 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDaniel Ritchie
Learning to Infer Generative Template Programs for Visual Concepts
Mar 20, 2024
People grasp flexible visual concepts from a few examples. We explore a neurosymbolic system that learns how to infer programs that capture visual concepts in a domain-general fashion. We introduce Template Programs: programmatic expressions from a domain-specific language that specify structural and parametric patterns common to an input concept. Our framework supports multiple concept-related tasks, including few-shot generation and co-segmentation through parsing. We develop a learning paradigm that allows us to train networks that infer Template Programs directly from visual datasets that contain concept groupings. We run experiments across multiple visual domains: 2D layouts, Omniglot characters, and 3D shapes. We find that our method outperforms task-specific alternatives, and performs competitively against domain-specific approaches for the limited domains where they exist.
R3DS: Reality-linked 3D Scenes for Panoramic Scene Understanding
Mar 18, 2024
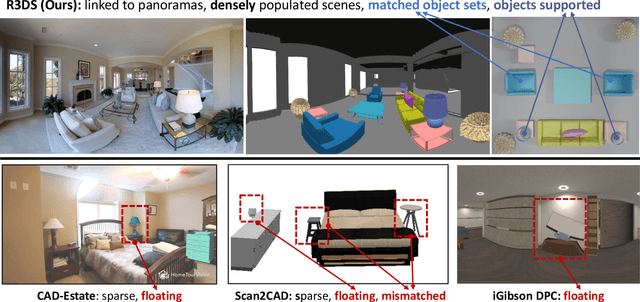
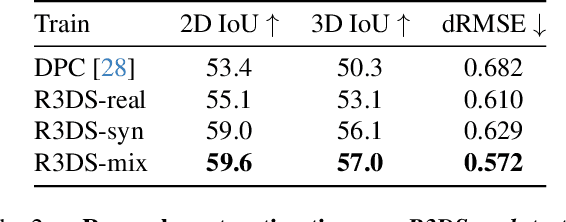

