 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAkim Tsvigun
SemEval-2024 Task 8: Multidomain, Multimodel and Multilingual Machine-Generated Text Detection
Apr 22, 2024
We present the results and the main findings of SemEval-2024 Task 8: Multigenerator, Multidomain, and Multilingual Machine-Generated Text Detection. The task featured three subtasks. Subtask A is a binary classification task determining whether a text is written by a human or generated by a machine. This subtask has two tracks: a monolingual track focused solely on English texts and a multilingual track. Subtask B is to detect the exact source of a text, discerning whether it is written by a human or generated by a specific LLM. Subtask C aims to identify the changing point within a text, at which the authorship transitions from human to machine. The task attracted a large number of participants: subtask A monolingual (126), subtask A multilingual (59), subtask B (70), and subtask C (30). In this paper, we present the task, analyze the results, and discuss the system submissions and the methods they used. For all subtasks, the best systems used LLMs.
* 23 pages, 12 tables
M4GT-Bench: Evaluation Benchmark for Black-Box Machine-Generated Text Detection
Feb 17, 2024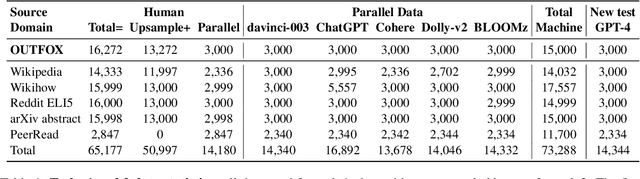

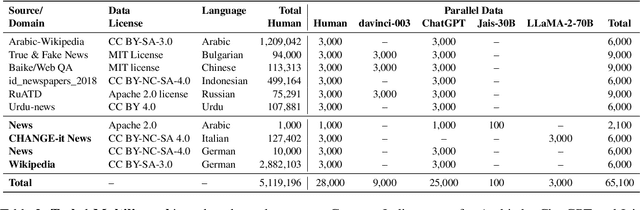

The advent of Large Language Models (LLMs) has brought an unprecedented surge in machine-generated text (MGT) across diverse channels. This raises legitimate concerns about its potential misuse and societal implications. The need to identify and differentiate such content from genuine human-generated text is critical in combating disinformation, preserving the integrity of education and scientific fields, and maintaining trust in communication. In this work, we address this problem by introducing a new benchmark involving multilingual, multi-domain and multi-generator for MGT detection -- M4GT-Bench. It is collected for three task formulations: (1) mono-lingual and multi-lingual binary MGT detection; (2) multi-way detection identifies which particular model generates the text; and (3) human-machine mixed text detection, where a word boundary delimiting MGT from human-written content should be determined. Human evaluation for Task 2 shows less than random guess performance, demonstrating the challenges to distinguish unique LLMs. Promising results always occur when training and test data distribute within the same domain or generators.
LM-Polygraph: Uncertainty Estimation for Language Models
Nov 13, 2023Recent advancements in the capabilities of large language models (LLMs) have paved the way for a myriad of groundbreaking applications in various fields. However, a significant challenge arises as these models often "hallucinate", i.e., fabricate facts without providing users an apparent means to discern the veracity of their statements. Uncertainty estimation (UE) methods are one path to safer, more responsible, and more effective use of LLMs. However, to date, research on UE methods for LLMs has been focused primarily on theoretical rather than engineering contributions. In this work, we tackle this issue by introducing LM-Polygraph, a framework with implementations of a battery of state-of-the-art UE methods for LLMs in text generation tasks, with unified program interfaces in Python. Additionally, it introduces an extendable benchmark for consistent evaluation of UE techniques by researchers, and a demo web application that enriches the standard chat dialog with confidence scores, empowering end-users to discern unreliable responses. LM-Polygraph is compatible with the most recent LLMs, including BLOOMz, LLaMA-2, ChatGPT, and GPT-4, and is designed to support future releases of similarly-styled LMs.
M4: Multi-generator, Multi-domain, and Multi-lingual Black-Box Machine-Generated Text Detection
May 24, 2023



Large language models (LLMs) have demonstrated remarkable capability to generate fluent responses to a wide variety of user queries, but this has also resulted in concerns regarding the potential misuse of such texts in journalism, educational, and academic context. In this work, we aim to develop automatic systems to identify machine-generated text and to detect potential misuse. We first introduce a large-scale benchmark M4, which is multi-generator, multi-domain, and multi-lingual corpus for machine-generated text detection. Using the dataset, we experiment with a number of methods and we show that it is challenging for detectors to generalize well on unseen examples if they are either from different domains or are generated by different large language models. In such cases, detectors tend to misclassify machine-generated text as human-written. These results show that the problem is far from solved and there is a lot of room for improvement. We believe that our dataset M4, which covers different generators, domains and languages, will enable future research towards more robust approaches for this pressing societal problem. The M4 dataset is available at https://github.com/mbzuai-nlp/M4.
Active Learning for Abstractive Text Summarization
Jan 09, 2023



Construction of human-curated annotated datasets for abstractive text summarization (ATS) is very time-consuming and expensive because creating each instance requires a human annotator to read a long document and compose a shorter summary that would preserve the key information relayed by the original document. Active Learning (AL) is a technique developed to reduce the amount of annotation required to achieve a certain level of machine learning model performance. In information extraction and text classification, AL can reduce the amount of labor up to multiple times. Despite its potential for aiding expensive annotation, as far as we know, there were no effective AL query strategies for ATS. This stems from the fact that many AL strategies rely on uncertainty estimation, while as we show in our work, uncertain instances are usually noisy, and selecting them can degrade the model performance compared to passive annotation. We address this problem by proposing the first effective query strategy for AL in ATS based on diversity principles. We show that given a certain annotation budget, using our strategy in AL annotation helps to improve the model performance in terms of ROUGE and consistency scores. Additionally, we analyze the effect of self-learning and show that it can further increase the performance of the model.
Towards Computationally Feasible Deep Active Learning
May 07, 2022



Active learning (AL) is a prominent technique for reducing the annotation effort required for training machine learning models. Deep learning offers a solution for several essential obstacles to deploying AL in practice but introduces many others. One of such problems is the excessive computational resources required to train an acquisition model and estimate its uncertainty on instances in the unlabeled pool. We propose two techniques that tackle this issue for text classification and tagging tasks, offering a substantial reduction of AL iteration duration and the computational overhead introduced by deep acquisition models in AL. We also demonstrate that our algorithm that leverages pseudo-labeling and distilled models overcomes one of the essential obstacles revealed previously in the literature. Namely, it was shown that due to differences between an acquisition model used to select instances during AL and a successor model trained on the labeled data, the benefits of AL can diminish. We show that our algorithm, despite using a smaller and faster acquisition model, is capable of training a more expressive successor model with higher performance.