 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYehui Tang
GhostNetV3: Exploring the Training Strategies for Compact Models
Apr 17, 2024
Compact neural networks are specially designed for applications on edge devices with faster inference speed yet modest performance. However, training strategies of compact models are borrowed from that of conventional models at present, which ignores their difference in model capacity and thus may impede the performance of compact models. In this paper, by systematically investigating the impact of different training ingredients, we introduce a strong training strategy for compact models. We find that the appropriate designs of re-parameterization and knowledge distillation are crucial for training high-performance compact models, while some commonly used data augmentations for training conventional models, such as Mixup and CutMix, lead to worse performance. Our experiments on ImageNet-1K dataset demonstrate that our specialized training strategy for compact models is applicable to various architectures, including GhostNetV2, MobileNetV2 and ShuffleNetV2. Specifically, equipped with our strategy, GhostNetV3 1.3$\times$ achieves a top-1 accuracy of 79.1% with only 269M FLOPs and a latency of 14.46ms on mobile devices, surpassing its ordinarily trained counterpart by a large margin. Moreover, our observation can also be extended to object detection scenarios. PyTorch code and checkpoints can be found at https://github.com/huawei-noah/Efficient-AI-Backbones/tree/master/ghostnetv3_pytorch.
DenseMamba: State Space Models with Dense Hidden Connection for Efficient Large Language Models
Mar 05, 2024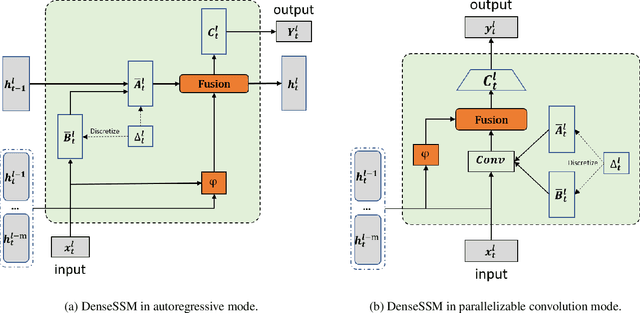
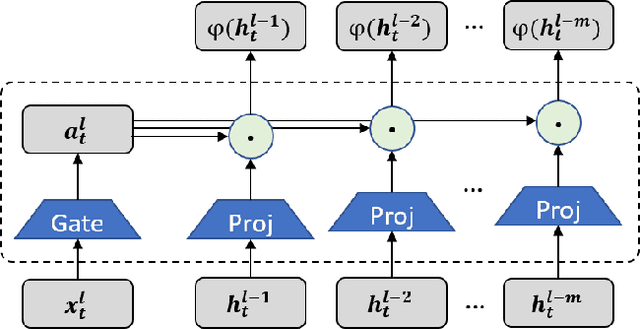

Large language models (LLMs) face a daunting challenge due to the excessive computational and memory requirements of the commonly used Transformer architecture. While state space model (SSM) is a new type of foundational network architecture offering lower computational complexity, their performance has yet to fully rival that of Transformers. This paper introduces DenseSSM, a novel approach to enhance the flow of hidden information between layers in SSMs. By selectively integrating shallowlayer hidden states into deeper layers, DenseSSM retains fine-grained information crucial for the final output. Dense connections enhanced DenseSSM still maintains the training parallelizability and inference efficiency. The proposed method can be widely applicable to various SSM types like RetNet and Mamba. With similar model size, DenseSSM achieves significant improvements, exemplified by DenseRetNet outperforming the original RetNet with up to 5% accuracy improvement on public benchmarks. code is avalaible at https://github.com/WailordHe/DenseSSM
SAM-DiffSR: Structure-Modulated Diffusion Model for Image Super-Resolution
Feb 27, 2024Diffusion-based super-resolution (SR) models have recently garnered significant attention due to their potent restoration capabilities. But conventional diffusion models perform noise sampling from a single distribution, constraining their ability to handle real-world scenes and complex textures across semantic regions. With the success of segment anything model (SAM), generating sufficiently fine-grained region masks can enhance the detail recovery of diffusion-based SR model. However, directly integrating SAM into SR models will result in much higher computational cost. In this paper, we propose the SAM-DiffSR model, which can utilize the fine-grained structure information from SAM in the process of sampling noise to improve the image quality without additional computational cost during inference. In the process of training, we encode structural position information into the segmentation mask from SAM. Then the encoded mask is integrated into the forward diffusion process by modulating it to the sampled noise. This adjustment allows us to independently adapt the noise mean within each corresponding segmentation area. The diffusion model is trained to estimate this modulated noise. Crucially, our proposed framework does NOT change the reverse diffusion process and does NOT require SAM at inference. Experimental results demonstrate the effectiveness of our proposed method, showcasing superior performance in suppressing artifacts, and surpassing existing diffusion-based methods by 0.74 dB at the maximum in terms of PSNR on DIV2K dataset. The code and dataset are available at https://github.com/lose4578/SAM-DiffSR.