We introduce the Reality-linked 3D Scenes (R3DS) dataset of synthetic 3D scenes mirroring the real-world scene arrangements from Matterport3D panoramas. Compared to prior work, R3DS has more complete and densely populated scenes with objects linked to real-world observations in panoramas. R3DS also provides an object support hierarchy, and matching object sets (e.g., same chairs around a dining table) for each scene. Overall, R3DS contains 19K objects represented by 3,784 distinct CAD models from over 100 object categories. We demonstrate the effectiveness of R3DS on the Panoramic Scene Understanding task. We find that: 1) training on R3DS enables better generalization; 2) support relation prediction trained with R3DS improves performance compared to heuristically calculated support; and 3) R3DS offers a challenging benchmark for future work on panoramic scene understanding.
Generalizing Single-View 3D Shape Retrieval to Occlusions and Unseen Objects
Dec 31, 2023Single-view 3D shape retrieval is a challenging task that is increasingly important with the growth of available 3D data. Prior work that has studied this task has not focused on evaluating how realistic occlusions impact performance, and how shape retrieval methods generalize to scenarios where either the target 3D shape database contains unseen shapes, or the input image contains unseen objects. In this paper, we systematically evaluate single-view 3D shape retrieval along three different axes: the presence of object occlusions and truncations, generalization to unseen 3D shape data, and generalization to unseen objects in the input images. We standardize two existing datasets of real images and propose a dataset generation pipeline to produce a synthetic dataset of scenes with multiple objects exhibiting realistic occlusions. Our experiments show that training on occlusion-free data as was commonly done in prior work leads to significant performance degradation for inputs with occlusion. We find that that by first pretraining on our synthetic dataset with occlusions and then finetuning on real data, we can significantly outperform models from prior work and demonstrate robustness to both unseen 3D shapes and unseen objects.
Explorable Mesh Deformation Subspaces from Unstructured Generative Models
Oct 11, 2023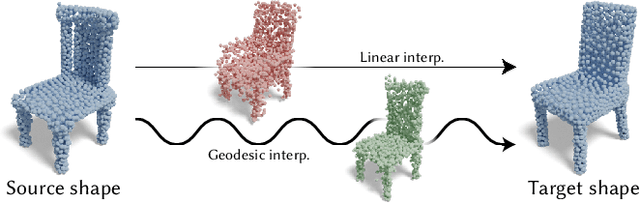
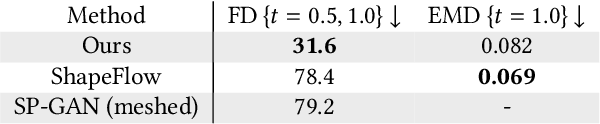
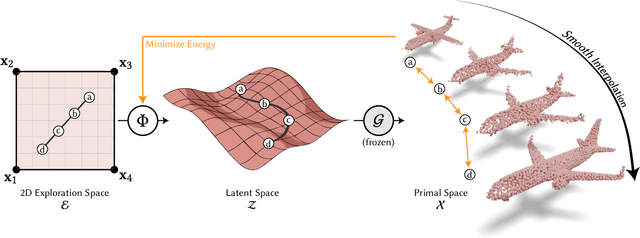
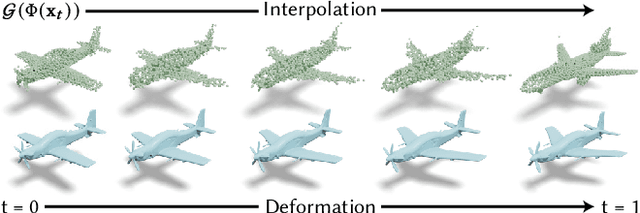
Exploring variations of 3D shapes is a time-consuming process in traditional 3D modeling tools. Deep generative models of 3D shapes often feature continuous latent spaces that can, in principle, be used to explore potential variations starting from a set of input shapes. In practice, doing so can be problematic: latent spaces are high dimensional and hard to visualize, contain shapes that are not relevant to the input shapes, and linear paths through them often lead to sub-optimal shape transitions. Furthermore, one would ideally be able to explore variations in the original high-quality meshes used to train the generative model, not its lower-quality output geometry. In this paper, we present a method to explore variations among a given set of landmark shapes by constructing a mapping from an easily-navigable 2D exploration space to a subspace of a pre-trained generative model. We first describe how to find a mapping that spans the set of input landmark shapes and exhibits smooth variations between them. We then show how to turn the variations in this subspace into deformation fields, to transfer those variations to high-quality meshes for the landmark shapes. Our results show that our method can produce visually-pleasing and easily-navigable 2D exploration spaces for several different shape categories, especially as compared to prior work on learning deformation spaces for 3D shapes.
Improving Unsupervised Visual Program Inference with Code Rewriting Families
Sep 26, 2023Programs offer compactness and structure that makes them an attractive representation for visual data. We explore how code rewriting can be used to improve systems for inferring programs from visual data. We first propose Sparse Intermittent Rewrite Injection (SIRI), a framework for unsupervised bootstrapped learning. SIRI sparsely applies code rewrite operations over a dataset of training programs, injecting the improved programs back into the training set. We design a family of rewriters for visual programming domains: parameter optimization, code pruning, and code grafting. For three shape programming languages in 2D and 3D, we show that using SIRI with our family of rewriters improves performance: better reconstructions and faster convergence rates, compared with bootstrapped learning methods that do not use rewriters or use them naively. Finally, we demonstrate that our family of rewriters can be effectively used at test time to improve the output of SIRI predictions. For 2D and 3D CSG, we outperform or match the reconstruction performance of recent domain-specific neural architectures, while producing more parsimonious programs that use significantly fewer primitives.
ShapeCoder: Discovering Abstractions for Visual Programs from Unstructured Primitives
May 09, 2023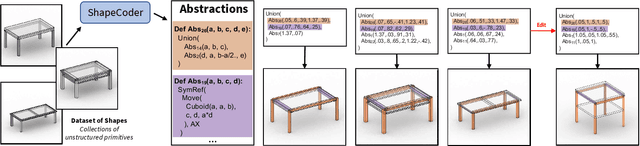

