 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinghao Chen
Pseudo Label Refinery for Unsupervised Domain Adaptation on Cross-dataset 3D Object Detection
Apr 30, 2024
Recent self-training techniques have shown notable improvements in unsupervised domain adaptation for 3D object detection (3D UDA). These techniques typically select pseudo labels, i.e., 3D boxes, to supervise models for the target domain. However, this selection process inevitably introduces unreliable 3D boxes, in which 3D points cannot be definitively assigned as foreground or background. Previous techniques mitigate this by reweighting these boxes as pseudo labels, but these boxes can still poison the training process. To resolve this problem, in this paper, we propose a novel pseudo label refinery framework. Specifically, in the selection process, to improve the reliability of pseudo boxes, we propose a complementary augmentation strategy. This strategy involves either removing all points within an unreliable box or replacing it with a high-confidence box. Moreover, the point numbers of instances in high-beam datasets are considerably higher than those in low-beam datasets, also degrading the quality of pseudo labels during the training process. We alleviate this issue by generating additional proposals and aligning RoI features across different domains. Experimental results demonstrate that our method effectively enhances the quality of pseudo labels and consistently surpasses the state-of-the-art methods on six autonomous driving benchmarks. Code will be available at https://github.com/Zhanwei-Z/PERE.
G2LTraj: A Global-to-Local Generation Approach for Trajectory Prediction
Apr 30, 2024Predicting future trajectories of traffic agents accurately holds substantial importance in various applications such as autonomous driving. Previous methods commonly infer all future steps of an agent either recursively or simultaneously. However, the recursive strategy suffers from the accumulated error, while the simultaneous strategy overlooks the constraints among future steps, resulting in kinematically infeasible predictions. To address these issues, in this paper, we propose G2LTraj, a plug-and-play global-to-local generation approach for trajectory prediction. Specifically, we generate a series of global key steps that uniformly cover the entire future time range. Subsequently, the local intermediate steps between the adjacent key steps are recursively filled in. In this way, we prevent the accumulated error from propagating beyond the adjacent key steps. Moreover, to boost the kinematical feasibility, we not only introduce the spatial constraints among key steps but also strengthen the temporal constraints among the intermediate steps. Finally, to ensure the optimal granularity of key steps, we design a selectable granularity strategy that caters to each predicted trajectory. Our G2LTraj significantly improves the performance of seven existing trajectory predictors across the ETH, UCY and nuScenes datasets. Experimental results demonstrate its effectiveness. Code will be available at https://github.com/Zhanwei-Z/G2LTraj.
DGE: Direct Gaussian 3D Editing by Consistent Multi-view Editing
Apr 29, 2024We consider the problem of editing 3D objects and scenes based on open-ended language instructions. The established paradigm to solve this problem is to use a 2D image generator or editor to guide the 3D editing process. However, this is often slow as it requires do update a computationally expensive 3D representations such as a neural radiance field, and to do so by using contradictory guidance from a 2D model which is inherently not multi-view consistent. We thus introduce the Direct Gaussian Editor (DGE), a method that addresses these issues in two ways. First, we modify a given high-quality image editor like InstructPix2Pix to be multi-view consistent. We do so by utilizing a training-free approach which integrates cues from the underlying 3D geometry of the scene. Second, given a multi-view consistent edited sequence of images of the object, we directly and efficiently optimize the 3D object representation, which is based on 3D Gaussian Splatting. Because it does not require to apply edits incrementally and iteratively, DGE is significantly more efficient than existing approaches, and comes with other perks such as allowing selective editing of parts of the scene.
