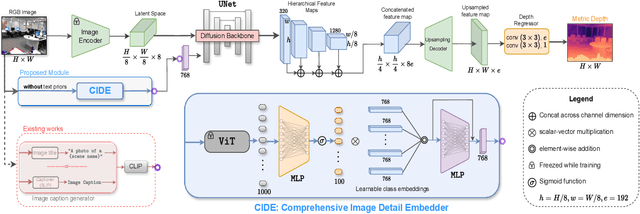
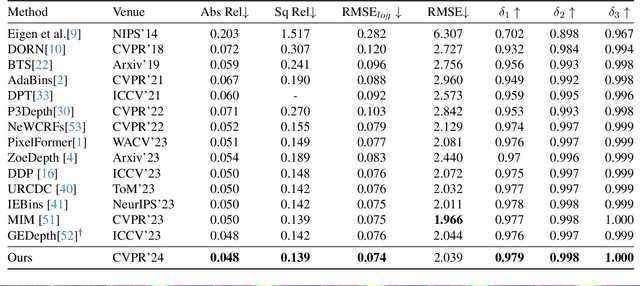
In the absence of parallax cues, a learning-based single image depth estimation (SIDE) model relies heavily on shading and contextual cues in the image. While this simplicity is attractive, it is necessary to train such models on large and varied datasets, which are difficult to capture. It has been shown that using embeddings from pre-trained foundational models, such as CLIP, improves zero shot transfer in several applications. Taking inspiration from this, in our paper we explore the use of global image priors generated from a pre-trained ViT model to provide more detailed contextual information. We argue that the embedding vector from a ViT model, pre-trained on a large dataset, captures greater relevant information for SIDE than the usual route of generating pseudo image captions, followed by CLIP based text embeddings. Based on this idea, we propose a new SIDE model using a diffusion backbone which is conditioned on ViT embeddings. Our proposed design establishes a new state-of-the-art (SOTA) for SIDE on NYUv2 dataset, achieving Abs Rel error of 0.059(14% improvement) compared to 0.069 by the current SOTA (VPD). And on KITTI dataset, achieving Sq Rel error of 0.139 (2% improvement) compared to 0.142 by the current SOTA (GEDepth). For zero-shot transfer with a model trained on NYUv2, we report mean relative improvement of (20%, 23%, 81%, 25%) over NeWCRFs on (Sun-RGBD, iBims1, DIODE, HyperSim) datasets, compared to (16%, 18%, 45%, 9%) by ZoeDepth. The project page is available at https://ecodepth-iitd.github.io
FocusMAE: Gallbladder Cancer Detection from Ultrasound Videos with Focused Masked Autoencoders
Mar 29, 2024
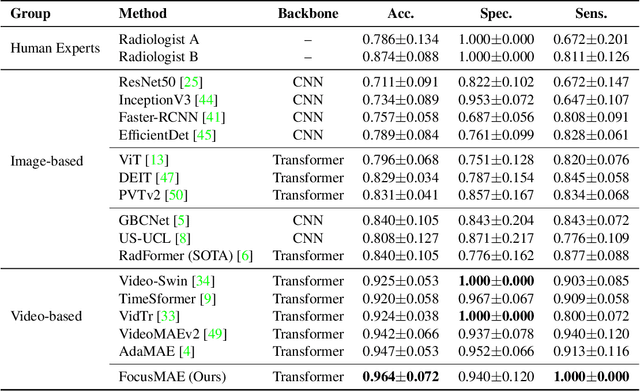
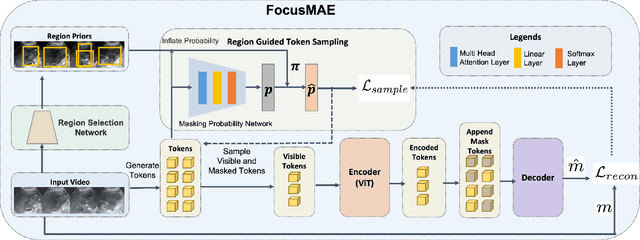
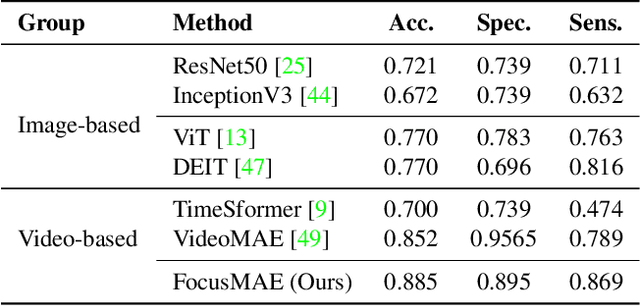
In recent years, automated Gallbladder Cancer (GBC) detection has gained the attention of researchers. Current state-of-the-art (SOTA) methodologies relying on ultrasound sonography (US) images exhibit limited generalization, emphasizing the need for transformative approaches. We observe that individual US frames may lack sufficient information to capture disease manifestation. This study advocates for a paradigm shift towards video-based GBC detection, leveraging the inherent advantages of spatiotemporal representations. Employing the Masked Autoencoder (MAE) for representation learning, we address shortcomings in conventional image-based methods. We propose a novel design called FocusMAE to systematically bias the selection of masking tokens from high-information regions, fostering a more refined representation of malignancy. Additionally, we contribute the most extensive US video dataset for GBC detection. We also note that, this is the first study on US video-based GBC detection. We validate the proposed methods on the curated dataset, and report a new state-of-the-art (SOTA) accuracy of 96.4% for the GBC detection problem, against an accuracy of 84% by current Image-based SOTA - GBCNet, and RadFormer, and 94.7% by Video-based SOTA - AdaMAE. We further demonstrate the generality of the proposed FocusMAE on a public CT-based Covid detection dataset, reporting an improvement in accuracy by 3.3% over current baselines. The source code and pretrained models are available at: https://gbc-iitd.github.io/focusmae
