 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYufang Hou
On the Role of Summary Content Units in Text Summarization Evaluation
Apr 02, 2024
At the heart of the Pyramid evaluation method for text summarization lie human written summary content units (SCUs). These SCUs are concise sentences that decompose a summary into small facts. Such SCUs can be used to judge the quality of a candidate summary, possibly partially automated via natural language inference (NLI) systems. Interestingly, with the aim to fully automate the Pyramid evaluation, Zhang and Bansal (2021) show that SCUs can be approximated by automatically generated semantic role triplets (STUs). However, several questions currently lack answers, in particular: i) Are there other ways of approximating SCUs that can offer advantages? ii) Under which conditions are SCUs (or their approximations) offering the most value? In this work, we examine two novel strategies to approximate SCUs: generating SCU approximations from AMR meaning representations (SMUs) and from large language models (SGUs), respectively. We find that while STUs and SMUs are competitive, the best approximation quality is achieved by SGUs. We also show through a simple sentence-decomposition baseline (SSUs) that SCUs (and their approximations) offer the most value when ranking short summaries, but may not help as much when ranking systems or longer summaries.
Dive into the Chasm: Probing the Gap between In- and Cross-Topic Generalization
Feb 02, 2024Pre-trained language models (LMs) perform well in In-Topic setups, where training and testing data come from the same topics. However, they face challenges in Cross-Topic scenarios where testing data is derived from distinct topics -- such as Gun Control. This study analyzes various LMs with three probing-based experiments to shed light on the reasons behind the In- vs. Cross-Topic generalization gap. Thereby, we demonstrate, for the first time, that generalization gaps and the robustness of the embedding space vary significantly across LMs. Additionally, we assess larger LMs and underscore the relevance of our analysis for recent models. Overall, diverse pre-training objectives, architectural regularization, or data deduplication contribute to more robust LMs and diminish generalization gaps. Our research contributes to a deeper understanding and comparison of language models across different generalization scenarios.
'Don't Get Too Technical with Me': A Discourse Structure-Based Framework for Science Journalism
Oct 23, 2023Science journalism refers to the task of reporting technical findings of a scientific paper as a less technical news article to the general public audience. We aim to design an automated system to support this real-world task (i.e., automatic science journalism) by 1) introducing a newly-constructed and real-world dataset (SciTechNews), with tuples of a publicly-available scientific paper, its corresponding news article, and an expert-written short summary snippet; 2) proposing a novel technical framework that integrates a paper's discourse structure with its metadata to guide generation; and, 3) demonstrating with extensive automatic and human experiments that our framework outperforms other baseline methods (e.g. Alpaca and ChatGPT) in elaborating a content plan meaningful for the target audience, simplifying the information selected, and producing a coherent final report in a layman's style.
Matching Pairs: Attributing Fine-Tuned Models to their Pre-Trained Large Language Models
Jun 15, 2023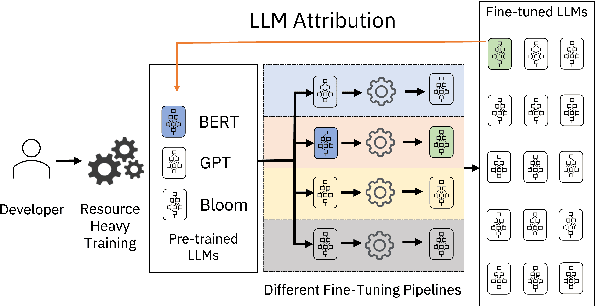
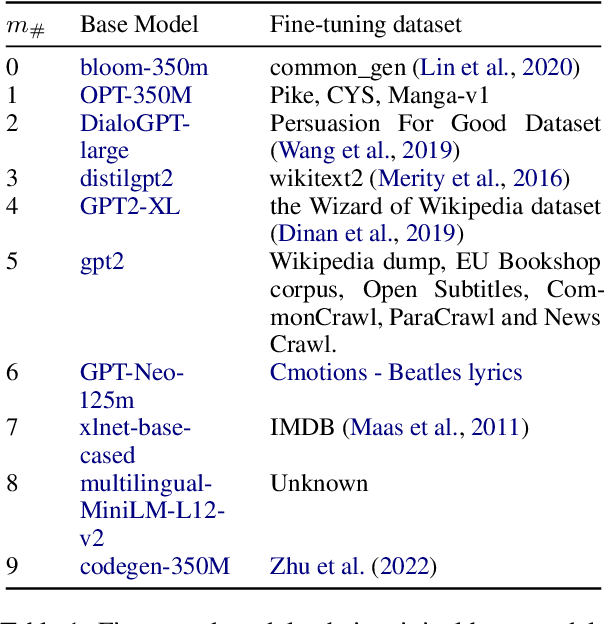
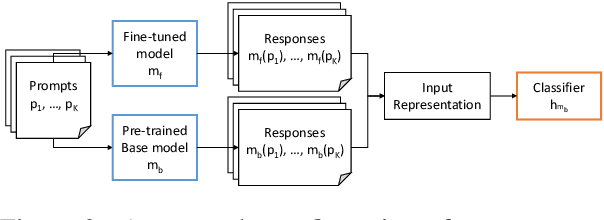

The wide applicability and adaptability of generative large language models (LLMs) has enabled their rapid adoption. While the pre-trained models can perform many tasks, such models are often fine-tuned to improve their performance on various downstream applications. However, this leads to issues over violation of model licenses, model theft, and copyright infringement. Moreover, recent advances show that generative technology is capable of producing harmful content which exacerbates the problems of accountability within model supply chains. Thus, we need a method to investigate how a model was trained or a piece of text was generated and what their pre-trained base model was. In this paper we take the first step to address this open problem by tracing back the origin of a given fine-tuned LLM to its corresponding pre-trained base model. We consider different knowledge levels and attribution strategies, and find that we can correctly trace back 8 out of the 10 fine tuned models with our best method.
