 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHua Wei
X-Light: Cross-City Traffic Signal Control Using Transformer on Transformer as Meta Multi-Agent Reinforcement Learner
Apr 18, 2024
The effectiveness of traffic light control has been significantly improved by current reinforcement learning-based approaches via better cooperation among multiple traffic lights. However, a persisting issue remains: how to obtain a multi-agent traffic signal control algorithm with remarkable transferability across diverse cities? In this paper, we propose a Transformer on Transformer (TonT) model for cross-city meta multi-agent traffic signal control, named as X-Light: We input the full Markov Decision Process trajectories, and the Lower Transformer aggregates the states, actions, rewards among the target intersection and its neighbors within a city, and the Upper Transformer learns the general decision trajectories across different cities. This dual-level approach bolsters the model's robust generalization and transferability. Notably, when directly transferring to unseen scenarios, ours surpasses all baseline methods with +7.91% on average, and even +16.3% in some cases, yielding the best results.
SEVD: Synthetic Event-based Vision Dataset for Ego and Fixed Traffic Perception
Apr 12, 2024Recently, event-based vision sensors have gained attention for autonomous driving applications, as conventional RGB cameras face limitations in handling challenging dynamic conditions. However, the availability of real-world and synthetic event-based vision datasets remains limited. In response to this gap, we present SEVD, a first-of-its-kind multi-view ego, and fixed perception synthetic event-based dataset using multiple dynamic vision sensors within the CARLA simulator. Data sequences are recorded across diverse lighting (noon, nighttime, twilight) and weather conditions (clear, cloudy, wet, rainy, foggy) with domain shifts (discrete and continuous). SEVD spans urban, suburban, rural, and highway scenes featuring various classes of objects (car, truck, van, bicycle, motorcycle, and pedestrian). Alongside event data, SEVD includes RGB imagery, depth maps, optical flow, semantic, and instance segmentation, facilitating a comprehensive understanding of the scene. Furthermore, we evaluate the dataset using state-of-the-art event-based (RED, RVT) and frame-based (YOLOv8) methods for traffic participant detection tasks and provide baseline benchmarks for assessment. Additionally, we conduct experiments to assess the synthetic event-based dataset's generalization capabilities. The dataset is available at https://eventbasedvision.github.io/SEVD
eTraM: Event-based Traffic Monitoring Dataset
Apr 02, 2024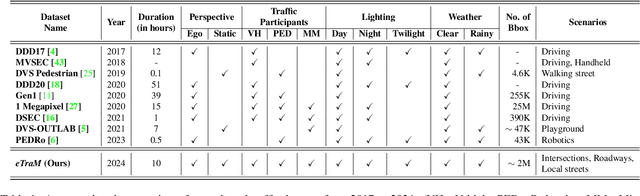
Event cameras, with their high temporal and dynamic range and minimal memory usage, have found applications in various fields. However, their potential in static traffic monitoring remains largely unexplored. To facilitate this exploration, we present eTraM - a first-of-its-kind, fully event-based traffic monitoring dataset. eTraM offers 10 hr of data from different traffic scenarios in various lighting and weather conditions, providing a comprehensive overview of real-world situations. Providing 2M bounding box annotations, it covers eight distinct classes of traffic participants, ranging from vehicles to pedestrians and micro-mobility. eTraM's utility has been assessed using state-of-the-art methods for traffic participant detection, including RVT, RED, and YOLOv8. We quantitatively evaluate the ability of event-based models to generalize on nighttime and unseen scenes. Our findings substantiate the compelling potential of leveraging event cameras for traffic monitoring, opening new avenues for research and application. eTraM is available at https://eventbasedvision.github.io/eTraM
