 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRio Yokota
Continual Pre-Training for Cross-Lingual LLM Adaptation: Enhancing Japanese Language Capabilities
Apr 27, 2024
Cross-lingual continual pre-training of large language models (LLMs) initially trained on English corpus allows us to leverage the vast amount of English language resources and reduce the pre-training cost. In this study, we constructed Swallow, an LLM with enhanced Japanese capability, by extending the vocabulary of Llama 2 to include Japanese characters and conducting continual pre-training on a large Japanese web corpus. Experimental results confirmed that the performance on Japanese tasks drastically improved through continual pre-training, and the performance monotonically increased with the amount of training data up to 100B tokens. Consequently, Swallow achieved superior performance compared to other LLMs that were trained from scratch in English and Japanese. An analysis of the effects of continual pre-training revealed that it was particularly effective for Japanese question answering tasks. Furthermore, to elucidate effective methodologies for cross-lingual continual pre-training from English to Japanese, we investigated the impact of vocabulary expansion and the effectiveness of incorporating parallel corpora. The results showed that the efficiency gained through vocabulary expansion had no negative impact on performance, except for the summarization task, and that the combined use of parallel corpora enhanced translation ability.
Building a Large Japanese Web Corpus for Large Language Models
Apr 27, 2024Open Japanese large language models (LLMs) have been trained on the Japanese portions of corpora such as CC-100, mC4, and OSCAR. However, these corpora were not created for the quality of Japanese texts. This study builds a large Japanese web corpus by extracting and refining text from the Common Crawl archive (21 snapshots of approximately 63.4 billion pages crawled between 2020 and 2023). This corpus consists of approximately 312.1 billion characters (approximately 173 million pages), which is the largest of all available training corpora for Japanese LLMs, surpassing CC-100 (approximately 25.8 billion characters), mC4 (approximately 239.7 billion characters) and OSCAR 23.10 (approximately 74 billion characters). To confirm the quality of the corpus, we performed continual pre-training on Llama 2 7B, 13B, 70B, Mistral 7B v0.1, and Mixtral 8x7B Instruct as base LLMs and gained consistent (6.6-8.1 points) improvements on Japanese benchmark datasets. We also demonstrate that the improvement on Llama 2 13B brought from the presented corpus was the largest among those from other existing corpora.
Aurora-M: The First Open Source Multilingual Language Model Red-teamed according to the U.S. Executive Order
Mar 30, 2024Pretrained language models underpin several AI applications, but their high computational cost for training limits accessibility. Initiatives such as BLOOM and StarCoder aim to democratize access to pretrained models for collaborative community development. However, such existing models face challenges: limited multilingual capabilities, continual pretraining causing catastrophic forgetting, whereas pretraining from scratch is computationally expensive, and compliance with AI safety and development laws. This paper presents Aurora-M, a 15B parameter multilingual open-source model trained on English, Finnish, Hindi, Japanese, Vietnamese, and code. Continually pretrained from StarCoderPlus on 435 billion additional tokens, Aurora-M surpasses 2 trillion tokens in total training token count. It is the first open-source multilingual model fine-tuned on human-reviewed safety instructions, thus aligning its development not only with conventional red-teaming considerations, but also with the specific concerns articulated in the Biden-Harris Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence. Aurora-M is rigorously evaluated across various tasks and languages, demonstrating robustness against catastrophic forgetting and outperforming alternatives in multilingual settings, particularly in safety evaluations. To promote responsible open-source LLM development, Aurora-M and its variants are released at https://huggingface.co/collections/aurora-m/aurora-m-models-65fdfdff62471e09812f5407 .
Variational Learning is Effective for Large Deep Networks
Feb 27, 2024We give extensive empirical evidence against the common belief that variational learning is ineffective for large neural networks. We show that an optimizer called Improved Variational Online Newton (IVON) consistently matches or outperforms Adam for training large networks such as GPT-2 and ResNets from scratch. IVON's computational costs are nearly identical to Adam but its predictive uncertainty is better. We show several new use cases of IVON where we improve fine-tuning and model merging in Large Language Models, accurately predict generalization error, and faithfully estimate sensitivity to data. We find overwhelming evidence in support of effectiveness of variational learning.
SegRCDB: Semantic Segmentation via Formula-Driven Supervised Learning
Sep 29, 2023Pre-training is a strong strategy for enhancing visual models to efficiently train them with a limited number of labeled images. In semantic segmentation, creating annotation masks requires an intensive amount of labor and time, and therefore, a large-scale pre-training dataset with semantic labels is quite difficult to construct. Moreover, what matters in semantic segmentation pre-training has not been fully investigated. In this paper, we propose the Segmentation Radial Contour DataBase (SegRCDB), which for the first time applies formula-driven supervised learning for semantic segmentation. SegRCDB enables pre-training for semantic segmentation without real images or any manual semantic labels. SegRCDB is based on insights about what is important in pre-training for semantic segmentation and allows efficient pre-training. Pre-training with SegRCDB achieved higher mIoU than the pre-training with COCO-Stuff for fine-tuning on ADE-20k and Cityscapes with the same number of training images. SegRCDB has a high potential to contribute to semantic segmentation pre-training and investigation by enabling the creation of large datasets without manual annotation. The SegRCDB dataset will be released under a license that allows research and commercial use. Code is available at: https://github.com/dahlian00/SegRCDB
Pre-training Vision Transformers with Very Limited Synthesized Images
Jul 31, 2023
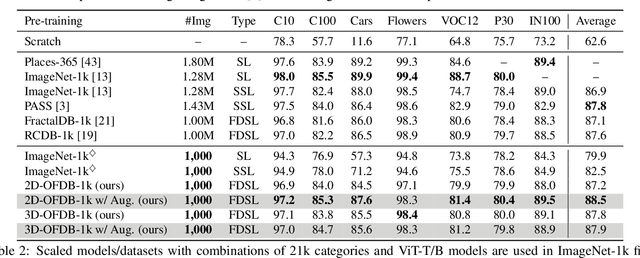
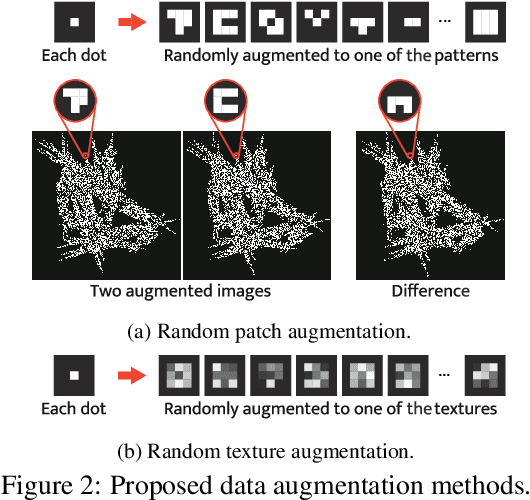