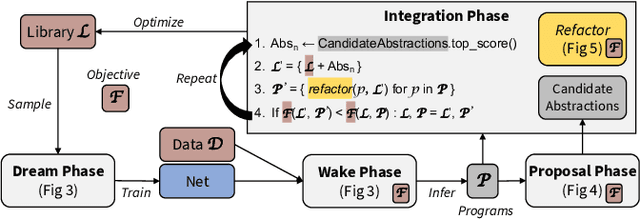

Programs are an increasingly popular representation for visual data, exposing compact, interpretable structure that supports manipulation. Visual programs are usually written in domain-specific languages (DSLs). Finding "good" programs, that only expose meaningful degrees of freedom, requires access to a DSL with a "good" library of functions, both of which are typically authored by domain experts. We present ShapeCoder, the first system capable of taking a dataset of shapes, represented with unstructured primitives, and jointly discovering (i) useful abstraction functions and (ii) programs that use these abstractions to explain the input shapes. The discovered abstractions capture common patterns (both structural and parametric) across the dataset, so that programs rewritten with these abstractions are more compact, and expose fewer degrees of freedom. ShapeCoder improves upon previous abstraction discovery methods, finding better abstractions, for more complex inputs, under less stringent input assumptions. This is principally made possible by two methodological advancements: (a) a shape to program recognition network that learns to solve sub-problems and (b) the use of e-graphs, augmented with a conditional rewrite scheme, to determine when abstractions with complex parametric expressions can be applied, in a tractable manner. We evaluate ShapeCoder on multiple datasets of 3D shapes, where primitive decompositions are either parsed from manual annotations or produced by an unsupervised cuboid abstraction method. In all domains, ShapeCoder discovers a library of abstractions that capture high-level relationships, remove extraneous degrees of freedom, and achieve better dataset compression compared with alternative approaches. Finally, we investigate how programs rewritten to use discovered abstractions prove useful for downstream tasks.
Unsupervised 3D Shape Reconstruction by Part Retrieval and Assembly
Mar 03, 2023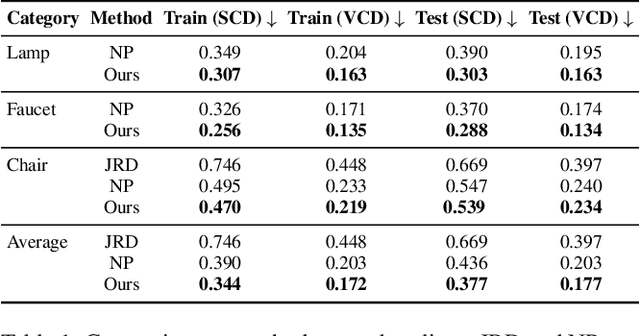
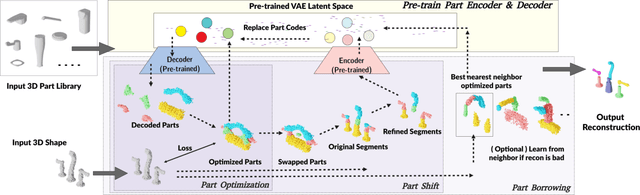
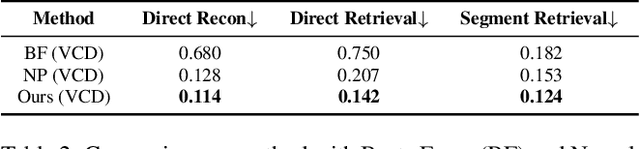
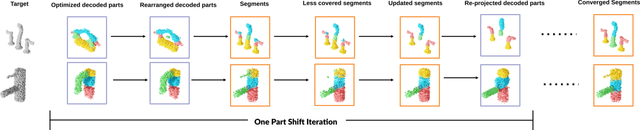
Representing a 3D shape with a set of primitives can aid perception of structure, improve robotic object manipulation, and enable editing, stylization, and compression of 3D shapes. Existing methods either use simple parametric primitives or learn a generative shape space of parts. Both have limitations: parametric primitives lead to coarse approximations, while learned parts offer too little control over the decomposition. We instead propose to decompose shapes using a library of 3D parts provided by the user, giving full control over the choice of parts. The library can contain parts with high-quality geometry that are suitable for a given category, resulting in meaningful decompositions with clean geometry. The type of decomposition can also be controlled through the choice of parts in the library. Our method works via a self-supervised approach that iteratively retrieves parts from the library and refines their placements. We show that this approach gives higher reconstruction accuracy and more desirable decompositions than existing approaches. Additionally, we show how the decomposition can be controlled through the part library by using different part libraries to reconstruct the same shapes.
TextCraft: Zero-Shot Generation of High-Fidelity and Diverse Shapes from Text
Nov 04, 2022