Data-efficient Large Vision Models through Sequential Autoregression
Feb 07, 2024Training general-purpose vision models on purely sequential visual data, eschewing linguistic inputs, has heralded a new frontier in visual understanding. These models are intended to not only comprehend but also seamlessly transit to out-of-domain tasks. However, current endeavors are hamstrung by an over-reliance on colossal models, exemplified by models with upwards of 3B parameters, and the necessity for an extensive corpus of visual data, often comprising a staggering 400B tokens. In this paper, we delve into the development of an efficient, autoregression-based vision model, innovatively architected to operate on a limited dataset. We meticulously demonstrate how this model achieves proficiency in a spectrum of visual tasks spanning both high-level and low-level semantic understanding during the testing phase. Our empirical evaluations underscore the model's agility in adapting to various tasks, heralding a significant reduction in the parameter footprint, and a marked decrease in training data requirements, thereby paving the way for more sustainable and accessible advancements in the field of generalist vision models. The code is available at https://github.com/ggjy/DeLVM.
Rethinking Optimization and Architecture for Tiny Language Models
Feb 06, 2024The power of large language models (LLMs) has been demonstrated through numerous data and computing resources. However, the application of language models on mobile devices is facing huge challenge on the computation and memory costs, that is, tiny language models with high performance are urgently required. Limited by the highly complex training process, there are many details for optimizing language models that are seldom studied carefully. In this study, based on a tiny language model with 1B parameters, we carefully design a series of empirical study to analyze the effect of each component. Three perspectives are mainly discussed, \ie, neural architecture, parameter initialization, and optimization strategy. Several design formulas are empirically proved especially effective for tiny language models, including tokenizer compression, architecture tweaking, parameter inheritance and multiple-round training. Then we train PanGu-$\pi$-1B Pro and PanGu-$\pi$-1.5B Pro on 1.6T multilingual corpora, following the established formulas. Experimental results demonstrate the improved optimization and architecture yield a notable average improvement of 8.87 on benchmark evaluation sets for PanGu-$\pi$-1B Pro. Besides, PanGu-$\pi$-1.5B Pro surpasses a range of SOTA models with larger model sizes, validating its superior performance. The code is available at https://github.com/YuchuanTian/RethinkTinyLM.
A Survey on Transformer Compression
Feb 05, 2024Large models based on the Transformer architecture play increasingly vital roles in artificial intelligence, particularly within the realms of natural language processing (NLP) and computer vision (CV). Model compression methods reduce their memory and computational cost, which is a necessary step to implement the transformer models on practical devices. Given the unique architecture of transformer, featuring alternative attention and Feedforward Neural Network (FFN) modules, specific compression techniques are required. The efficiency of these compression methods is also paramount, as it is usually impractical to retrain large models on the entire training dataset.This survey provides a comprehensive review of recent compression methods, with a specific focus on their application to transformer models. The compression methods are primarily categorized into pruning, quantization, knowledge distillation, and efficient architecture design. In each category, we discuss compression methods for both CV and NLP tasks, highlighting common underlying principles. At last, we delve into the relation between various compression methods, and discuss the further directions in this domain.
PanGu-$π$: Enhancing Language Model Architectures via Nonlinearity Compensation
Dec 27, 2023The recent trend of large language models (LLMs) is to increase the scale of both model size (\aka the number of parameters) and dataset to achieve better generative ability, which is definitely proved by a lot of work such as the famous GPT and Llama. However, large models often involve massive computational costs, and practical applications cannot afford such high prices. However, the method of constructing a strong model architecture for LLMs is rarely discussed. We first analyze the state-of-the-art language model architectures and observe the feature collapse problem. Based on the theoretical analysis, we propose that the nonlinearity is also very important for language models, which is usually studied in convolutional neural networks for vision tasks. The series informed activation function is then introduced with tiny calculations that can be ignored, and an augmented shortcut is further used to enhance the model nonlinearity. We then demonstrate that the proposed approach is significantly effective for enhancing the model nonlinearity through carefully designed ablations; thus, we present a new efficient model architecture for establishing modern, namely, PanGu-$\pi$. Experiments are then conducted using the same dataset and training strategy to compare PanGu-$\pi$ with state-of-the-art LLMs. The results show that PanGu-$\pi$-7B can achieve a comparable performance to that of benchmarks with about 10\% inference speed-up, and PanGu-$\pi$-1B can achieve state-of-the-art performance in terms of accuracy and efficiency. In addition, we have deployed PanGu-$\pi$-7B in the high-value domains of finance and law, developing an LLM named YunShan for practical application. The results show that YunShan can surpass other models with similar scales on benchmarks.