Underwater Acoustic Signal Recognition Based on Salient Feature
Jan 05, 2024With the rapid advancement of technology, the recognition of underwater acoustic signals in complex environments has become increasingly crucial. Currently, mainstream underwater acoustic signal recognition relies primarily on time-frequency analysis to extract spectral features, finding widespread applications in the field. However, existing recognition methods heavily depend on expert systems, facing limitations such as restricted knowledge bases and challenges in handling complex relationships. These limitations stem from the complexity and maintenance difficulties associated with rules or inference engines. Recognizing the potential advantages of deep learning in handling intricate relationships, this paper proposes a method utilizing neural networks for underwater acoustic signal recognition. The proposed approach involves continual learning of features extracted from spectra for the classification of underwater acoustic signals. Deep learning models can automatically learn abstract features from data and continually adjust weights during training to enhance classification performance.
TagCLIP: A Local-to-Global Framework to Enhance Open-Vocabulary Multi-Label Classification of CLIP Without Training
Dec 20, 2023Contrastive Language-Image Pre-training (CLIP) has demonstrated impressive capabilities in open-vocabulary classification. The class token in the image encoder is trained to capture the global features to distinguish different text descriptions supervised by contrastive loss, making it highly effective for single-label classification. However, it shows poor performance on multi-label datasets because the global feature tends to be dominated by the most prominent class and the contrastive nature of softmax operation aggravates it. In this study, we observe that the multi-label classification results heavily rely on discriminative local features but are overlooked by CLIP. As a result, we dissect the preservation of patch-wise spatial information in CLIP and proposed a local-to-global framework to obtain image tags. It comprises three steps: (1) patch-level classification to obtain coarse scores; (2) dual-masking attention refinement (DMAR) module to refine the coarse scores; (3) class-wise reidentification (CWR) module to remedy predictions from a global perspective. This framework is solely based on frozen CLIP and significantly enhances its multi-label classification performance on various benchmarks without dataset-specific training. Besides, to comprehensively assess the quality and practicality of generated tags, we extend their application to the downstream task, i.e., weakly supervised semantic segmentation (WSSS) with generated tags as image-level pseudo labels. Experiments demonstrate that this classify-then-segment paradigm dramatically outperforms other annotation-free segmentation methods and validates the effectiveness of generated tags. Our code is available at https://github.com/linyq2117/TagCLIP.
SHAP-EDITOR: Instruction-guided Latent 3D Editing in Seconds
Dec 14, 2023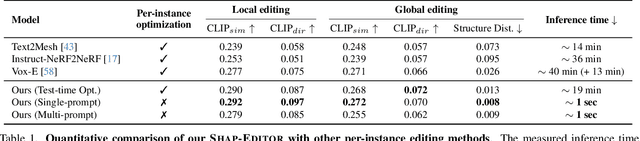
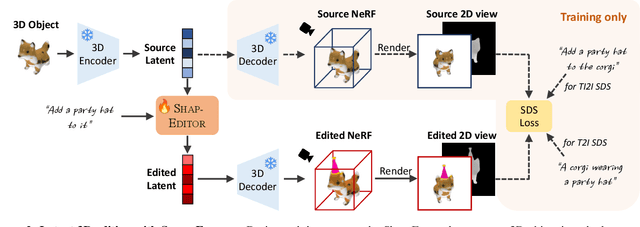
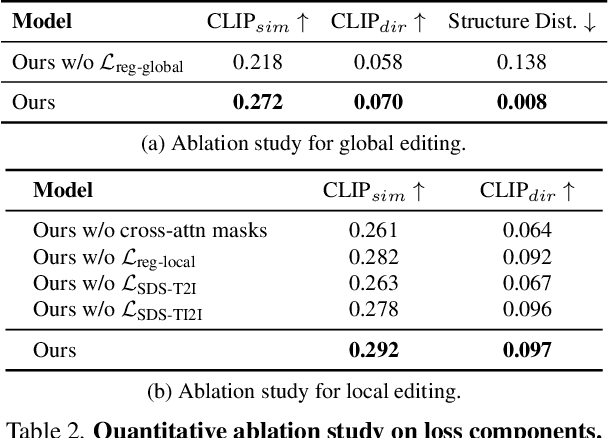

We propose a novel feed-forward 3D editing framework called Shap-Editor. Prior research on editing 3D objects primarily concentrated on editing individual objects by leveraging off-the-shelf 2D image editing networks. This is achieved via a process called distillation, which transfers knowledge from the 2D network to 3D assets. Distillation necessitates at least tens of minutes per asset to attain satisfactory editing results, and is thus not very practical. In contrast, we ask whether 3D editing can be carried out directly by a feed-forward network, eschewing test-time optimisation. In particular, we hypothesise that editing can be greatly simplified by first encoding 3D objects in a suitable latent space. We validate this hypothesis by building upon the latent space of Shap-E. We demonstrate that direct 3D editing in this space is possible and efficient by building a feed-forward editor network that only requires approximately one second per edit. Our experiments show that Shap-Editor generalises well to both in-distribution and out-of-distribution 3D assets with different prompts, exhibiting comparable performance with methods that carry out test-time optimisation for each edited instance.
