 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNizar Habash
The SAMER Arabic Text Simplification Corpus
Apr 29, 2024
We present the SAMER Corpus, the first manually annotated Arabic parallel corpus for text simplification targeting school-aged learners. Our corpus comprises texts of 159K words selected from 15 publicly available Arabic fiction novels most of which were published between 1865 and 1955. Our corpus includes readability level annotations at both the document and word levels, as well as two simplified parallel versions for each text targeting learners at two different readability levels. We describe the corpus selection process, and outline the guidelines we followed to create the annotations and ensure their quality. Our corpus is publicly available to support and encourage research on Arabic text simplification, Arabic automatic readability assessment, and the development of Arabic pedagogical language technologies.
Can a Multichoice Dataset be Repurposed for Extractive Question Answering?
Apr 26, 2024The rapid evolution of Natural Language Processing (NLP) has favored major languages such as English, leaving a significant gap for many others due to limited resources. This is especially evident in the context of data annotation, a task whose importance cannot be underestimated, but which is time-consuming and costly. Thus, any dataset for resource-poor languages is precious, in particular when it is task-specific. Here, we explore the feasibility of repurposing existing datasets for a new NLP task: we repurposed the Belebele dataset (Bandarkar et al., 2023), which was designed for multiple-choice question answering (MCQA), to enable extractive QA (EQA) in the style of machine reading comprehension. We present annotation guidelines and a parallel EQA dataset for English and Modern Standard Arabic (MSA). We also present QA evaluation results for several monolingual and cross-lingual QA pairs including English, MSA, and five Arabic dialects. Our aim is to enable others to adapt our approach for the 120+ other language variants in Belebele, many of which are deemed under-resourced. We also conduct a thorough analysis and share our insights from the process, which we hope will contribute to a deeper understanding of the challenges and the opportunities associated with task reformulation in NLP research.
SemEval-2024 Task 8: Multidomain, Multimodel and Multilingual Machine-Generated Text Detection
Apr 22, 2024We present the results and the main findings of SemEval-2024 Task 8: Multigenerator, Multidomain, and Multilingual Machine-Generated Text Detection. The task featured three subtasks. Subtask A is a binary classification task determining whether a text is written by a human or generated by a machine. This subtask has two tracks: a monolingual track focused solely on English texts and a multilingual track. Subtask B is to detect the exact source of a text, discerning whether it is written by a human or generated by a specific LLM. Subtask C aims to identify the changing point within a text, at which the authorship transitions from human to machine. The task attracted a large number of participants: subtask A monolingual (126), subtask A multilingual (59), subtask B (70), and subtask C (30). In this paper, we present the task, analyze the results, and discuss the system submissions and the methods they used. For all subtasks, the best systems used LLMs.
* 23 pages, 12 tables
ZAEBUC-Spoken: A Multilingual Multidialectal Arabic-English Speech Corpus
Mar 27, 2024



We present ZAEBUC-Spoken, a multilingual multidialectal Arabic-English speech corpus. The corpus comprises twelve hours of Zoom meetings involving multiple speakers role-playing a work situation where Students brainstorm ideas for a certain topic and then discuss it with an Interlocutor. The meetings cover different topics and are divided into phases with different language setups. The corpus presents a challenging set for automatic speech recognition (ASR), including two languages (Arabic and English) with Arabic spoken in multiple variants (Modern Standard Arabic, Gulf Arabic, and Egyptian Arabic) and English used with various accents. Adding to the complexity of the corpus, there is also code-switching between these languages and dialects. As part of our work, we take inspiration from established sets of transcription guidelines to present a set of guidelines handling issues of conversational speech, code-switching and orthography of both languages. We further enrich the corpus with two layers of annotations; (1) dialectness level annotation for the portion of the corpus where mixing occurs between different variants of Arabic, and (2) automatic morphological annotations, including tokenization, lemmatization, and part-of-speech tagging.
