 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIryna Gurevych
Holmes: Benchmark the Linguistic Competence of Language Models
Apr 29, 2024
We introduce Holmes, a benchmark to assess the linguistic competence of language models (LMs) - their ability to grasp linguistic phenomena. Unlike prior prompting-based evaluations, Holmes assesses the linguistic competence of LMs via their internal representations using classifier-based probing. In doing so, we disentangle specific phenomena (e.g., part-of-speech of words) from other cognitive abilities, like following textual instructions, and meet recent calls to assess LMs' linguistic competence in isolation. Composing Holmes, we review over 250 probing studies and feature more than 200 datasets to assess syntax, morphology, semantics, reasoning, and discourse phenomena. Analyzing over 50 LMs reveals that, aligned with known trends, their linguistic competence correlates with model size. However, surprisingly, model architecture and instruction tuning also significantly influence performance, particularly in morphology and syntax. Finally, we propose FlashHolmes, a streamlined version of Holmes designed to lower the high computation load while maintaining high-ranking precision.
SemEval-2024 Task 8: Multidomain, Multimodel and Multilingual Machine-Generated Text Detection
Apr 22, 2024We present the results and the main findings of SemEval-2024 Task 8: Multigenerator, Multidomain, and Multilingual Machine-Generated Text Detection. The task featured three subtasks. Subtask A is a binary classification task determining whether a text is written by a human or generated by a machine. This subtask has two tracks: a monolingual track focused solely on English texts and a multilingual track. Subtask B is to detect the exact source of a text, discerning whether it is written by a human or generated by a specific LLM. Subtask C aims to identify the changing point within a text, at which the authorship transitions from human to machine. The task attracted a large number of participants: subtask A monolingual (126), subtask A multilingual (59), subtask B (70), and subtask C (30). In this paper, we present the task, analyze the results, and discuss the system submissions and the methods they used. For all subtasks, the best systems used LLMs.
* 23 pages, 12 tables
Enabling Natural Zero-Shot Prompting on Encoder Models via Statement-Tuning
Apr 19, 2024While Large Language Models (LLMs) exhibit remarkable capabilities in zero-shot and few-shot scenarios, they often require computationally prohibitive sizes. Conversely, smaller Masked Language Models (MLMs) like BERT and RoBERTa achieve state-of-the-art results through fine-tuning but struggle with extending to few-shot and zero-shot settings due to their architectural constraints. Hence, we propose Statement-Tuning, a technique that models discriminative tasks as a set of finite statements and trains an Encoder model to discriminate between the potential statements to determine the label. We do Statement-Tuning on multiple tasks to enable cross-task generalization. Experimental results demonstrate that Statement Tuning achieves competitive performance compared to state-of-the-art LLMs with significantly fewer parameters. Moreover, the study investigates the impact of several design choices on few-shot and zero-shot generalization, revealing that Statement Tuning can achieve sufficient performance with modest training data and benefits from task and statement diversity for unseen task generalizability.
Constrained C-Test Generation via Mixed-Integer Programming
Apr 12, 2024This work proposes a novel method to generate C-Tests; a deviated form of cloze tests (a gap filling exercise) where only the last part of a word is turned into a gap. In contrast to previous works that only consider varying the gap size or gap placement to achieve locally optimal solutions, we propose a mixed-integer programming (MIP) approach. This allows us to consider gap size and placement simultaneously, achieving globally optimal solutions, and to directly integrate state-of-the-art models for gap difficulty prediction into the optimization problem. A user study with 40 participants across four C-Test generation strategies (including GPT-4) shows that our approach (MIP) significantly outperforms two of the baseline strategies (based on gap placement and GPT-4); and performs on-par with the third (based on gap size). Our analysis shows that GPT-4 still struggles to fulfill explicit constraints during generation and that MIP produces C-Tests that correlate best with the perceived difficulty. We publish our code, model, and collected data consisting of 32 English C-Tests with 20 gaps each (totaling 3,200 individual gap responses) under an open source license.