Formula-driven supervised learning (FDSL) is a pre-training method that relies on synthetic images generated from mathematical formulae such as fractals. Prior work on FDSL has shown that pre-training vision transformers on such synthetic datasets can yield competitive accuracy on a wide range of downstream tasks. These synthetic images are categorized according to the parameters in the mathematical formula that generate them. In the present work, we hypothesize that the process for generating different instances for the same category in FDSL, can be viewed as a form of data augmentation. We validate this hypothesis by replacing the instances with data augmentation, which means we only need a single image per category. Our experiments shows that this one-instance fractal database (OFDB) performs better than the original dataset where instances were explicitly generated. We further scale up OFDB to 21,000 categories and show that it matches, or even surpasses, the model pre-trained on ImageNet-21k in ImageNet-1k fine-tuning. The number of images in OFDB is 21k, whereas ImageNet-21k has 14M. This opens new possibilities for pre-training vision transformers with much smaller datasets.
ASDL: A Unified Interface for Gradient Preconditioning in PyTorch
May 08, 2023



Gradient preconditioning is a key technique to integrate the second-order information into gradients for improving and extending gradient-based learning algorithms. In deep learning, stochasticity, nonconvexity, and high dimensionality lead to a wide variety of gradient preconditioning methods, with implementation complexity and inconsistent performance and feasibility. We propose the Automatic Second-order Differentiation Library (ASDL), an extension library for PyTorch, which offers various implementations and a plug-and-play unified interface for gradient preconditioning. ASDL enables the study and structured comparison of a range of gradient preconditioning methods.
Visual Atoms: Pre-training Vision Transformers with Sinusoidal Waves
Mar 02, 2023