A Study of Fairness Concerns in AI-based Mobile App Reviews
Jan 16, 2024With the growing application of AI-based systems in our lives and society, there is a rising need to ensure that AI-based systems are developed and used in a responsible way. Fairness is one of the socio-technical concerns that must be addressed in AI-based systems for this purpose. Unfair AI-based systems, particularly, unfair AI-based mobile apps, can pose difficulties for a significant proportion of the global populace. This paper aims to deeply analyze fairness concerns in AI-based app reviews. We first manually constructed a ground-truth dataset including a statistical sample of fairness and non-fairness reviews. Leveraging the ground-truth dataset, we then developed and evaluated a set of machine learning and deep learning classifiers that distinguish fairness reviews from non-fairness reviews. Our experiments show that our best-performing classifier can detect fairness reviews with a precision of 94%. We then applied the best-performing classifier on approximately 9.5M reviews collected from 108 AI-based apps and identified around 92K fairness reviews. While the fairness reviews appear in 23 app categories, we found that the 'communication' and 'social' app categories have the highest percentage of fairness reviews. Next, applying the K-means clustering technique to the 92K fairness reviews, followed by manual analysis, led to the identification of six distinct types of fairness concerns (e.g., 'receiving different quality of features and services in different platforms and devices' and 'lack of transparency and fairness in dealing with user-generated content'). Finally, the manual analysis of 2,248 app owners' responses to the fairness reviews identified six root causes (e.g., 'copyright issues', 'external factors', 'development cost') that app owners report to justify fairness concerns.
Army of Thieves: Enhancing Black-Box Model Extraction via Ensemble based sample selection
Nov 08, 2023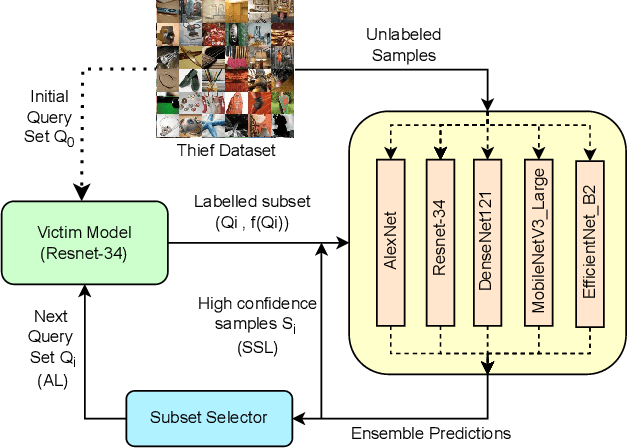
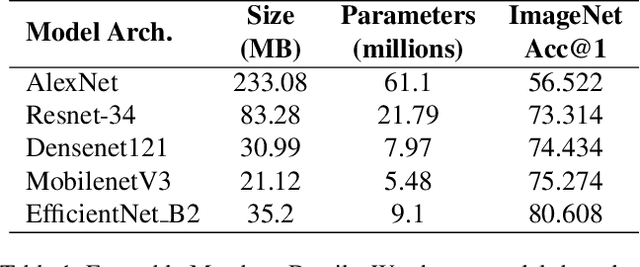

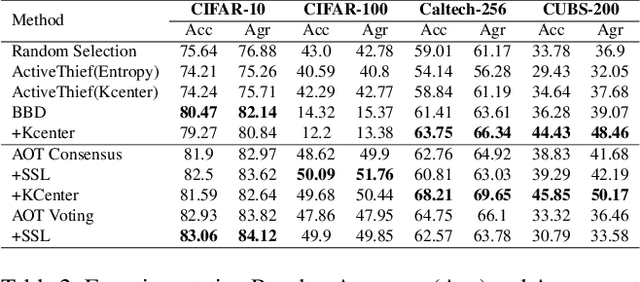
Machine Learning (ML) models become vulnerable to Model Stealing Attacks (MSA) when they are deployed as a service. In such attacks, the deployed model is queried repeatedly to build a labelled dataset. This dataset allows the attacker to train a thief model that mimics the original model. To maximize query efficiency, the attacker has to select the most informative subset of data points from the pool of available data. Existing attack strategies utilize approaches like Active Learning and Semi-Supervised learning to minimize costs. However, in the black-box setting, these approaches may select sub-optimal samples as they train only one thief model. Depending on the thief model's capacity and the data it was pretrained on, the model might even select noisy samples that harm the learning process. In this work, we explore the usage of an ensemble of deep learning models as our thief model. We call our attack Army of Thieves(AOT) as we train multiple models with varying complexities to leverage the crowd's wisdom. Based on the ensemble's collective decision, uncertain samples are selected for querying, while the most confident samples are directly included in the training data. Our approach is the first one to utilize an ensemble of thief models to perform model extraction. We outperform the base approaches of existing state-of-the-art methods by at least 3% and achieve a 21% higher adversarial sample transferability than previous work for models trained on the CIFAR-10 dataset.