A Study of Unsupervised Evaluation Metrics for Practical and Automatic Domain Adaptation
Aug 01, 2023
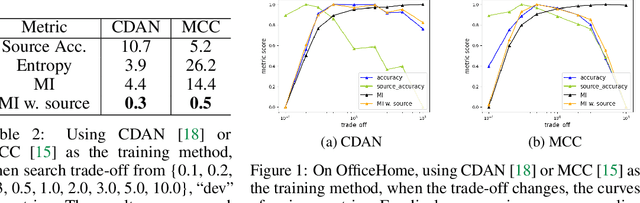
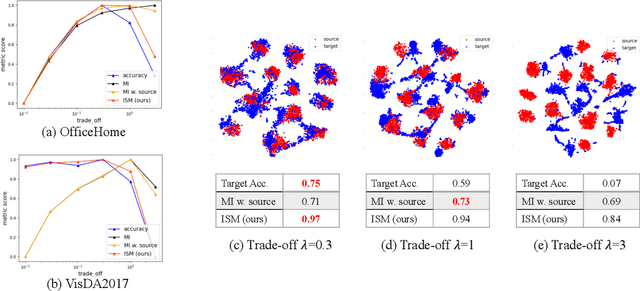
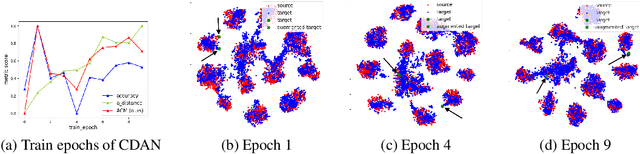
Unsupervised domain adaptation (UDA) methods facilitate the transfer of models to target domains without labels. However, these methods necessitate a labeled target validation set for hyper-parameter tuning and model selection. In this paper, we aim to find an evaluation metric capable of assessing the quality of a transferred model without access to target validation labels. We begin with the metric based on mutual information of the model prediction. Through empirical analysis, we identify three prevalent issues with this metric: 1) It does not account for the source structure. 2) It can be easily attacked. 3) It fails to detect negative transfer caused by the over-alignment of source and target features. To address the first two issues, we incorporate source accuracy into the metric and employ a new MLP classifier that is held out during training, significantly improving the result. To tackle the final issue, we integrate this enhanced metric with data augmentation, resulting in a novel unsupervised UDA metric called the Augmentation Consistency Metric (ACM). Additionally, we empirically demonstrate the shortcomings of previous experiment settings and conduct large-scale experiments to validate the effectiveness of our proposed metric. Furthermore, we employ our metric to automatically search for the optimal hyper-parameter set, achieving superior performance compared to manually tuned sets across four common benchmarks. Codes will be available soon.