TinySAM: Pushing the Envelope for Efficient Segment Anything Model
Dec 21, 2023Recently segment anything model (SAM) has shown powerful segmentation capability and has drawn great attention in computer vision fields. Massive following works have developed various applications based on the pretrained SAM and achieved impressive performance on downstream vision tasks. However, SAM consists of heavy architectures and requires massive computational capacity, which hinders the further application of SAM on computation constrained edge devices. To this end, in this paper we propose a framework to obtain a tiny segment anything model (TinySAM) while maintaining the strong zero-shot performance. We first propose a full-stage knowledge distillation method with online hard prompt sampling strategy to distill a lightweight student model. We also adapt the post-training quantization to the promptable segmentation task and further reduce the computational cost. Moreover, a hierarchical segmenting everything strategy is proposed to accelerate the everything inference by $2\times$ with almost no performance degradation. With all these proposed methods, our TinySAM leads to orders of magnitude computational reduction and pushes the envelope for efficient segment anything task. Extensive experiments on various zero-shot transfer tasks demonstrate the significantly advantageous performance of our TinySAM against counterpart methods. Pre-trained models and codes will be available at https://github.com/xinghaochen/TinySAM and https://gitee.com/mindspore/models/tree/master/research/cv/TinySAM.
CBQ: Cross-Block Quantization for Large Language Models
Dec 13, 2023Post-training quantization (PTQ) has driven attention to producing efficient large language models (LLMs) with ultra-low costs. Since hand-craft quantization parameters lead to low performance in low-bit quantization, recent methods optimize the quantization parameters through block-wise reconstruction between the floating-point and quantized models. However, these methods suffer from two challenges: accumulated errors from independent one-by-one block quantization and reconstruction difficulties from extreme weight and activation outliers. To address these two challenges, we propose CBQ, a cross-block reconstruction-based PTQ method for LLMs. To reduce error accumulation, we introduce a cross-block dependency with the aid of a homologous reconstruction scheme to build the long-range dependency between adjacent multi-blocks with overlapping. To reduce reconstruction difficulty, we design a coarse-to-fine pre-processing (CFP) to truncate weight outliers and dynamically scale activation outliers before optimization, and an adaptive rounding scheme, called LoRA-Rounding, with two low-rank learnable matrixes to further rectify weight quantization errors. Extensive experiments demonstrate that: (1) CBQ pushes both activation and weight quantization to low-bit settings W4A4, W4A8, and W2A16. (2) CBQ achieves better performance than the existing state-of-the-art methods on various LLMs and benchmark datasets.
LightCLIP: Learning Multi-Level Interaction for Lightweight Vision-Language Models
Dec 01, 2023Vision-language pre-training like CLIP has shown promising performance on various downstream tasks such as zero-shot image classification and image-text retrieval. Most of the existing CLIP-alike works usually adopt relatively large image encoders like ResNet50 and ViT, while the lightweight counterparts are rarely discussed. In this paper, we propose a multi-level interaction paradigm for training lightweight CLIP models. Firstly, to mitigate the problem that some image-text pairs are not strictly one-to-one correspondence, we improve the conventional global instance-level alignment objective by softening the label of negative samples progressively. Secondly, a relaxed bipartite matching based token-level alignment objective is introduced for finer-grained alignment between image patches and textual words. Moreover, based on the observation that the accuracy of CLIP model does not increase correspondingly as the parameters of text encoder increase, an extra objective of masked language modeling (MLM) is leveraged for maximizing the potential of the shortened text encoder. In practice, an auxiliary fusion module injecting unmasked image embedding into masked text embedding at different network stages is proposed for enhancing the MLM. Extensive experiments show that without introducing additional computational cost during inference, the proposed method achieves a higher performance on multiple downstream tasks.