 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZiyang Luo
CofiPara: A Coarse-to-fine Paradigm for Multimodal Sarcasm Target Identification with Large Multimodal Models
May 01, 2024
Social media abounds with multimodal sarcasm, and identifying sarcasm targets is particularly challenging due to the implicit incongruity not directly evident in the text and image modalities. Current methods for Multimodal Sarcasm Target Identification (MSTI) predominantly focus on superficial indicators in an end-to-end manner, overlooking the nuanced understanding of multimodal sarcasm conveyed through both the text and image. This paper proposes a versatile MSTI framework with a coarse-to-fine paradigm, by augmenting sarcasm explainability with reasoning and pre-training knowledge. Inspired by the powerful capacity of Large Multimodal Models (LMMs) on multimodal reasoning, we first engage LMMs to generate competing rationales for coarser-grained pre-training of a small language model on multimodal sarcasm detection. We then propose fine-tuning the model for finer-grained sarcasm target identification. Our framework is thus empowered to adeptly unveil the intricate targets within multimodal sarcasm and mitigate the negative impact posed by potential noise inherently in LMMs. Experimental results demonstrate that our model far outperforms state-of-the-art MSTI methods, and markedly exhibits explainability in deciphering sarcasm as well.
CodeHalu: Code Hallucinations in LLMs Driven by Execution-based Verification
Apr 30, 2024Large Language Models (LLMs) have made significant advancements in the field of code generation, offering unprecedented support for automated programming and assisting developers. However, LLMs sometimes generate code that appears plausible but fails to meet the expected requirements or executes incorrectly. This phenomenon of hallucinations in the coding field has not been explored. To advance the community's understanding and research on code hallucinations in LLMs, we propose a definition method for these hallucinations based on execution verification and introduce the concept of code hallucinations for the first time. We categorize code hallucinations into four main types: mapping, naming, resource, and logic hallucinations, each further divided into different subcategories to better understand and address the unique challenges faced by LLMs during code generation. To systematically evaluate code hallucinations, we propose a dynamic detection algorithm for code hallucinations and construct the CodeHalu benchmark, which includes 8,883 samples from 699 tasks, to actively detect hallucination phenomena in LLMs during programming. We tested 16 popular LLMs on this benchmark to evaluate the frequency and nature of their hallucinations during code generation. The findings reveal significant variations in the accuracy and reliability of LLMs in generating code, highlighting the urgent need to improve models and training methods to ensure the functional correctness and safety of automatically generated code. This study not only classifies and quantifies code hallucinations but also provides insights for future improvements in LLM-based code generation research. The CodeHalu benchmark and code are publicly available at https://github.com/yuchen814/CodeHalu.
MMCode: Evaluating Multi-Modal Code Large Language Models with Visually Rich Programming Problems
Apr 15, 2024Programming often involves converting detailed and complex specifications into code, a process during which developers typically utilize visual aids to more effectively convey concepts. While recent developments in Large Multimodal Models have demonstrated remarkable abilities in visual reasoning and mathematical tasks, there is little work on investigating whether these models can effectively interpret visual elements for code generation. To this end, we present MMCode, the first multi-modal coding dataset for evaluating algorithmic problem-solving skills in visually rich contexts. MMCode contains 3,548 questions and 6,620 images collected from real-world programming challenges harvested from 10 code competition websites, presenting significant challenges due to the extreme demand for reasoning abilities. Our experiment results show that current state-of-the-art models struggle to solve these problems. The results highlight the lack of powerful vision-code models, and we hope MMCode can serve as an inspiration for future works in this domain. The data and code are publicly available at https://github.com/happylkx/MMCode.
Aurora-M: The First Open Source Multilingual Language Model Red-teamed according to the U.S. Executive Order
Mar 30, 2024Pretrained language models underpin several AI applications, but their high computational cost for training limits accessibility. Initiatives such as BLOOM and StarCoder aim to democratize access to pretrained models for collaborative community development. However, such existing models face challenges: limited multilingual capabilities, continual pretraining causing catastrophic forgetting, whereas pretraining from scratch is computationally expensive, and compliance with AI safety and development laws. This paper presents Aurora-M, a 15B parameter multilingual open-source model trained on English, Finnish, Hindi, Japanese, Vietnamese, and code. Continually pretrained from StarCoderPlus on 435 billion additional tokens, Aurora-M surpasses 2 trillion tokens in total training token count. It is the first open-source multilingual model fine-tuned on human-reviewed safety instructions, thus aligning its development not only with conventional red-teaming considerations, but also with the specific concerns articulated in the Biden-Harris Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence. Aurora-M is rigorously evaluated across various tasks and languages, demonstrating robustness against catastrophic forgetting and outperforming alternatives in multilingual settings, particularly in safety evaluations. To promote responsible open-source LLM development, Aurora-M and its variants are released at https://huggingface.co/collections/aurora-m/aurora-m-models-65fdfdff62471e09812f5407 .