ArabicMMLU: Assessing Massive Multitask Language Understanding in Arabic
Feb 20, 2024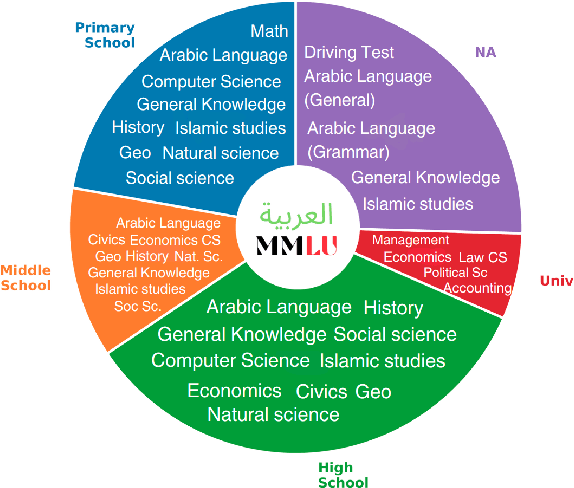


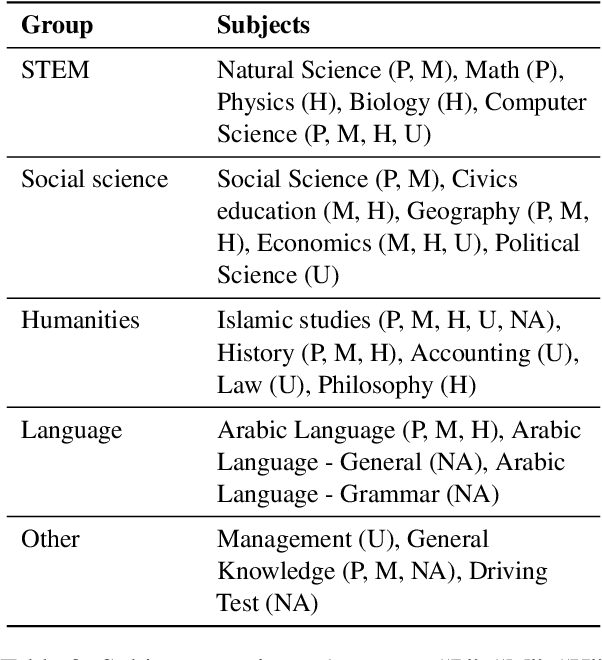
The focus of language model evaluation has transitioned towards reasoning and knowledge-intensive tasks, driven by advancements in pretraining large models. While state-of-the-art models are partially trained on large Arabic texts, evaluating their performance in Arabic remains challenging due to the limited availability of relevant datasets. To bridge this gap, we present ArabicMMLU, the first multi-task language understanding benchmark for Arabic language, sourced from school exams across diverse educational levels in different countries spanning North Africa, the Levant, and the Gulf regions. Our data comprises 40 tasks and 14,575 multiple-choice questions in Modern Standard Arabic (MSA), and is carefully constructed by collaborating with native speakers in the region. Our comprehensive evaluations of 35 models reveal substantial room for improvement, particularly among the best open-source models. Notably, BLOOMZ, mT0, LLama2, and Falcon struggle to achieve a score of 50%, while even the top-performing Arabic-centric model only achieves a score of 62.3%.
M4GT-Bench: Evaluation Benchmark for Black-Box Machine-Generated Text Detection
Feb 17, 2024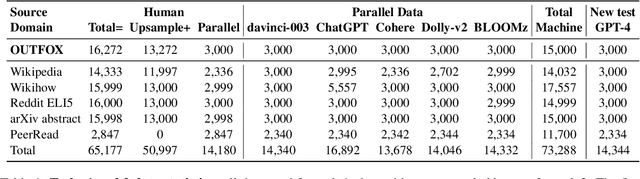

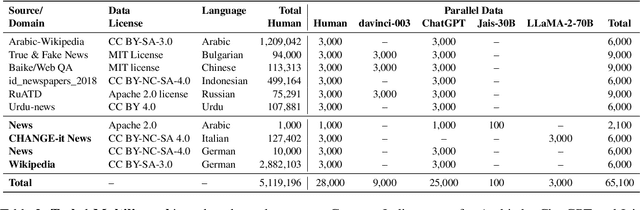

The advent of Large Language Models (LLMs) has brought an unprecedented surge in machine-generated text (MGT) across diverse channels. This raises legitimate concerns about its potential misuse and societal implications. The need to identify and differentiate such content from genuine human-generated text is critical in combating disinformation, preserving the integrity of education and scientific fields, and maintaining trust in communication. In this work, we address this problem by introducing a new benchmark involving multilingual, multi-domain and multi-generator for MGT detection -- M4GT-Bench. It is collected for three task formulations: (1) mono-lingual and multi-lingual binary MGT detection; (2) multi-way detection identifies which particular model generates the text; and (3) human-machine mixed text detection, where a word boundary delimiting MGT from human-written content should be determined. Human evaluation for Task 2 shows less than random guess performance, demonstrating the challenges to distinguish unique LLMs. Promising results always occur when training and test data distribute within the same domain or generators.