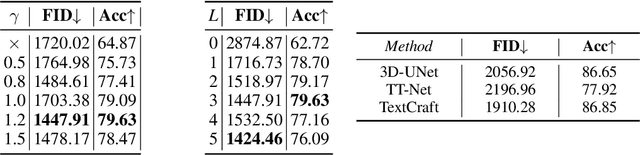
Language is one of the primary means by which we describe the 3D world around us. While rapid progress has been made in text-to-2D-image synthesis, similar progress in text-to-3D-shape synthesis has been hindered by the lack of paired (text, shape) data. Moreover, extant methods for text-to-shape generation have limited shape diversity and fidelity. We introduce TextCraft, a method to address these limitations by producing high-fidelity and diverse 3D shapes without the need for (text, shape) pairs for training. TextCraft achieves this by using CLIP and using a multi-resolution approach by first generating in a low-dimensional latent space and then upscaling to a higher resolution, improving the fidelity of the generated shape. To improve shape diversity, we use a discrete latent space which is modelled using a bidirectional transformer conditioned on the interchangeable image-text embedding space induced by CLIP. Moreover, we present a novel variant of classifier-free guidance, which further improves the accuracy-diversity trade-off. Finally, we perform extensive experiments that demonstrate that TextCraft outperforms state-of-the-art baselines.
ShapeCrafter: A Recursive Text-Conditioned 3D Shape Generation Model
Jul 19, 2022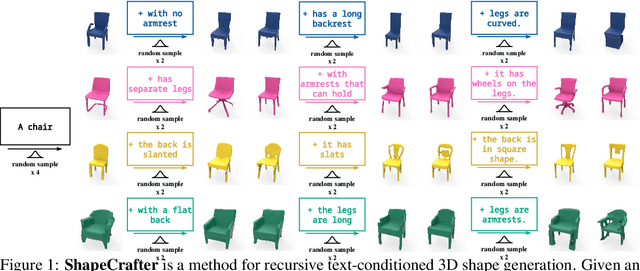

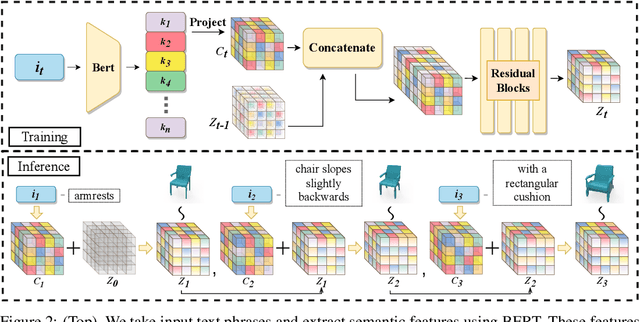

We present ShapeCrafter, a neural network for recursive text-conditioned 3D shape generation. Existing methods to generate text-conditioned 3D shapes consume an entire text prompt to generate a 3D shape in a single step. However, humans tend to describe shapes recursively-we may start with an initial description and progressively add details based on intermediate results. To capture this recursive process, we introduce a method to generate a 3D shape distribution, conditioned on an initial phrase, that gradually evolves as more phrases are added. Since existing datasets are insufficient for training this approach, we present Text2Shape++, a large dataset of 369K shape-text pairs that supports recursive shape generation. To capture local details that are often used to refine shape descriptions, we build on top of vector-quantized deep implicit functions that generate a distribution of high-quality shapes. Results show that our method can generate shapes consistent with text descriptions, and shapes evolve gradually as more phrases are added. Our method supports shape editing, extrapolation, and can enable new applications in human-machine collaboration for creative design.
Unsupervised Kinematic Motion Detection for Part-segmented 3D Shape Collections
Jun 17, 2022
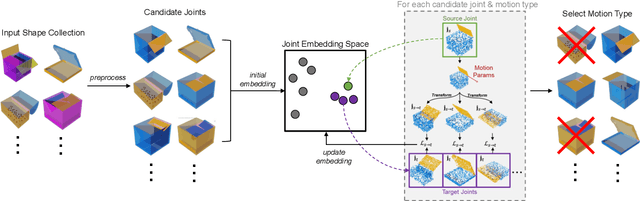


3D models of manufactured objects are important for populating virtual worlds and for synthetic data generation for vision and robotics. To be most useful, such objects should be articulated: their parts should move when interacted with. While articulated object datasets exist, creating them is labor-intensive. Learning-based prediction of part motions can help, but all existing methods require annotated training data. In this paper, we present an unsupervised approach for discovering articulated motions in a part-segmented 3D shape collection. Our approach is based on a concept we call category closure: any valid articulation of an object's parts should keep the object in the same semantic category (e.g. a chair stays a chair). We operationalize this concept with an algorithm that optimizes a shape's part motion parameters such that it can transform into other shapes in the collection. We evaluate our approach by using it to re-discover part motions from the PartNet-Mobility dataset. For almost all shape categories, our method's predicted motion parameters have low error with respect to ground truth annotations, outperforming two supervised motion prediction methods.