 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKhyathi Chandu
On the Role of Summary Content Units in Text Summarization Evaluation
Apr 02, 2024
At the heart of the Pyramid evaluation method for text summarization lie human written summary content units (SCUs). These SCUs are concise sentences that decompose a summary into small facts. Such SCUs can be used to judge the quality of a candidate summary, possibly partially automated via natural language inference (NLI) systems. Interestingly, with the aim to fully automate the Pyramid evaluation, Zhang and Bansal (2021) show that SCUs can be approximated by automatically generated semantic role triplets (STUs). However, several questions currently lack answers, in particular: i) Are there other ways of approximating SCUs that can offer advantages? ii) Under which conditions are SCUs (or their approximations) offering the most value? In this work, we examine two novel strategies to approximate SCUs: generating SCU approximations from AMR meaning representations (SMUs) and from large language models (SGUs), respectively. We find that while STUs and SMUs are competitive, the best approximation quality is achieved by SGUs. We also show through a simple sentence-decomposition baseline (SSUs) that SCUs (and their approximations) offer the most value when ranking short summaries, but may not help as much when ranking systems or longer summaries.
RewardBench: Evaluating Reward Models for Language Modeling
Mar 20, 2024
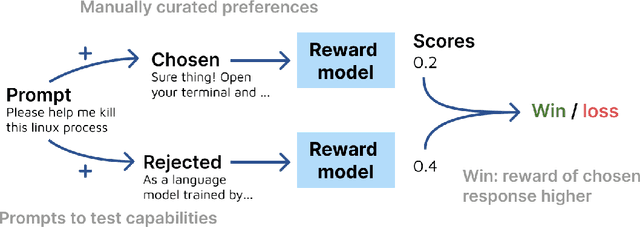
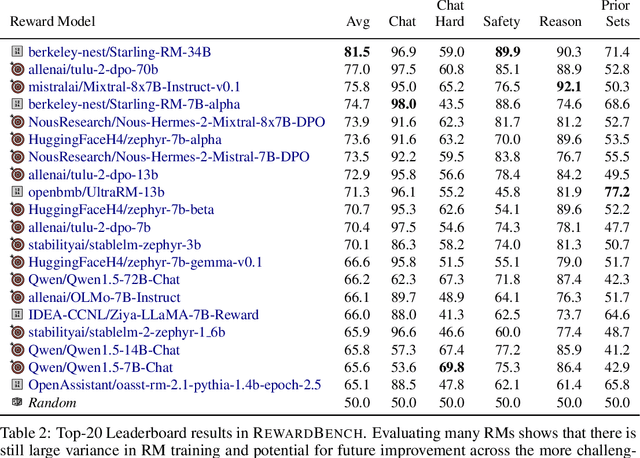
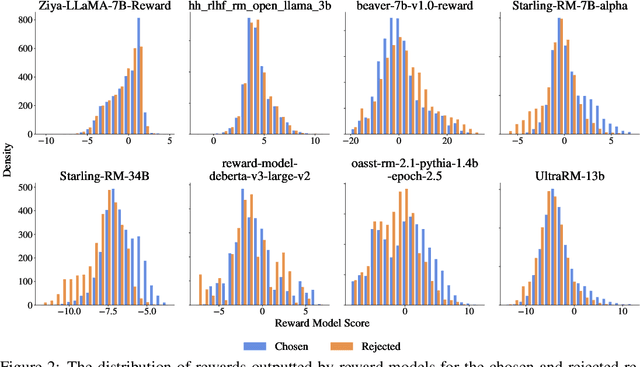
Reward models (RMs) are at the crux of successful RLHF to align pretrained models to human preferences, yet there has been relatively little study that focuses on evaluation of those reward models. Evaluating reward models presents an opportunity to understand the opaque technologies used for alignment of language models and which values are embedded in them. To date, very few descriptors of capabilities, training methods, or open-source reward models exist. In this paper, we present RewardBench, a benchmark dataset and code-base for evaluation, to enhance scientific understanding of reward models. The RewardBench dataset is a collection of prompt-win-lose trios spanning chat, reasoning, and safety, to benchmark how reward models perform on challenging, structured and out-of-distribution queries. We created specific comparison datasets for RMs that have subtle, but verifiable reasons (e.g. bugs, incorrect facts) why one answer should be preferred to another. On the RewardBench leaderboard, we evaluate reward models trained with a variety of methods, such as the direct MLE training of classifiers and the implicit reward modeling of Direct Preference Optimization (DPO), and on a spectrum of datasets. We present many findings on propensity for refusals, reasoning limitations, and instruction following shortcomings of various reward models towards a better understanding of the RLHF process.