Cross-Lingual Transfer from Related Languages: Treating Low-Resource Maltese as Multilingual Code-Switching
Feb 03, 2024Although multilingual language models exhibit impressive cross-lingual transfer capabilities on unseen languages, the performance on downstream tasks is impacted when there is a script disparity with the languages used in the multilingual model's pre-training data. Using transliteration offers a straightforward yet effective means to align the script of a resource-rich language with a target language, thereby enhancing cross-lingual transfer capabilities. However, for mixed languages, this approach is suboptimal, since only a subset of the language benefits from the cross-lingual transfer while the remainder is impeded. In this work, we focus on Maltese, a Semitic language, with substantial influences from Arabic, Italian, and English, and notably written in Latin script. We present a novel dataset annotated with word-level etymology. We use this dataset to train a classifier that enables us to make informed decisions regarding the appropriate processing of each token in the Maltese language. We contrast indiscriminate transliteration or translation to mixing processing pipelines that only transliterate words of Arabic origin, thereby resulting in text with a mixture of scripts. We fine-tune the processed data on four downstream tasks and show that conditional transliteration based on word etymology yields the best results, surpassing fine-tuning with raw Maltese or Maltese processed with non-selective pipelines.
Computational Morphology and Lexicography Modeling of Modern Standard Arabic Nominals
Feb 01, 2024Modern Standard Arabic (MSA) nominals present many morphological and lexical modeling challenges that have not been consistently addressed previously. This paper attempts to define the space of such challenges, and leverage a recently proposed morphological framework to build a comprehensive and extensible model for MSA nominals. Our model design addresses the nominals' intricate morphotactics, as well as their paradigmatic irregularities. Our implementation showcases enhanced accuracy and consistency compared to a commonly used MSA morphological analyzer and generator. We make our models publicly available.
NADI 2023: The Fourth Nuanced Arabic Dialect Identification Shared Task
Oct 24, 2023We describe the findings of the fourth Nuanced Arabic Dialect Identification Shared Task (NADI 2023). The objective of NADI is to help advance state-of-the-art Arabic NLP by creating opportunities for teams of researchers to collaboratively compete under standardized conditions. It does so with a focus on Arabic dialects, offering novel datasets and defining subtasks that allow for meaningful comparisons between different approaches. NADI 2023 targeted both dialect identification (Subtask 1) and dialect-to-MSA machine translation (Subtask 2 and Subtask 3). A total of 58 unique teams registered for the shared task, of whom 18 teams have participated (with 76 valid submissions during test phase). Among these, 16 teams participated in Subtask 1, 5 participated in Subtask 2, and 3 participated in Subtask 3. The winning teams achieved 87.27 F1 on Subtask 1, 14.76 Bleu in Subtask 2, and 21.10 Bleu in Subtask 3, respectively. Results show that all three subtasks remain challenging, thereby motivating future work in this area. We describe the methods employed by the participating teams and briefly offer an outlook for NADI.
Data Augmentation Techniques for Machine Translation of Code-Switched Texts: A Comparative Study
Oct 23, 2023Code-switching (CSW) text generation has been receiving increasing attention as a solution to address data scarcity. In light of this growing interest, we need more comprehensive studies comparing different augmentation approaches. In this work, we compare three popular approaches: lexical replacements, linguistic theories, and back-translation (BT), in the context of Egyptian Arabic-English CSW. We assess the effectiveness of the approaches on machine translation and the quality of augmentations through human evaluation. We show that BT and CSW predictive-based lexical replacement, being trained on CSW parallel data, perform best on both tasks. Linguistic theories and random lexical replacement prove to be effective in the lack of CSW parallel data, where both approaches achieve similar results.