PVT-SSD: Single-Stage 3D Object Detector with Point-Voxel Transformer
May 11, 2023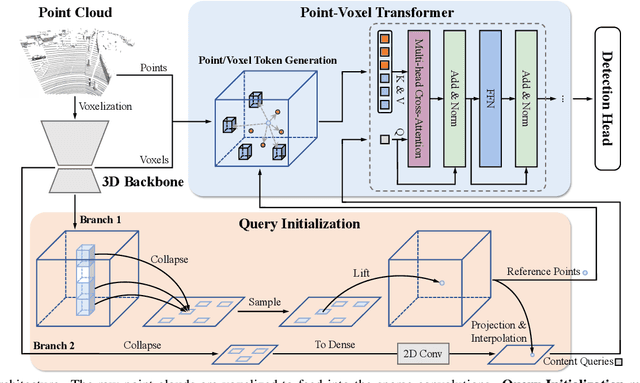
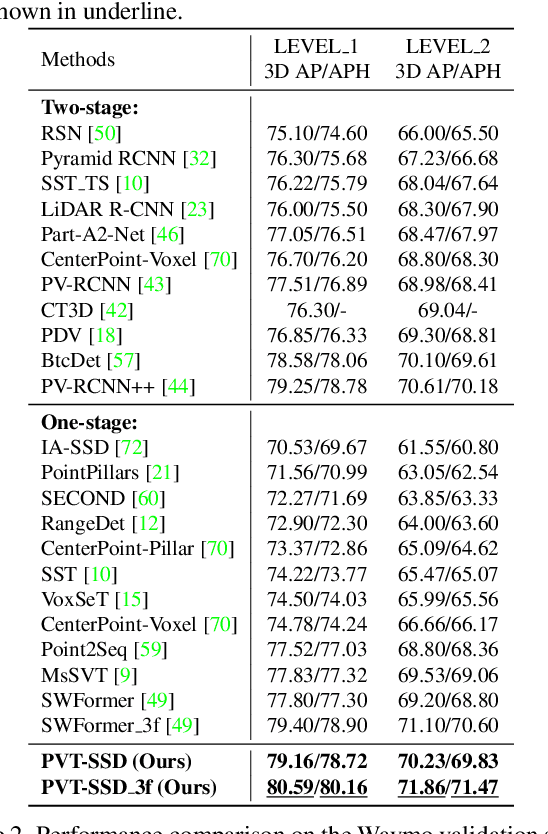
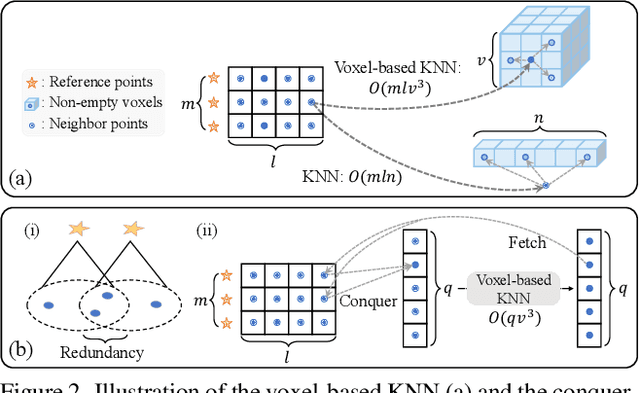
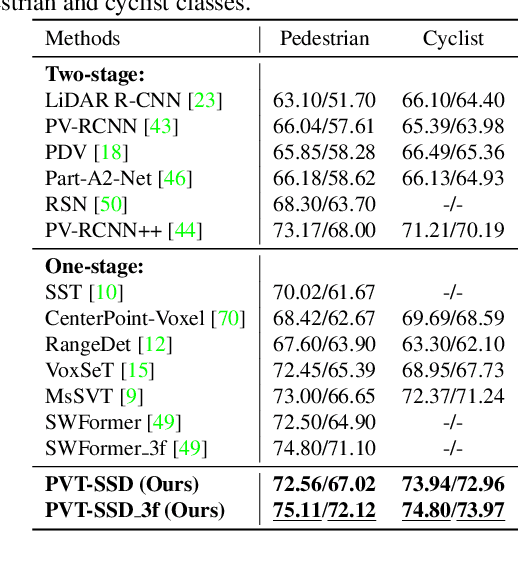
Recent Transformer-based 3D object detectors learn point cloud features either from point- or voxel-based representations. However, the former requires time-consuming sampling while the latter introduces quantization errors. In this paper, we present a novel Point-Voxel Transformer for single-stage 3D detection (PVT-SSD) that takes advantage of these two representations. Specifically, we first use voxel-based sparse convolutions for efficient feature encoding. Then, we propose a Point-Voxel Transformer (PVT) module that obtains long-range contexts in a cheap manner from voxels while attaining accurate positions from points. The key to associating the two different representations is our introduced input-dependent Query Initialization module, which could efficiently generate reference points and content queries. Then, PVT adaptively fuses long-range contextual and local geometric information around reference points into content queries. Further, to quickly find the neighboring points of reference points, we design the Virtual Range Image module, which generalizes the native range image to multi-sensor and multi-frame. The experiments on several autonomous driving benchmarks verify the effectiveness and efficiency of the proposed method. Code will be available at https://github.com/Nightmare-n/PVT-SSD.