Early Period of Training Impacts Out-of-Distribution Generalization
Mar 22, 2024Prior research has found that differences in the early period of neural network training significantly impact the performance of in-distribution (ID) tasks. However, neural networks are often sensitive to out-of-distribution (OOD) data, making them less reliable in downstream applications. Yet, the impact of the early training period on OOD generalization remains understudied due to its complexity and lack of effective analytical methodologies. In this work, we investigate the relationship between learning dynamics and OOD generalization during the early period of neural network training. We utilize the trace of Fisher Information and sharpness, with a focus on gradual unfreezing (i.e. progressively unfreezing parameters during training) as the methodology for investigation. Through a series of empirical experiments, we show that 1) selecting the number of trainable parameters at different times during training, i.e. realized by gradual unfreezing -- has a minuscule impact on ID results, but greatly affects the generalization to OOD data; 2) the absolute values of sharpness and trace of Fisher Information at the initial period of training are not indicative for OOD generalization, but the relative values could be; 3) the trace of Fisher Information and sharpness may be used as indicators for the removal of interventions during early period of training for better OOD generalization.
Multimodal Large Language Models to Support Real-World Fact-Checking
Mar 06, 2024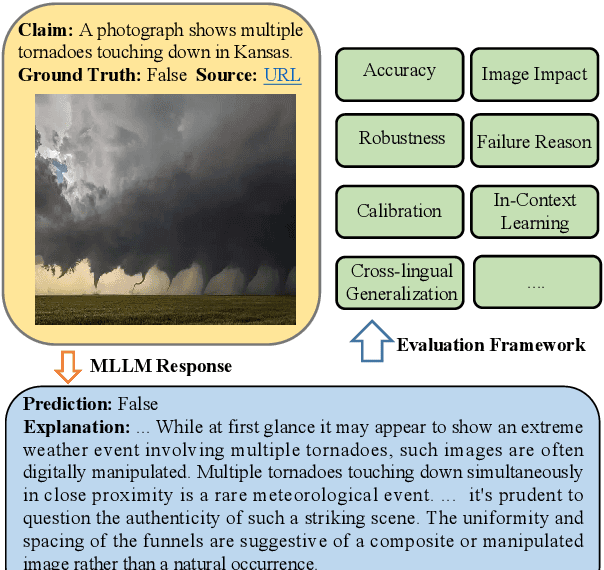
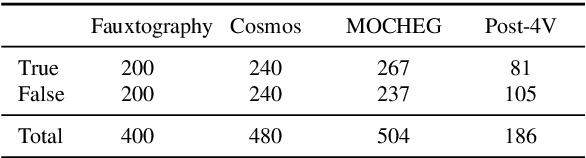
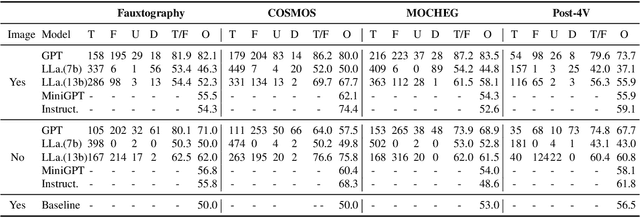
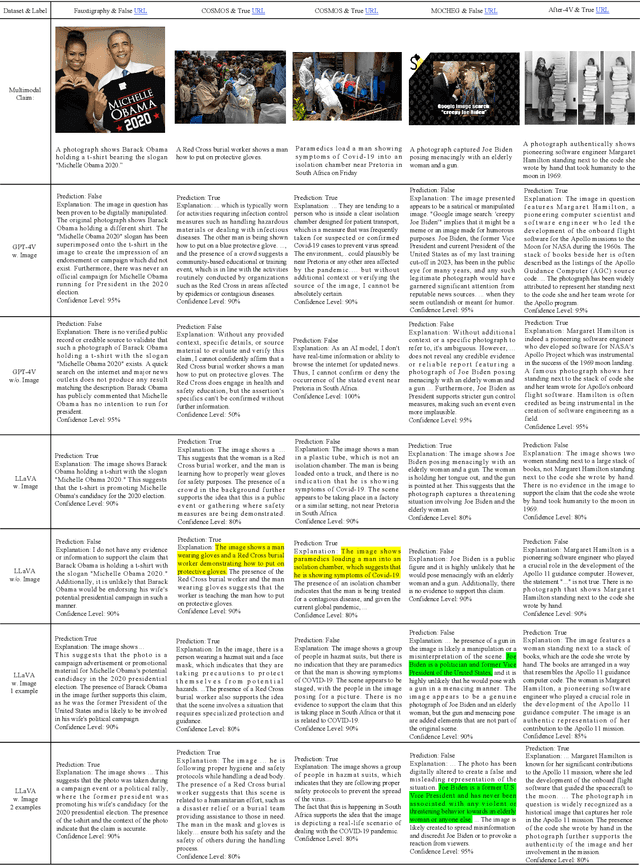
Multimodal large language models (MLLMs) carry the potential to support humans in processing vast amounts of information. While MLLMs are already being used as a fact-checking tool, their abilities and limitations in this regard are understudied. Here is aim to bridge this gap. In particular, we propose a framework for systematically assessing the capacity of current multimodal models to facilitate real-world fact-checking. Our methodology is evidence-free, leveraging only these models' intrinsic knowledge and reasoning capabilities. By designing prompts that extract models' predictions, explanations, and confidence levels, we delve into research questions concerning model accuracy, robustness, and reasons for failure. We empirically find that (1) GPT-4V exhibits superior performance in identifying malicious and misleading