Are Fairy Tales Fair? Analyzing Gender Bias in Temporal Narrative Event Chains of Children's Fairy Tales
May 26, 2023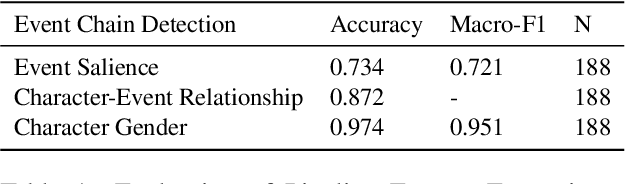
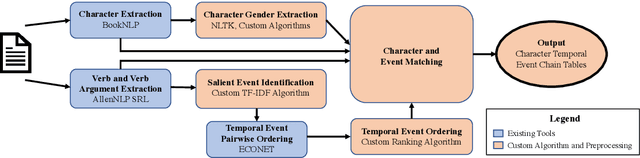
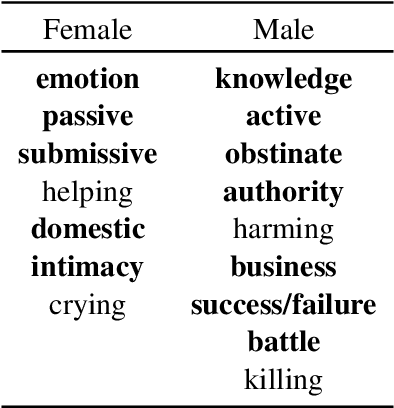
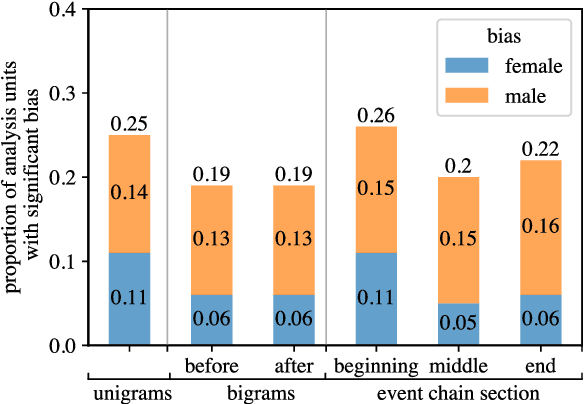
Social biases and stereotypes are embedded in our culture in part through their presence in our stories, as evidenced by the rich history of humanities and social science literature analyzing such biases in children stories. Because these analyses are often conducted manually and at a small scale, such investigations can benefit from the use of more recent natural language processing methods that examine social bias in models and data corpora. Our work joins this interdisciplinary effort and makes a unique contribution by taking into account the event narrative structures when analyzing the social bias of stories. We propose a computational pipeline that automatically extracts a story's temporal narrative verb-based event chain for each of its characters as well as character attributes such as gender. We also present a verb-based event annotation scheme that can facilitate bias analysis by including categories such as those that align with traditional stereotypes. Through a case study analyzing gender bias in fairy tales, we demonstrate that our framework can reveal bias in not only the unigram verb-based events in which female and male characters participate but also in the temporal narrative order of such event participation.
A Diachronic Analysis of the NLP Research Paradigm Shift: When, How, and Why?