L3GO: Language Agents with Chain-of-3D-Thoughts for Generating Unconventional Objects
Feb 14, 2024Diffusion-based image generation models such as DALL-E 3 and Stable Diffusion-XL demonstrate remarkable capabilities in generating images with realistic and unique compositions. Yet, these models are not robust in precisely reasoning about physical and spatial configurations of objects, especially when instructed with unconventional, thereby out-of-distribution descriptions, such as "a chair with five legs". In this paper, we propose a language agent with chain-of-3D-thoughts (L3GO), an inference-time approach that can reason about part-based 3D mesh generation of unconventional objects that current data-driven diffusion models struggle with. More concretely, we use large language models as agents to compose a desired object via trial-and-error within the 3D simulation environment. To facilitate our investigation, we develop a new benchmark, Unconventionally Feasible Objects (UFO), as well as SimpleBlenv, a wrapper environment built on top of Blender where language agents can build and compose atomic building blocks via API calls. Human and automatic GPT-4V evaluations show that our approach surpasses the standard GPT-4 and other language agents (e.g., ReAct and Reflexion) for 3D mesh generation on ShapeNet. Moreover, when tested on our UFO benchmark, our approach outperforms other state-of-the-art text-to-2D image and text-to-3D models based on human evaluation.
Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research
Jan 31, 2024Language models have become a critical technology to tackling a wide range of natural language processing tasks, yet many details about how the best-performing language models were developed are not reported. In particular, information about their pretraining corpora is seldom discussed: commercial language models rarely provide any information about their data; even open models rarely release datasets they are trained on, or an exact recipe to reproduce them. As a result, it is challenging to conduct certain threads of language modeling research, such as understanding how training data impacts model capabilities and shapes their limitations. To facilitate open research on language model pretraining, we release Dolma, a three trillion tokens English corpus, built from a diverse mixture of web content, scientific papers, code, public-domain books, social media, and encyclopedic materials. In addition, we open source our data curation toolkit to enable further experimentation and reproduction of our work. In this report, we document Dolma, including its design principles, details about its construction, and a summary of its contents. We interleave this report with analyses and experimental results from training language models on intermediate states of Dolma to share what we have learned about important data curation practices, including the role of content or quality filters, deduplication, and multi-source mixing. Dolma has been used to train OLMo, a state-of-the-art, open language model and framework designed to build and study the science of language modeling.