Are Classification Robustness and Explanation Robustness Really Strongly Correlated? An Analysis Through Input Loss Landscape
Mar 09, 2024
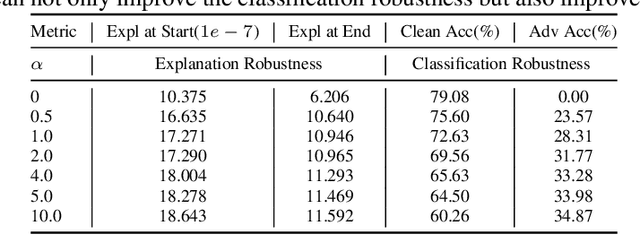
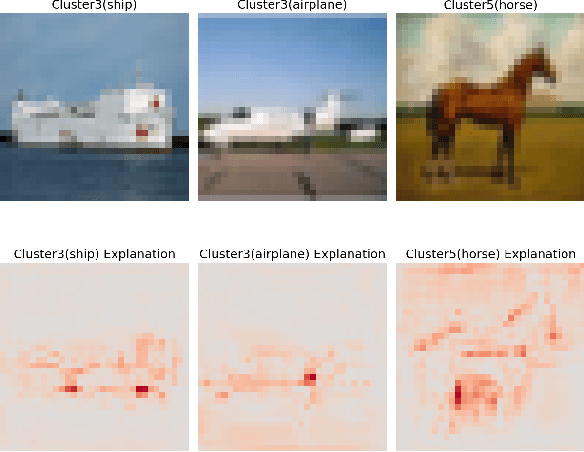
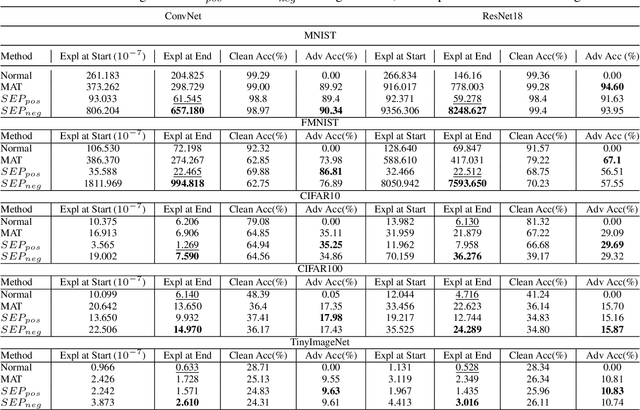
This paper delves into the critical area of deep learning robustness, challenging the conventional belief that classification robustness and explanation robustness in image classification systems are inherently correlated. Through a novel evaluation approach leveraging clustering for efficient assessment of explanation robustness, we demonstrate that enhancing explanation robustness does not necessarily flatten the input loss landscape with respect to explanation loss - contrary to flattened loss landscapes indicating better classification robustness. To deeply investigate this contradiction, a groundbreaking training method designed to adjust the loss landscape with respect to explanation loss is proposed. Through the new training method, we uncover that although such adjustments can impact the robustness of explanations, they do not have an influence on the robustness of classification. These findings not only challenge the prevailing assumption of a strong correlation between the two forms of robustness but also pave new pathways for understanding relationship between loss landscape and explanation loss.
Privacy-preserving Fine-tuning of Large Language Models through Flatness
Mar 07, 2024
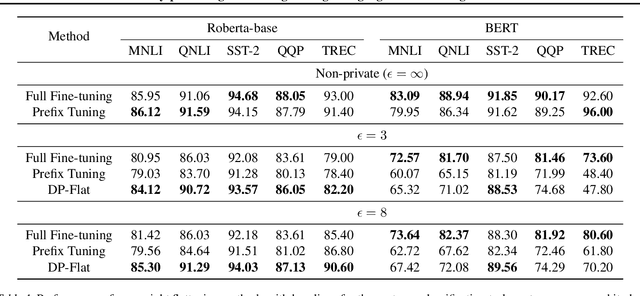
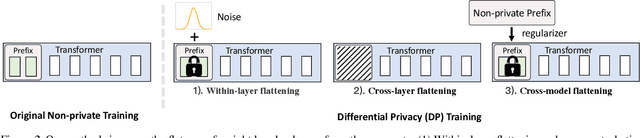
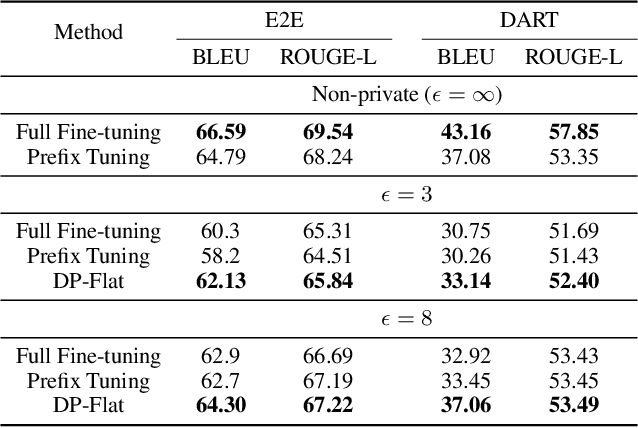
The privacy concerns associated with the use of Large Language Models (LLMs) have grown recently with the development of LLMs such as ChatGPT. Differential Privacy (DP) techniques are explored in existing work to mitigate their privacy risks at the cost of generalization degradation. Our paper reveals that the flatness of DP-trained models' loss landscape plays an essential role in the trade-off between their privacy and generalization. We further propose a holistic framework to enforce appropriate weight flatness, which substantially improves model generalization with competitive privacy preservation. It innovates from three coarse-to-grained levels, including perturbation-aware min-max optimization on model weights within a layer, flatness-guided sparse prefix-tuning on weights across layers, and weight knowledge distillation between DP \& non-DP weights copies. Comprehensive experiments of both black-box and white-box scenarios are conducted to demonstrate the effectiveness of our proposal in enhancing generalization and maintaining DP characteristics. For instance, on text classification dataset QNLI, DP-Flat achieves similar performance with non-private full fine-tuning but with DP guarantee under privacy budget $\epsilon=3$, and even better performance given higher privacy budgets. Codes are provided in the supplement.