Towards Explainable Harmful Meme Detection through Multimodal Debate between Large Language Models
Jan 24, 2024The age of social media is flooded with Internet memes, necessitating a clear grasp and effective identification of harmful ones. This task presents a significant challenge due to the implicit meaning embedded in memes, which is not explicitly conveyed through the surface text and image. However, existing harmful meme detection methods do not present readable explanations that unveil such implicit meaning to support their detection decisions. In this paper, we propose an explainable approach to detect harmful memes, achieved through reasoning over conflicting rationales from both harmless and harmful positions. Specifically, inspired by the powerful capacity of Large Language Models (LLMs) on text generation and reasoning, we first elicit multimodal debate between LLMs to generate the explanations derived from the contradictory arguments. Then we propose to fine-tune a small language model as the debate judge for harmfulness inference, to facilitate multimodal fusion between the harmfulness rationales and the intrinsic multimodal information within memes. In this way, our model is empowered to perform dialectical reasoning over intricate and implicit harm-indicative patterns, utilizing multimodal explanations originating from both harmless and harmful arguments. Extensive experiments on three public meme datasets demonstrate that our harmful meme detection approach achieves much better performance than state-of-the-art methods and exhibits a superior capacity for explaining the meme harmfulness of the model predictions.
* The first work towards explainable harmful meme detection by harnessing advanced LLMs
GOAT-Bench: Safety Insights to Large Multimodal Models through Meme-Based Social Abuse
Jan 07, 2024The exponential growth of social media has profoundly transformed how information is created, disseminated, and absorbed, exceeding any precedent in the digital age. Regrettably, this explosion has also spawned a significant increase in the online abuse of memes. Evaluating the negative impact of memes is notably challenging, owing to their often subtle and implicit meanings, which are not directly conveyed through the overt text and imagery. In light of this, large multimodal models (LMMs) have emerged as a focal point of interest due to their remarkable capabilities in handling diverse multimodal tasks. In response to this development, our paper aims to thoroughly examine the capacity of various LMMs (e.g. GPT-4V) to discern and respond to the nuanced aspects of social abuse manifested in memes. We introduce the comprehensive meme benchmark, GOAT-Bench, comprising over 6K varied memes encapsulating themes such as implicit hate speech, sexism, and cyberbullying, etc. Utilizing GOAT-Bench, we delve into the ability of LMMs to accurately assess hatefulness, misogyny, offensiveness, sarcasm, and harmful content. Our extensive experiments across a range of LMMs reveal that current models still exhibit a deficiency in safety awareness, showing insensitivity to various forms of implicit abuse. We posit that this shortfall represents a critical impediment to the realization of safe artificial intelligence. The GOAT-Bench and accompanying resources are publicly accessible at https://goatlmm.github.io/, contributing to ongoing research in this vital field.
Beneath the Surface: Unveiling Harmful Memes with Multimodal Reasoning Distilled from Large Language Models
Dec 09, 2023The age of social media is rife with memes. Understanding and detecting harmful memes pose a significant challenge due to their implicit meaning that is not explicitly conveyed through the surface text and image. However, existing harmful meme detection approaches only recognize superficial harm-indicative signals in an end-to-end classification manner but ignore in-depth cognition of the meme text and image. In this paper, we attempt to detect harmful memes based on advanced reasoning over the interplay of multimodal information in memes. Inspired by the success of Large Language Models (LLMs) on complex reasoning, we first conduct abductive reasoning with LLMs. Then we propose a novel generative framework to learn reasonable thoughts from LLMs for better multimodal fusion and lightweight fine-tuning, which consists of two training stages: 1) Distill multimodal reasoning knowledge from LLMs; and 2) Fine-tune the generative framework to infer harmfulness. Extensive experiments conducted on three meme datasets demonstrate that our proposed approach achieves superior performance than state-of-the-art methods on the harmful meme detection task.
* The first work to alleviate the issue of superficial understanding for harmful meme detection by explicitly utilizing commonsense knowledge, from a fresh perspective on harnessing advanced Large Language Models
VSCode: General Visual Salient and Camouflaged Object Detection with 2D Prompt Learning
Nov 25, 2023Salient object detection (SOD) and camouflaged object detection (COD) are related yet distinct binary mapping tasks. These tasks involve multiple modalities, sharing commonalities and unique cues. Existing research often employs intricate task-specific specialist models, potentially leading to redundancy and suboptimal results. We introduce VSCode, a generalist model with novel 2D prompt learning, to jointly address four SOD tasks and three COD tasks. We utilize VST as the foundation model and introduce 2D prompts within the encoder-decoder architecture to learn domain and task-specific knowledge on two separate dimensions. A prompt discrimination loss helps disentangle peculiarities to benefit model optimization. VSCode outperforms state-of-the-art methods across six tasks on 26 datasets and exhibits zero-shot generalization to unseen tasks by combining 2D prompts, such as RGB-D COD.