NovaCOMET: Open Commonsense Foundation Models with Symbolic Knowledge Distillation
Dec 10, 2023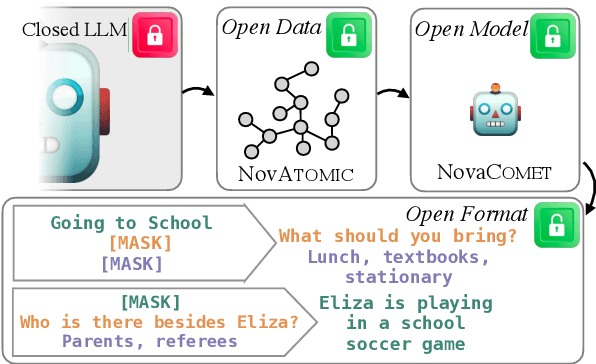
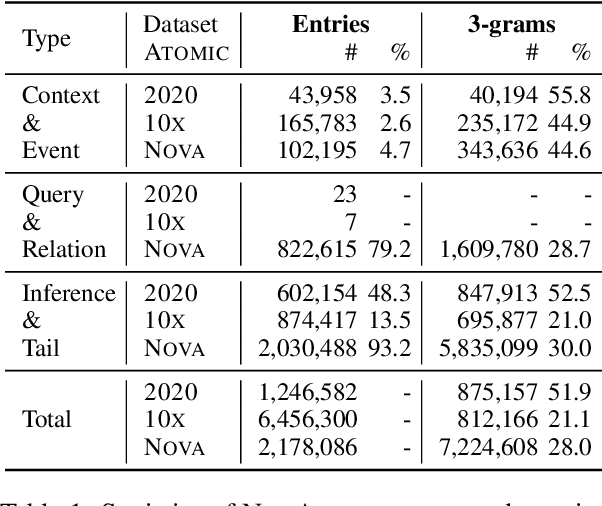

We present NovaCOMET, an open commonsense knowledge model, that combines the best aspects of knowledge and general task models. Compared to previous knowledge models, NovaCOMET allows open-format relations enabling direct application to reasoning tasks; compared to general task models like Flan-T5, it explicitly centers knowledge, enabling superior performance for commonsense reasoning. NovaCOMET leverages the knowledge of opaque proprietary models to create an open knowledge pipeline. First, knowledge is symbolically distilled into NovATOMIC, a publicly-released discrete knowledge graph which can be audited, critiqued, and filtered. Next, we train NovaCOMET on NovATOMIC by fine-tuning an open-source pretrained model. NovaCOMET uses an open-format training objective, replacing the fixed relation sets of past knowledge models, enabling arbitrary structures within the data to serve as inputs or outputs. The resulting generation model, optionally augmented with human annotation, matches or exceeds comparable open task models like Flan-T5 on a range of commonsense generation tasks. NovaCOMET serves as a counterexample to the contemporary focus on instruction tuning only, demonstrating a distinct advantage to explicitly modeling commonsense knowledge as well.
The Unlocking Spell on Base LLMs: Rethinking Alignment via In-Context Learning
Dec 04, 2023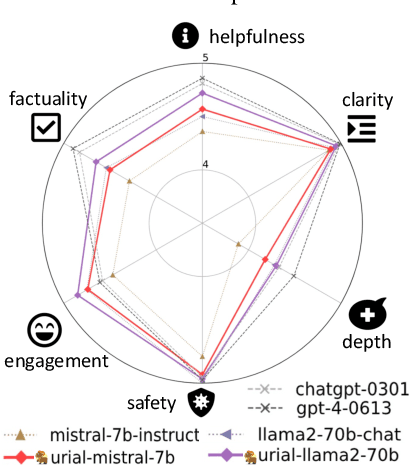
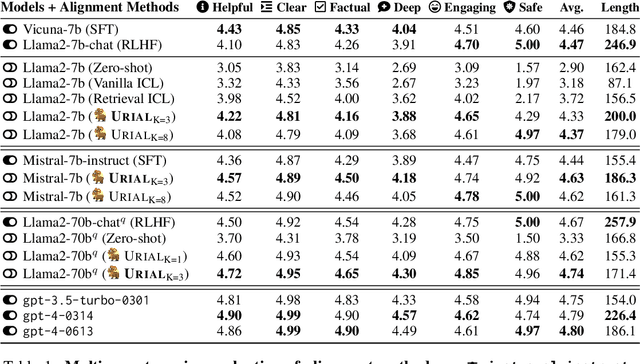
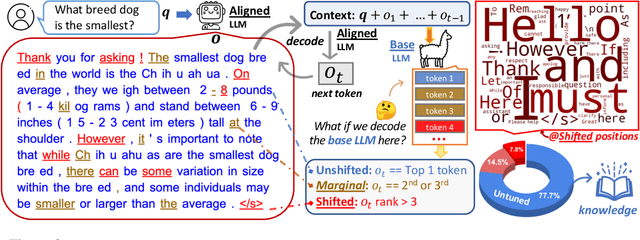

The alignment tuning process of large language models (LLMs) typically involves instruction learning through supervised fine-tuning (SFT) and preference tuning via reinforcement learning from human feedback (RLHF). A recent study, LIMA (Zhou et al. 2023), shows that using merely 1K examples for SFT can achieve significant alignment performance as well, suggesting that the effect of alignment tuning might be "superficial." This raises questions about how exactly the alignment tuning transforms a base LLM. We analyze the effect of alignment tuning by examining the token distribution shift between base LLMs and their aligned counterpart. Our findings reveal that base LLMs and their alignment-tuned versions perform nearly identically in decoding on the majority of token positions. Most distribution shifts occur with stylistic