Teaching MLP More Graph Information: A Three-stage Multitask Knowledge Distillation Framework
Mar 02, 2024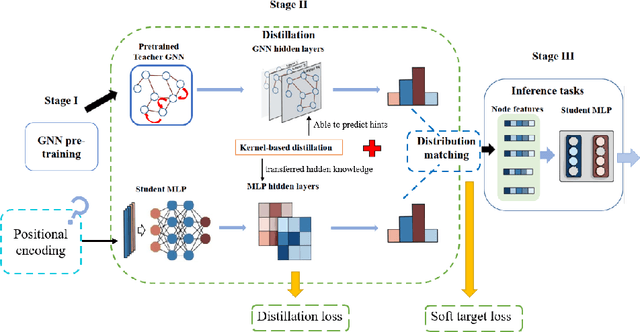
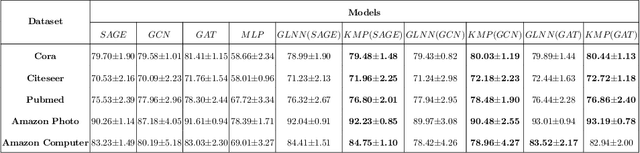
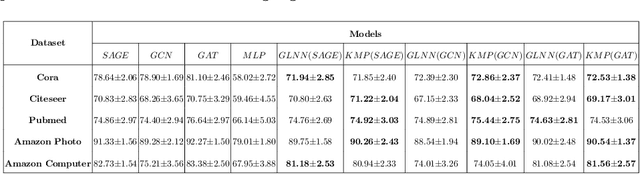
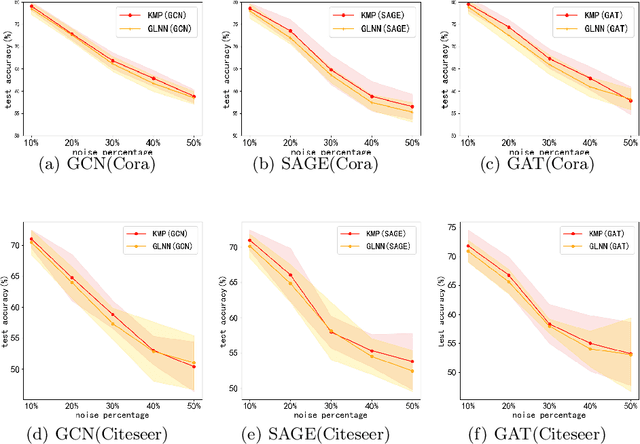
We study the challenging problem for inference tasks on large-scale graph datasets of Graph Neural Networks: huge time and memory consumption, and try to overcome it by reducing reliance on graph structure. Even though distilling graph knowledge to student MLP is an excellent idea, it faces two major problems of positional information loss and low generalization. To solve the problems, we propose a new three-stage multitask distillation framework. In detail, we use Positional Encoding to capture positional information. Also, we introduce Neural Heat Kernels responsible for graph data processing in GNN and utilize hidden layer outputs matching for better performance of student MLP's hidden layers. To the best of our knowledge, it is the first work to include hidden layer distillation for student MLP on graphs and to combine graph Positional Encoding with MLP. We test its performance and robustness with several settings and draw the conclusion that our work can outperform well with good stability.