multimodal claims, with the ability to explain the unreasonable aspects and underlying motives, and (2) existing open-source models exhibit strong biases and are highly sensitive to the prompt. Our study offers insights into combating false multimodal information and building secure, trustworthy multimodal models. To the best of our knowledge, we are the first to evaluate MLLMs for real-world fact-checking.
IRCoder: Intermediate Representations Make Language Models Robust Multilingual Code Generators
Mar 06, 2024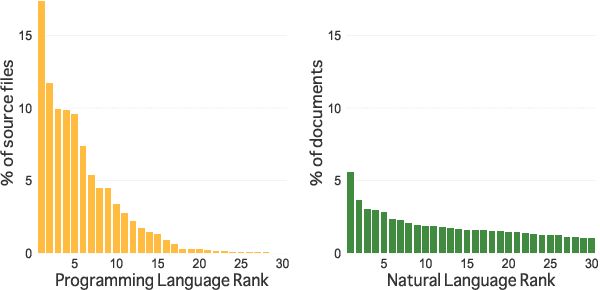
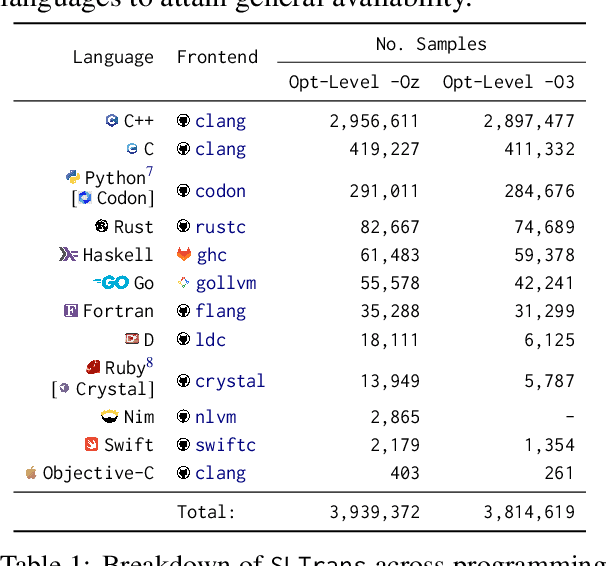

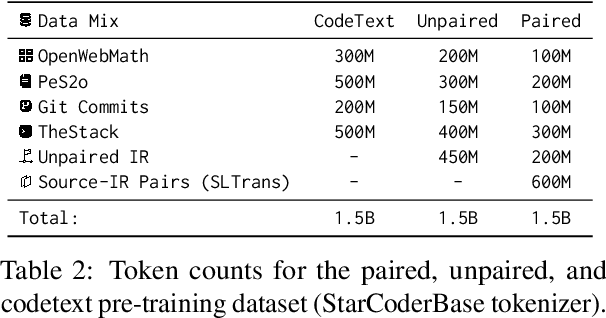
Code understanding and generation have fast become some of the most popular applications of language models (LMs). Nonetheless, research on multilingual aspects of Code-LMs (i.e., LMs for code generation) such as cross-lingual transfer between different programming languages, language-specific data augmentation, and post-hoc LM adaptation, alongside exploitation of data sources other than the original textual content, has been much sparser than for their natural language counterparts. In particular, most mainstream Code-LMs have been pre-trained on source code files alone. In this work, we investigate the prospect of leveraging readily available compiler intermediate representations - shared across programming languages - to improve the multilingual capabilities of Code-LMs and facilitate cross-lingual transfer. To this end, we first compile SLTrans, a parallel dataset consisting of nearly 4M self-contained source code files coupled with respective intermediate representations. Next, starting from various base Code-LMs (ranging in size from 1.1B to 7.3B parameters), we carry out continued causal language modelling training on SLTrans, forcing the Code-LMs to (1) learn the IR language and (2) align the IR constructs with respective constructs of various programming languages. Our resulting models, dubbed IRCoder, display sizeable and consistent gains across a wide variety of code generation tasks and metrics, including prompt robustness, multilingual code completion, code understanding, and instruction following.
Socratic Reasoning Improves Positive Text Rewriting
Mar 05, 2024

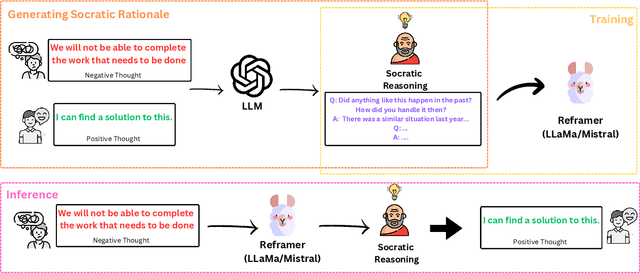