Training-Free Layout Control with Cross-Attention Guidance
Apr 06, 2023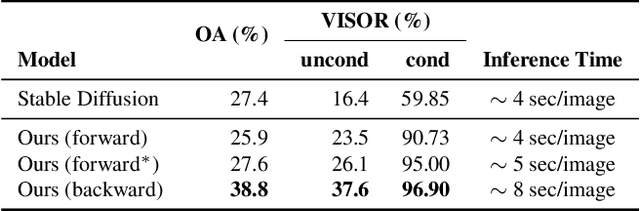
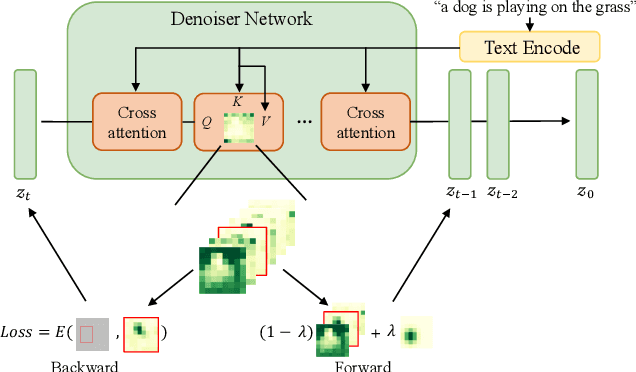
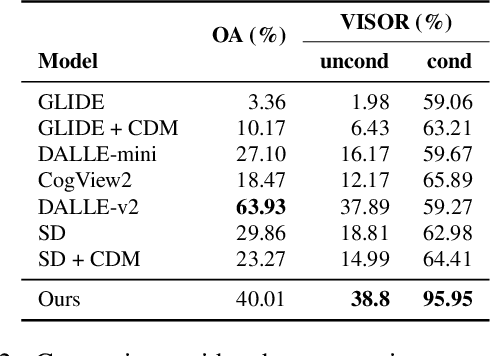
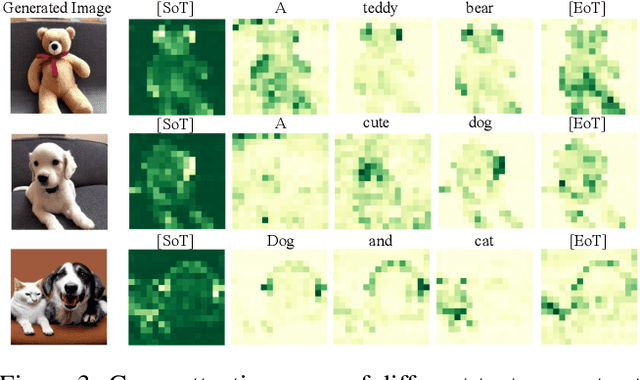
Recent diffusion-based generators can produce high-quality images based only on textual prompts. However, they do not correctly interpret instructions that specify the spatial layout of the composition. We propose a simple approach that can achieve robust layout control without requiring training or fine-tuning the image generator. Our technique, which we call layout guidance, manipulates the cross-attention layers that the model uses to interface textual and visual information and steers the reconstruction in the desired direction given, e.g., a user-specified layout. In order to determine how to best guide attention, we study the role of different attention maps when generating images and experiment with two alternative strategies, forward and backward guidance. We evaluate our method quantitatively and qualitatively with several experiments, validating its effectiveness. We further demonstrate its versatility by extending layout guidance to the task of editing the layout and context of a given real image.