CityFlowER: An Efficient and Realistic Traffic Simulator with Embedded Machine Learning Models
Feb 09, 2024Traffic simulation is an essential tool for transportation infrastructure planning, intelligent traffic control policy learning, and traffic flow analysis. Its effectiveness relies heavily on the realism of the simulators used. Traditional traffic simulators, such as SUMO and CityFlow, are often limited by their reliance on rule-based models with hyperparameters that oversimplify driving behaviors, resulting in unrealistic simulations. To enhance realism, some simulators have provided Application Programming Interfaces (APIs) to interact with Machine Learning (ML) models, which learn from observed data and offer more sophisticated driving behavior models. However, this approach faces challenges in scalability and time efficiency as vehicle numbers increase. Addressing these limitations, we introduce CityFlowER, an advancement over the existing CityFlow simulator, designed for efficient and realistic city-wide traffic simulation. CityFlowER innovatively pre-embeds ML models within the simulator, eliminating the need for external API interactions and enabling faster data computation. This approach allows for a blend of rule-based and ML behavior models for individual vehicles, offering unparalleled flexibility and efficiency, particularly in large-scale simulations. We provide detailed comparisons with existing simulators, implementation insights, and comprehensive experiments to demonstrate CityFlowER's superiority in terms of realism, efficiency, and adaptability.
Interpreting Graph Neural Networks with In-Distributed Proxies
Feb 03, 2024Graph Neural Networks (GNNs) have become a building block in graph data processing, with wide applications in critical domains. The growing needs to deploy GNNs in high-stakes applications necessitate explainability for users in the decision-making processes. A popular paradigm for the explainability of GNNs is to identify explainable subgraphs by comparing their labels with the ones of original graphs. This task is challenging due to the substantial distributional shift from the original graphs in the training set to the set of explainable subgraphs, which prevents accurate prediction of labels with the subgraphs. To address it, in this paper, we propose a novel method that generates proxy graphs for explainable subgraphs that are in the distribution of training data. We introduce a parametric method that employs graph generators to produce proxy graphs. A new training objective based on information theory is designed to ensure that proxy graphs not only adhere to the distribution of training data but also preserve essential explanatory factors. Such generated proxy graphs can be reliably used for approximating the predictions of the true labels of explainable subgraphs. Empirical evaluations across various datasets demonstrate our method achieves more accurate explanations for GNNs.
When eBPF Meets Machine Learning: On-the-fly OS Kernel Compartmentalization
Jan 11, 2024Compartmentalization effectively prevents initial corruption from turning into a successful attack. This paper presents O2C, a pioneering system designed to enforce OS kernel compartmentalization on the fly. It not only provides immediate remediation for sudden threats but also maintains consistent system availability through the enforcement process. O2C is empowered by the newest advancements of the eBPF ecosystem which allows to instrument eBPF programs that perform enforcement actions into the kernel at runtime. O2C takes the lead in embedding a machine learning model into eBPF programs, addressing unique challenges in on-the-fly compartmentalization. Our comprehensive evaluation shows that O2C effectively confines damage within the compartment. Further, we validate that decision tree is optimally suited for O2C owing to its advantages in processing tabular data, its explainable nature, and its compliance with the eBPF ecosystem. Last but not least, O2C is lightweight, showing negligible overhead and excellent sacalability system-wide.
Uncertainty Regularized Evidential Regression
Jan 03, 2024The Evidential Regression Network (ERN) represents a novel approach that integrates deep learning with Dempster-Shafer's theory to predict a target and quantify the associated uncertainty. Guided by the underlying theory, specific activation functions must be employed to enforce non-negative values, which is a constraint that compromises model performance by limiting its ability to learn from all samples. This paper provides a theoretical analysis of this limitation and introduces an improvement to overcome it. Initially, we define the region where the models can't effectively learn from the samples. Following this, we thoroughly analyze the ERN and investigate this constraint. Leveraging the insights from our analysis, we address the limitation by introducing a novel regularization term that empowers the ERN to learn from the whole training set. Our extensive experiments substantiate our theoretical findings and demonstrate the effectiveness of the proposed solution.