May 22, 2023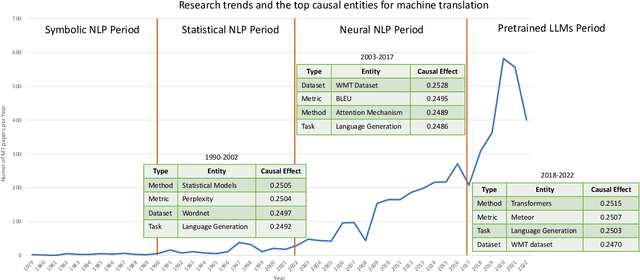
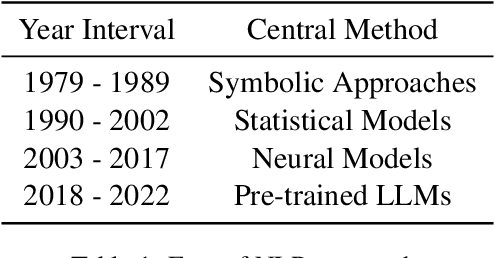
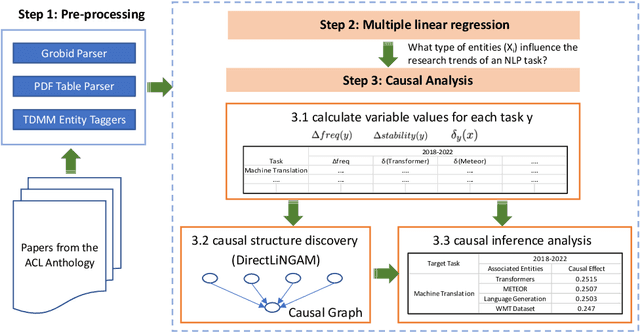
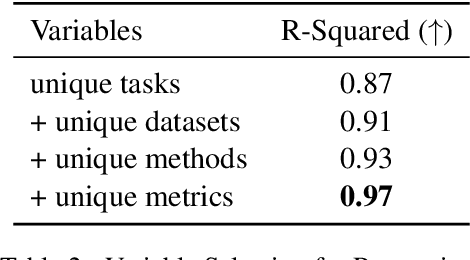
Understanding the fundamental concepts and trends in a scientific field is crucial for keeping abreast of its ongoing development. In this study, we propose a systematic framework for analyzing the evolution of research topics in a scientific field using causal discovery and inference techniques. By conducting extensive experiments on the ACL Anthology corpus, we demonstrate that our framework effectively uncovers evolutionary trends and the underlying causes for a wide range of natural language processing (NLP) research topics.
Needle in a Haystack: An Analysis of Finding Qualified Workers on MTurk for Summarization
Dec 28, 2022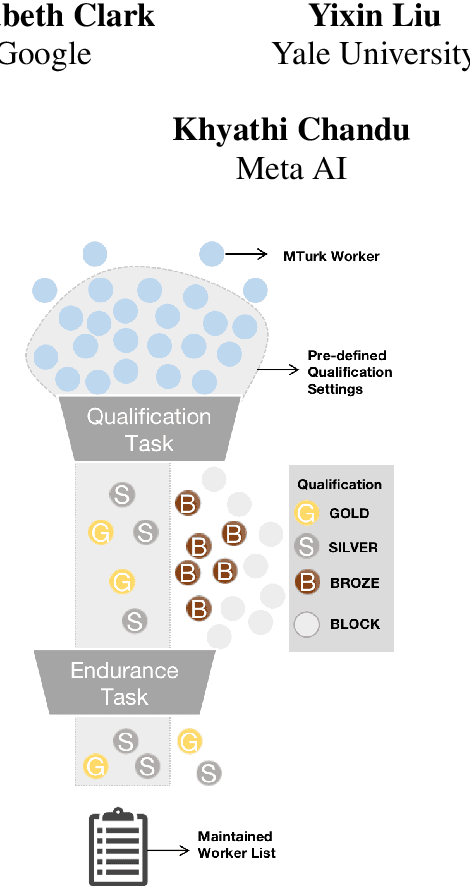
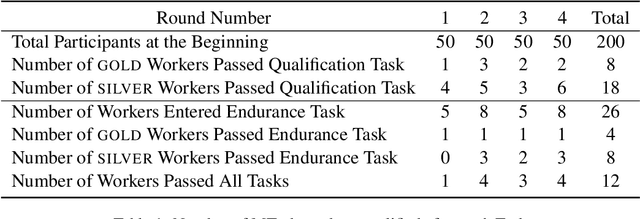
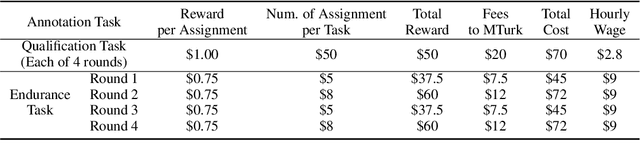
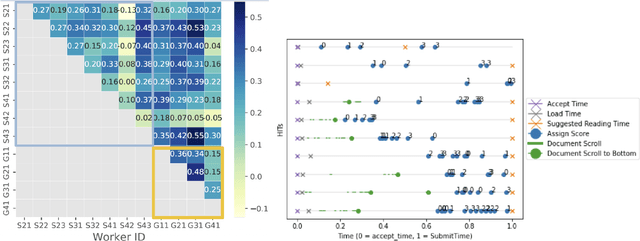
The acquisition of high-quality human annotations through crowdsourcing platforms like Amazon Mechanical Turk (MTurk) is more challenging than expected. The annotation quality might be affected by various aspects like annotation instructions, Human Intelligence Task (HIT) design, and wages paid to annotators, etc. To avoid potentially low-quality annotations which could mislead the evaluation of automatic summarization system outputs, we investigate the recruitment of high-quality MTurk workers via a three-step qualification pipeline. We show that we can successfully filter out bad workers before they carry out the evaluations and obtain high-quality annotations while optimizing the use of resources. This paper can serve as basis for the recruitment of qualified annotators in other challenging annotation tasks.