VST++: Efficient and Stronger Visual Saliency Transformer
Oct 18, 2023While previous CNN-based models have exhibited promising results for salient object detection (SOD), their ability to explore global long-range dependencies is restricted. Our previous work, the Visual Saliency Transformer (VST), addressed this constraint from a transformer-based sequence-to-sequence perspective, to unify RGB and RGB-D SOD. In VST, we developed a multi-task transformer decoder that concurrently predicts saliency and boundary outcomes in a pure transformer architecture. Moreover, we introduced a novel token upsampling method called reverse T2T for predicting a high-resolution saliency map effortlessly within transformer-based structures. Building upon the VST model, we further propose an efficient and stronger VST version in this work, i.e. VST++. To mitigate the computational costs of the VST model, we propose a Select-Integrate Attention (SIA) module, partitioning foreground into fine-grained segments and aggregating background information into a single coarse-grained token. To incorporate 3D depth information with low cost, we design a novel depth position encoding method tailored for depth maps. Furthermore, we introduce a token-supervised prediction loss to provide straightforward guidance for the task-related tokens. We evaluate our VST++ model across various transformer-based backbones on RGB, RGB-D, and RGB-T SOD benchmark datasets. Experimental results show that our model outperforms existing methods while achieving a 25% reduction in computational costs without significant performance compromise. The demonstrated strong ability for generalization, enhanced performance, and heightened efficiency of our VST++ model highlight its potential.
WizardCoder: Empowering Code Large Language Models with Evol-Instruct
Jun 14, 2023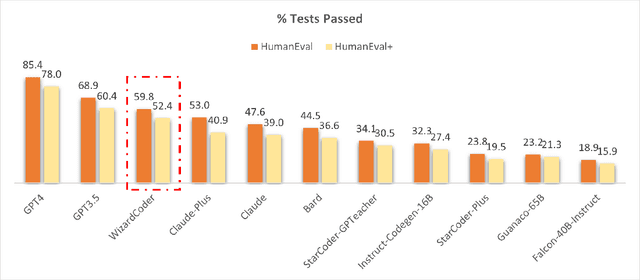
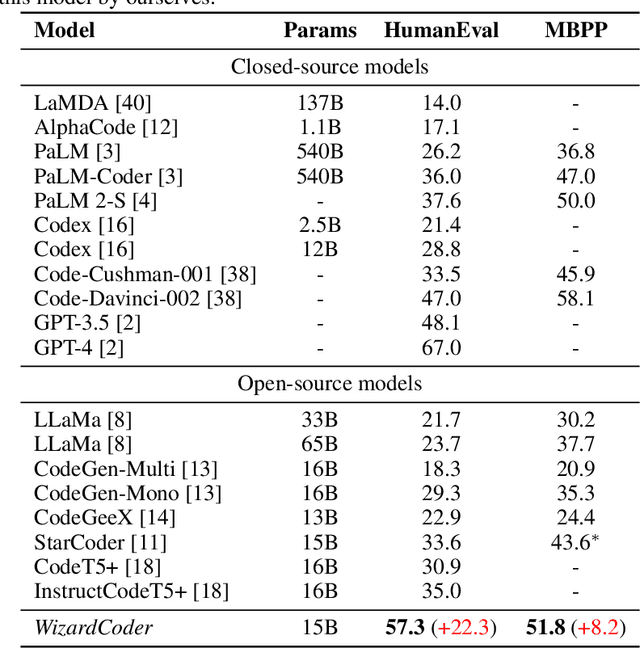
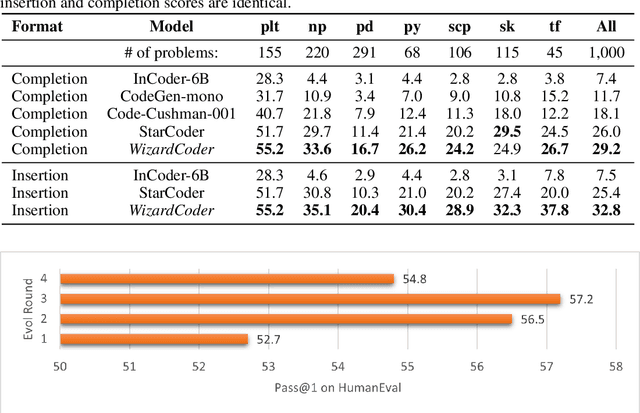

Code Large Language Models (Code LLMs), such as StarCoder, have demonstrated exceptional performance in code-related tasks. However, most existing models are solely pre-trained on extensive raw code data without instruction fine-tuning. In this paper, we introduce WizardCoder, which empowers Code LLMs with complex instruction fine-tuning, by adapting the Evol-Instruct method to the domain of code. Through comprehensive experiments on four prominent code generation benchmarks, namely HumanEval, HumanEval+, MBPP, and DS-1000, we unveil the exceptional capabilities of our model. It surpasses all other open-source Code LLMs by a substantial margin. Moreover, our model even outperforms the largest closed LLMs, Anthropic's Claude and Google's Bard, on HumanEval and HumanEval+. Our code, model weights, and data are public at https://github.com/nlpxucan/WizardLM