United We Stand, Divided We Fall: UnityGraph for Unsupervised Procedure Learning from Videos
Nov 06, 2023Given multiple videos of the same task, procedure learning addresses identifying the key-steps and determining their order to perform the task. For this purpose, existing approaches use the signal generated from a pair of videos. This makes key-steps discovery challenging as the algorithms lack inter-videos perspective. Instead, we propose an unsupervised Graph-based Procedure Learning (GPL) framework. GPL consists of the novel UnityGraph that represents all the videos of a task as a graph to obtain both intra-video and inter-videos context. Further, to obtain similar embeddings for the same key-steps, the embeddings of UnityGraph are updated in an unsupervised manner using the Node2Vec algorithm. Finally, to identify the key-steps, we cluster the embeddings using KMeans. We test GPL on benchmark ProceL, CrossTask, and EgoProceL datasets and achieve an average improvement of 2% on third-person datasets and 3.6% on EgoProceL over the state-of-the-art.
Model-driven Engineering for Machine Learning Components: A Systematic Literature Review
Nov 01, 2023Context: Machine Learning (ML) has become widely adopted as a component in many modern software applications. Due to the large volumes of data available, organizations want to increasingly leverage their data to extract meaningful insights and enhance business profitability. ML components enable predictive capabilities, anomaly detection, recommendation, accurate image and text processing, and informed decision-making. However, developing systems with ML components is not trivial; it requires time, effort, knowledge, and expertise in ML, data processing, and software engineering. There have been several studies on the use of model-driven engineering (MDE) techniques to address these challenges when developing traditional software and cyber-physical systems. Recently, there has been a growing interest in applying MDE for systems with ML components. Objective: The goal of this study is to further explore the promising intersection of MDE with ML (MDE4ML) through a systematic literature review (SLR). Through this SLR, we wanted to analyze existing studies, including their motivations, MDE solutions, evaluation techniques, key benefits and limitations. Results: We analyzed selected studies with respect to several areas of interest and identified the following: 1) the key motivations behind using MDE4ML; 2) a variety of MDE solutions applied, such as modeling languages, model transformations, tool support, targeted ML aspects, contributions and more; 3) the evaluation techniques and metrics used; and 4) the limitations and directions for future work. We also discuss the gaps in existing literature and provide recommendations for future research. Conclusion: This SLR highlights current trends, gaps and future research directions in the field of MDE4ML, benefiting both researchers and practitioners