CiteBench: A benchmark for Scientific Citation Text Generation
Dec 19, 2022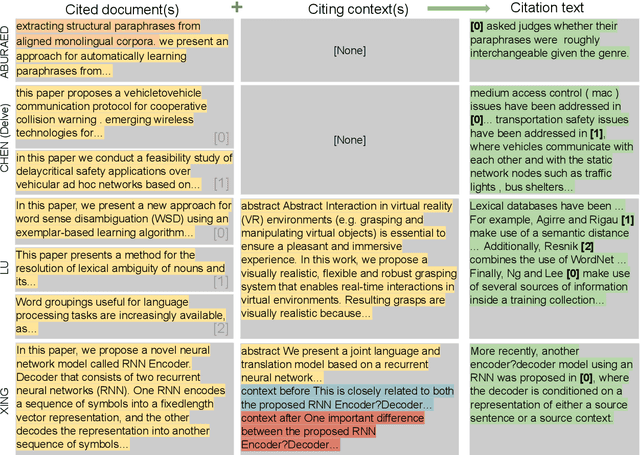

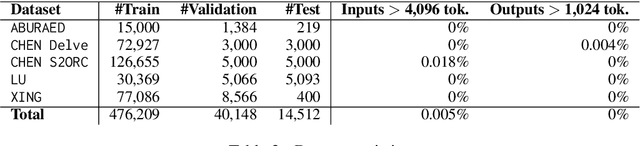
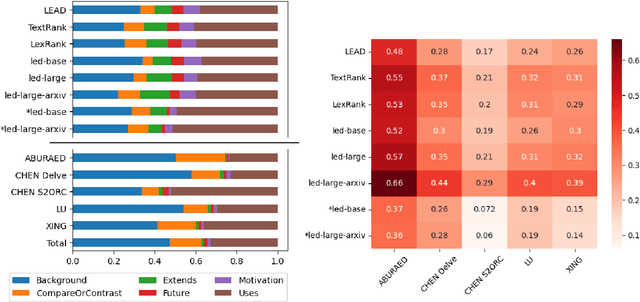
The publication rates are skyrocketing across many fields of science, and it is difficult to stay up to date with the latest research. This makes automatically summarizing the latest findings and helping scholars to synthesize related work in a given area an attractive research objective. In this paper we study the problem of citation text generation, where given a set of cited papers and citing context the model should generate a citation text. While citation text generation has been tackled in prior work, existing studies use different datasets and task definitions, which makes it hard to study citation text generation systematically. To address this, we propose CiteBench: a benchmark for citation text generation that unifies the previous datasets and enables standardized evaluation of citation text generation models across task settings and domains. Using the new benchmark, we investigate the performance of multiple strong baselines, test their transferability between the datasets, and deliver new insights into task definition and evaluation to guide the future research in citation text generation. We make CiteBench publicly available at https://github.com/UKPLab/citebench.