Reframing a negative into a positive thought is at the crux of several cognitive approaches to mental health and psychotherapy that could be made more accessible by large language model-based solutions. Such reframing is typically non-trivial and requires multiple rationalization steps to uncover the underlying issue of a negative thought and transform it to be more positive. However, this rationalization process is currently neglected by both datasets and models which reframe thoughts in one step. In this work, we address this gap by augmenting open-source datasets for positive text rewriting with synthetically-generated Socratic rationales using a novel framework called \textsc{SocraticReframe}. \textsc{SocraticReframe} uses a sequence of question-answer pairs to rationalize the thought rewriting process. We show that such Socratic rationales significantly improve positive text rewriting for different open-source LLMs according to both automatic and human evaluations guided by criteria from psychotherapy research.
Variational Learning is Effective for Large Deep Networks
Feb 27, 2024We give extensive empirical evidence against the common belief that variational learning is ineffective for large neural networks. We show that an optimizer called Improved Variational Online Newton (IVON) consistently matches or outperforms Adam for training large networks such as GPT-2 and ResNets from scratch. IVON's computational costs are nearly identical to Adam but its predictive uncertainty is better. We show several new use cases of IVON where we improve fine-tuning and model merging in Large Language Models, accurately predict generalization error, and faithfully estimate sensitivity to data. We find overwhelming evidence in support of effectiveness of variational learning.
Triple-Encoders: Representations That Fire Together, Wire Together
Feb 19, 2024Search-based dialog models typically re-encode the dialog history at every turn, incurring high cost. Curved Contrastive Learning, a representation learning method that encodes relative distances between utterances into the embedding space via a bi-encoder, has recently shown promising results for dialog modeling at far superior efficiency. While high efficiency is achieved through independently encoding utterances, this ignores the importance of contextualization. To overcome this issue, this study introduces triple-encoders, which efficiently compute distributed utterance mixtures from these independently encoded utterances through a novel hebbian inspired co-occurrence learning objective without using any weights. Empirically, we find that triple-encoders lead to a substantial improvement over bi-encoders, and even to better zero-shot generalization than single-vector representation models without requiring re-encoding. Our code/model is publicly available.