Self-supervised and Weakly Supervised Contrastive Learning for Frame-wise Action Representations
Dec 23, 2022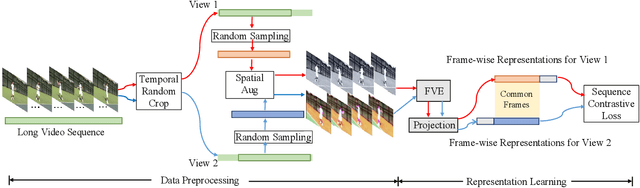
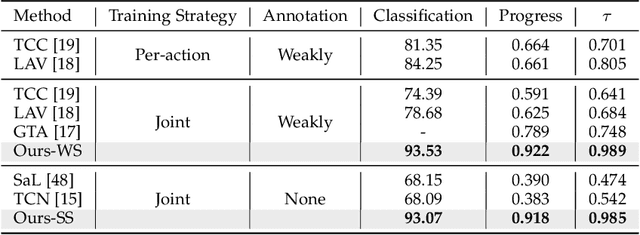
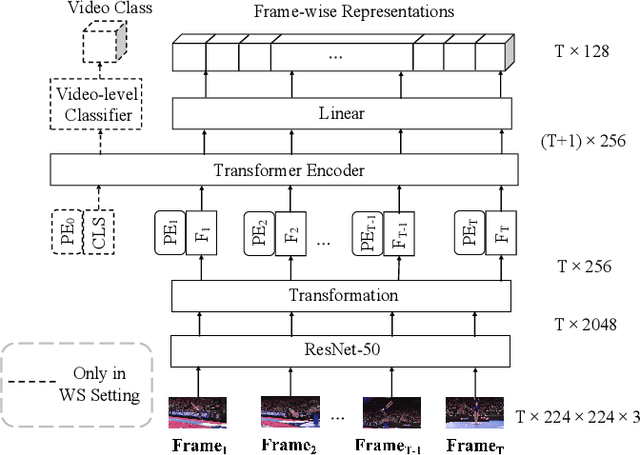
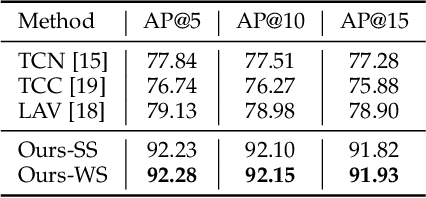
Previous work on action representation learning focused on global representations for short video clips. In contrast, many practical applications, such as video alignment, strongly demand learning the intensive representation of long videos. In this paper, we introduce a new framework of contrastive action representation learning (CARL) to learn frame-wise action representation in a self-supervised or weakly-supervised manner, especially for long videos. Specifically, we introduce a simple but effective video encoder that considers both spatial and temporal context by combining convolution and transformer. Inspired by the recent massive progress in self-supervised learning, we propose a new sequence contrast loss (SCL) applied to two related views obtained by expanding a series of spatio-temporal data in two versions. One is the self-supervised version that optimizes embedding space by minimizing KL-divergence between sequence similarity of two augmented views and prior Gaussian distribution of timestamp distance. The other is the weakly-supervised version that builds more sample pairs among videos using video-level labels by dynamic time wrapping (DTW). Experiments on FineGym, PennAction, and Pouring datasets show that our method outperforms previous state-of-the-art by a large margin for downstream fine-grained action classification and even faster inference. Surprisingly, although without training on paired videos like in previous works, our self-supervised version also shows outstanding performance in video alignment and fine-grained frame retrieval tasks.