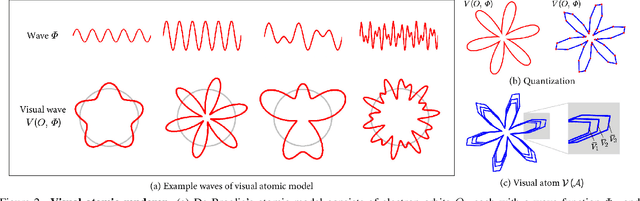

Formula-driven supervised learning (FDSL) has been shown to be an effective method for pre-training vision transformers, where ExFractalDB-21k was shown to exceed the pre-training effect of ImageNet-21k. These studies also indicate that contours mattered more than textures when pre-training vision transformers. However, the lack of a systematic investigation as to why these contour-oriented synthetic datasets can achieve the same accuracy as real datasets leaves much room for skepticism. In the present work, we develop a novel methodology based on circular harmonics for systematically investigating the design space of contour-oriented synthetic datasets. This allows us to efficiently search the optimal range of FDSL parameters and maximize the variety of synthetic images in the dataset, which we found to be a critical factor. When the resulting new dataset VisualAtom-21k is used for pre-training ViT-Base, the top-1 accuracy reached 83.7% when fine-tuning on ImageNet-1k. This is close to the top-1 accuracy (84.2%) achieved by JFT-300M pre-training, while the number of images is 1/14. Unlike JFT-300M which is a static dataset, the quality of synthetic datasets will continue to improve, and the current work is a testament to this possibility. FDSL is also free of the common issues associated with real images, e.g. privacy/copyright issues, labeling costs/errors, and ethical biases.
Informative Sample-Aware Proxy for Deep Metric Learning
Nov 18, 2022



Among various supervised deep metric learning methods proxy-based approaches have achieved high retrieval accuracies. Proxies, which are class-representative points in an embedding space, receive updates based on proxy-sample similarities in a similar manner to sample representations. In existing methods, a relatively small number of samples can produce large gradient magnitudes (ie, hard samples), and a relatively large number of samples can produce small gradient magnitudes (ie, easy samples); these can play a major part in updates. Assuming that acquiring too much sensitivity to such extreme sets of samples would deteriorate the generalizability of a method, we propose a novel proxy-based method called Informative Sample-Aware Proxy (Proxy-ISA), which directly modifies a gradient weighting factor for each sample using a scheduled threshold function, so that the model is more sensitive to the informative samples. Extensive experiments on the CUB-200-2011, Cars-196, Stanford Online Products and In-shop Clothes Retrieval datasets demonstrate the superiority of Proxy-ISA compared with the state-of-the-art methods.
Empirical Study on Optimizer Selection for Out-of-Distribution Generalization
Nov 18, 2022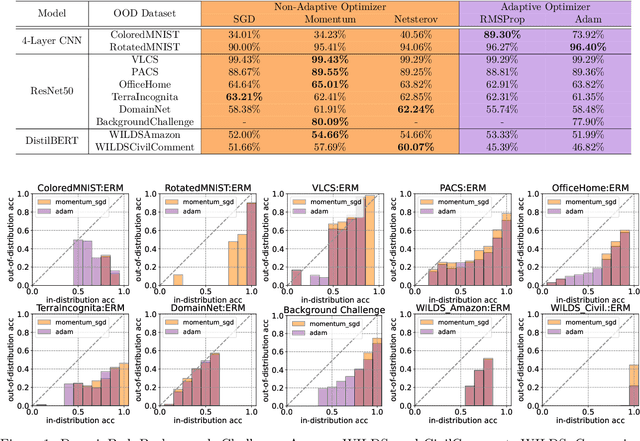
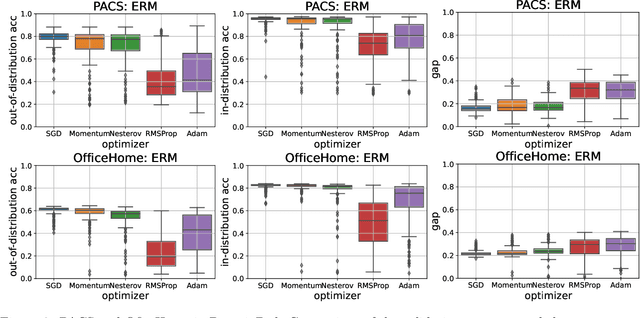

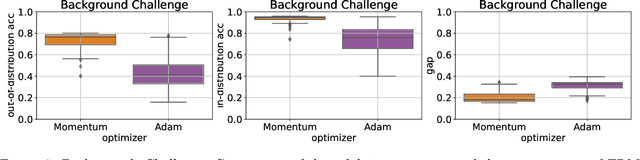
Modern deep learning systems are fragile and do not generalize well under distribution shifts. While much promising work has been accomplished to address these concerns, a systematic study of the role of optimizers and their out-of-distribution generalization performance has not been undertaken. In this study, we examine the performance of popular first-order optimizers for different classes of distributional shift under empirical risk minimization and invariant risk minimization. We address the problem settings for image and text classification using DomainBed, WILDS, and Backgrounds Challenge as out-of-distribution datasets for the exhaustive study. We search over a wide range of hyperparameters and examine the classification accuracy (in-distribution and out-of-distribution) for over 20,000 models. We arrive at the following findings: i) contrary to conventional wisdom, adaptive optimizers (e.g., Adam) perform worse than non-adaptive optimizers (e.g., SGD, momentum-based SGD), ii) in-distribution performance and out-of-distribution performance exhibit three types of behavior depending on the dataset - linear returns, increasing returns, and diminishing returns. We believe these findings can help practitioners choose the right optimizer and know what behavior to expect.