Gall Bladder Cancer Detection from US Images with Only Image Level Labels
Sep 11, 2023
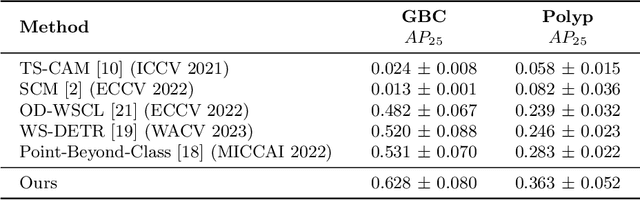


Automated detection of Gallbladder Cancer (GBC) from Ultrasound (US) images is an important problem, which has drawn increased interest from researchers. However, most of these works use difficult-to-acquire information such as bounding box annotations or additional US videos. In this paper, we focus on GBC detection using only image-level labels. Such annotation is usually available based on the diagnostic report of a patient, and do not require additional annotation effort from the physicians. However, our analysis reveals that it is difficult to train a standard image classification model for GBC detection. This is due to the low inter-class variance (a malignant region usually occupies only a small portion of a US image), high intra-class variance (due to the US sensor capturing a 2D slice of a 3D object leading to large viewpoint variations), and low training data availability. We posit that even when we have only the image level label, still formulating the problem as object detection (with bounding box output) helps a deep neural network (DNN) model focus on the relevant region of interest. Since no bounding box annotations is available for training, we pose the problem as weakly supervised object detection (WSOD). Motivated by the recent success of transformer models in object detection, we train one such model, DETR, using multi-instance-learning (MIL) with self-supervised instance selection to suit the WSOD task. Our proposed method demonstrates an improvement of AP and detection sensitivity over the SOTA transformer-based and CNN-based WSOD methods. Project page is at https://gbc-iitd.github.io/wsod-gbc
UTRNet: High-Resolution Urdu Text Recognition In Printed Documents
Jul 06, 2023

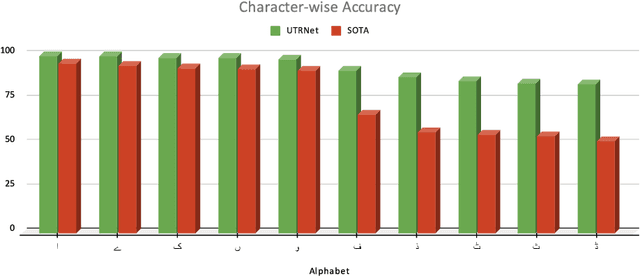
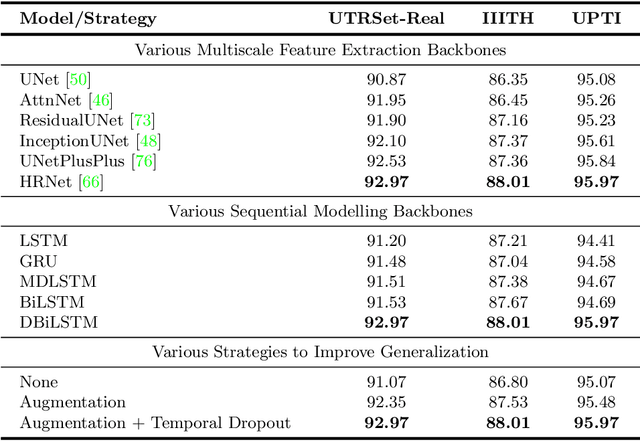
In this paper, we propose a novel approach to address the challenges of printed Urdu text recognition using high-resolution, multi-scale semantic feature extraction. Our proposed UTRNet architecture, a hybrid CNN-RNN model, demonstrates state-of-the-art performance on benchmark datasets. To address the limitations of previous works, which struggle to generalize to the intricacies of the Urdu script and the lack of sufficient annotated real-world data, we have introduced the UTRSet-Real, a large-scale annotated real-world dataset comprising over 11,000 lines and UTRSet-Synth, a synthetic dataset with 20,000 lines closely resembling real-world and made corrections to the ground truth of the existing IIITH dataset, making it a more reliable resource for future research. We also provide UrduDoc, a benchmark dataset for Urdu text line detection in scanned documents. Additionally, we have developed an online tool for end-to-end Urdu OCR from printed documents by integrating UTRNet with a text detection model. Our work not only addresses the current limitations of Urdu OCR but also paves the way for future research in this area and facilitates the continued advancement of Urdu OCR technology. The project page with source code, datasets, annotations, trained models, and online tool is available at abdur75648.github.io/UTRNet.