Missing Counter-Evidence Renders NLP Fact-Checking Unrealistic for Misinformation
Oct 25, 2022

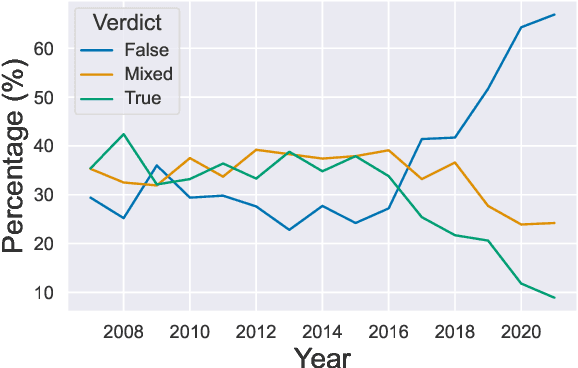
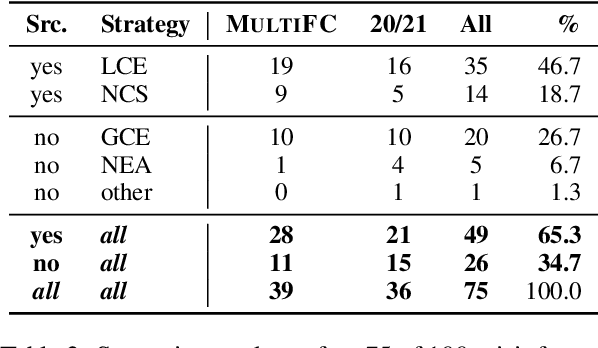
Misinformation emerges in times of uncertainty when credible information is limited. This is challenging for NLP-based fact-checking as it relies on counter-evidence, which may not yet be available. Despite increasing interest in automatic fact-checking, it is still unclear if automated approaches can realistically refute harmful real-world misinformation. Here, we contrast and compare NLP fact-checking with how professional fact-checkers combat misinformation in the absence of counter-evidence. In our analysis, we show that, by design, existing NLP task definitions for fact-checking cannot refute misinformation as professional fact-checkers do for the majority of claims. We then define two requirements that the evidence in datasets must fulfill for realistic fact-checking: It must be (1) sufficient to refute the claim and (2) not leaked from existing fact-checking articles. We survey existing fact-checking datasets and find that all of them fail to satisfy both criteria. Finally, we perform experiments to demonstrate that models trained on a large-scale fact-checking dataset rely on leaked evidence, which makes them unsuitable in real-world scenarios. Taken together, we show that current NLP fact-checking cannot realistically combat real-world misinformation because it depends on unrealistic assumptions about counter-evidence in the data.
NECE: Narrative Event Chain Extraction Toolkit
Aug 19, 2022
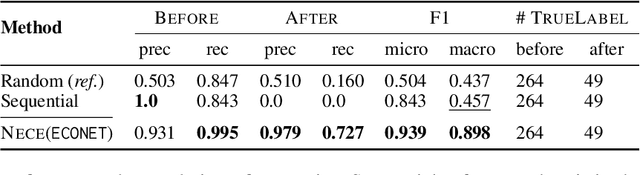
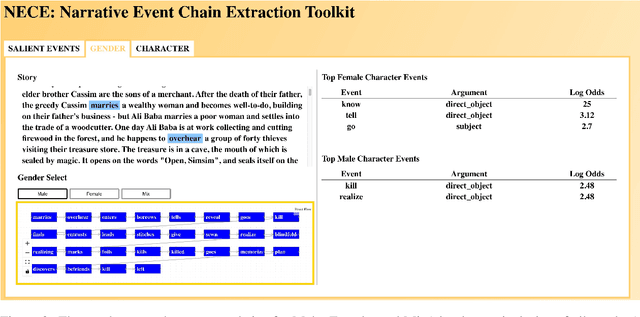
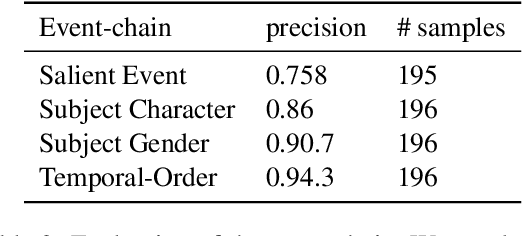
NECE is an event-based text analysis toolkit built for narrative documents. NECE aims to provide users open and easy accesses to an event-based summary and abstraction of long narrative documents through both a graphic interface and a python package, which can be readily used in narrative analysis, understanding, or other advanced purposes. Our work addresses the challenge of long passage events extraction and temporal ordering of key events; at the same time, it offers options to select and view events related to narrative entities, such as main characters and gender groups. We conduct human evaluation to demonstrate the quality of the event chain extraction system and character features mining algorithms. Lastly, we shed light on the toolkit's potential downstream applications by demonstrating its usage in gender bias analysis and Question-Answering tasks.