 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSun Yang
PET-SQL: A Prompt-enhanced Two-stage Text-to-SQL Framework with Cross-consistency
Mar 18, 2024
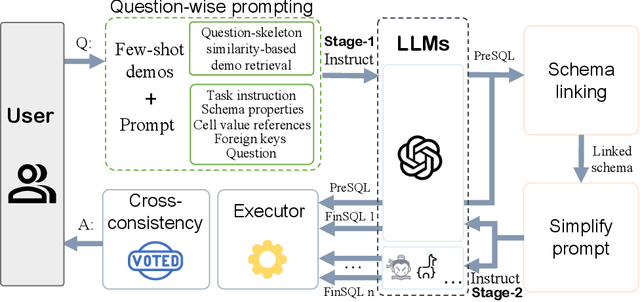

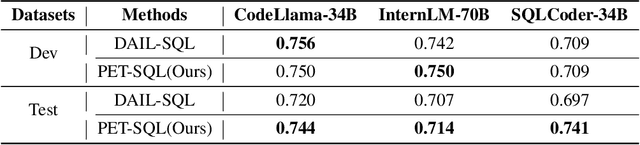
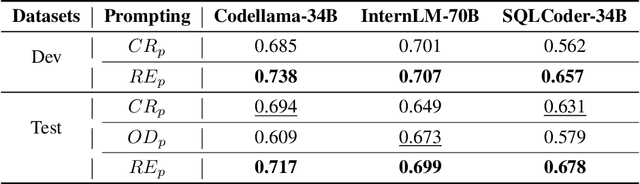
Recent advancements in Text-to-SQL (Text2SQL) emphasize stimulating the large language models (LLM) on in-context learning, achieving significant results. Nevertheless, they face challenges when dealing with verbose database information and complex user intentions. This paper presents a two-stage framework to enhance the performance of current LLM-based natural language to SQL systems. We first introduce a novel prompt representation, called reference-enhanced representation, which includes schema information and randomly sampled cell values from tables to instruct LLMs in generating SQL queries. Then, in the first stage, question-SQL pairs are retrieved as few-shot demonstrations, prompting the LLM to generate a preliminary SQL (PreSQL). After that, the mentioned entities in PreSQL are parsed to conduct schema linking, which can significantly compact the useful information. In the second stage, with the linked schema, we simplify the prompt's schema information and instruct the LLM to produce the final SQL. Finally, as the post-refinement module, we propose using cross-consistency across different LLMs rather than self-consistency within a particular LLM. Our methods achieve new SOTA results on the Spider benchmark, with an execution accuracy of 87.6%.
Benchmarking the Text-to-SQL Capability of Large Language Models: A Comprehensive Evaluation
Mar 06, 2024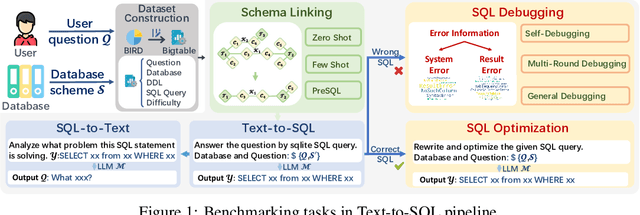

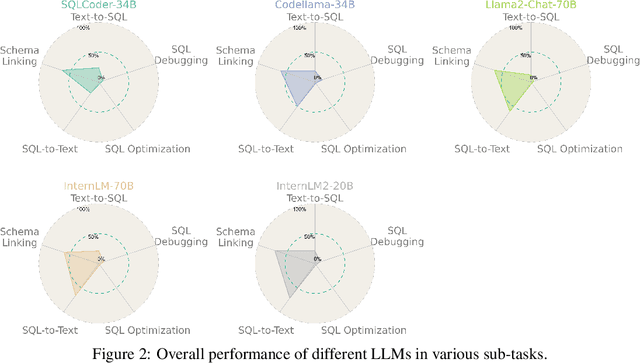

Large Language Models (LLMs) have emerged as a powerful tool in advancing the Text-to-SQL task, significantly outperforming traditional methods. Nevertheless, as a nascent research field, there is still no consensus on the optimal prompt templates and design frameworks. Additionally, existing benchmarks inadequately explore the performance of LLMs across the various sub-tasks of the Text-to-SQL process, which hinders the assessment of LLMs' cognitive capabilities and the optimization of LLM-based solutions. To address the aforementioned issues, we firstly construct a new dataset designed to mitigate the risk of overfitting in LLMs. Then we formulate five evaluation tasks to comprehensively assess the performance of diverse methods across various LLMs throughout the Text-to-SQL process.Our study highlights the performance disparities among LLMs and proposes optimal in-context learning solutions tailored to each task. These findings offer valuable insights for enhancing the development of LLM-based Text-to-SQL systems.
Spatial-Temporal Large Language Model for Traffic Prediction
Jan 23, 2024Traffic prediction, a critical component for intelligent transportation systems, endeavors to foresee future traffic at specific locations using historical data. Although existing traffic prediction models often emphasize developing complex neural network structures, their accuracy has not seen improvements accordingly. Recently, Large Language Models (LLMs) have shown outstanding capabilities in time series analysis. Differing from existing models, LLMs progress mainly through parameter expansion and extensive pre-training while maintaining their fundamental structures. In this paper, we propose a Spatial-Temporal Large Language Model (ST-LLM) for traffic prediction. Specifically, ST-LLM redefines the timesteps at each location as tokens and incorporates a spatial-temporal embedding module to learn the spatial location and global temporal representations of tokens. Then these representations are fused to provide each token with unified spatial and temporal information. Furthermore, we propose a novel partially frozen attention strategy of the LLM, which is designed to capture spatial-temporal dependencies for traffic prediction. Comprehensive experiments on real traffic datasets offer evidence that ST-LLM outperforms state-of-the-art models. Notably, the ST-LLM also exhibits robust performance in both few-shot and zero-shot prediction scenarios.
Reboost Large Language Model-based Text-to-SQL, Text-to-Python, and Text-to-Function -- with Real Applications in Traffic Domain
Oct 31, 2023The previous state-of-the-art (SOTA) method achieved a remarkable execution accuracy on the Spider dataset, which is one of the largest and most diverse datasets in the Text-to-SQL domain. However, during our reproduction of the business dataset, we observed a significant drop in performance. We examined the differences in dataset complexity, as well as the clarity of questions' intentions, and assessed how those differences could impact the performance of prompting methods. Subsequently, We develop a more adaptable and more general prompting method, involving mainly query rewriting and SQL boosting, which respectively transform vague information into exact and precise information and enhance the SQL itself by incorporating execution feedback and the query results from the database content. In order to prevent information gaps, we include the comments, value types, and value samples for columns as part of the database description in the prompt. Our experiments with Large Language Models (LLMs) illustrate the significant performance improvement on the business dataset and prove the substantial potential of our method. In terms of execution accuracy on the business dataset, the SOTA method scored 21.05, while our approach scored 65.79. As a result, our approach achieved a notable performance improvement even when using a less capable pre-trained language model. Last but not least, we also explore the Text-to-Python and Text-to-Function options, and we deeply analyze the pros and cons among them, offering valuable insights to the community.