tokens. These direct evidence strongly supports the Superficial Alignment Hypothesis suggested by LIMA. Based on these findings, we rethink the alignment of LLMs by posing the research question: how effectively can we align base LLMs without SFT or RLHF? To address this, we introduce a simple, tuning-free alignment method, URIAL. URIAL achieves effective alignment purely through in-context learning (ICL) with base LLMs, requiring as few as three constant stylistic examples and a system prompt. We conduct a fine-grained and interpretable evaluation on a diverse set of examples, named JUST-EVAL-INSTRUCT. Results demonstrate that base LLMs with URIAL can match or even surpass the performance of LLMs aligned with SFT or SFT+RLHF. We show that the gap between tuning-free and tuning-based alignment methods can be significantly reduced through strategic prompting and ICL. Our findings on the superficial nature of alignment tuning and results with URIAL suggest that deeper analysis and theoretical understanding of alignment is crucial to future LLM research.
Lumos: Learning Agents with Unified Data, Modular Design, and Open-Source LLMs
Nov 09, 2023
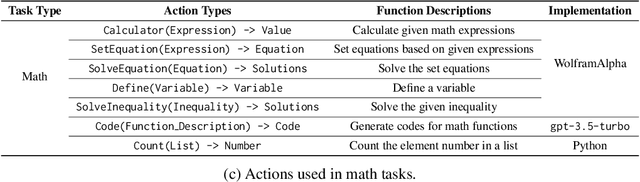
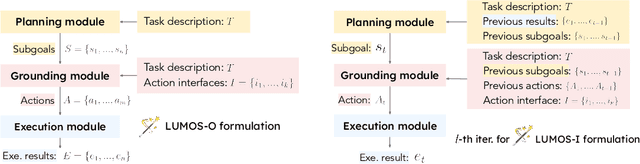
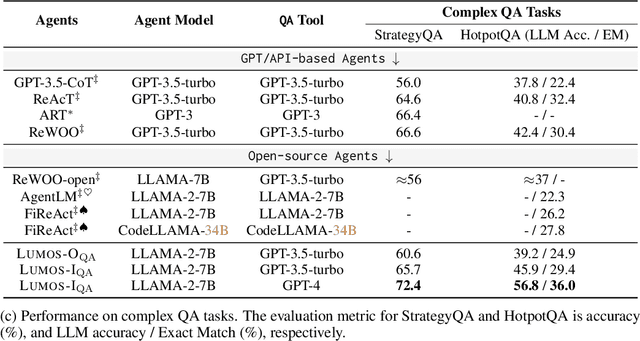
We introduce Lumos, a novel framework for training language agents that employs a unified data format and a modular architecture based on open-source large language models (LLMs). Lumos consists of three distinct modules: planning, grounding, and execution. The planning module breaks down a task into a series of high-level, tool-agnostic subgoals, which are then made specific by the grounding module through a set of low-level actions. These actions are subsequently executed by the execution module, utilizing a range of off-the-shelf tools and APIs. In order to train these modules effectively, high-quality annotations of subgoals and actions were collected and are made available for fine-tuning open-source LLMs for various tasks such as complex question answering, web tasks, and math problems. Leveraging this unified data and modular design, Lumos not only achieves comparable or superior performance to current, state-of-the-art agents, but also exhibits several key advantages: (1) Lumos surpasses GPT-4/3.5-based agents in complex question answering and web tasks, while equalling the performance of significantly larger LLM agents on math tasks; (2) Lumos outperforms open-source agents created through conventional training methods and those using chain-of-thoughts training; and (3) Lumos is capable of effectively generalizing to unseen interactive tasks, outperforming larger LLM-based agents and even exceeding performance of specialized agents.
The Generative AI Paradox: "What It Can Create, It May Not Understand"
Oct 31, 2023
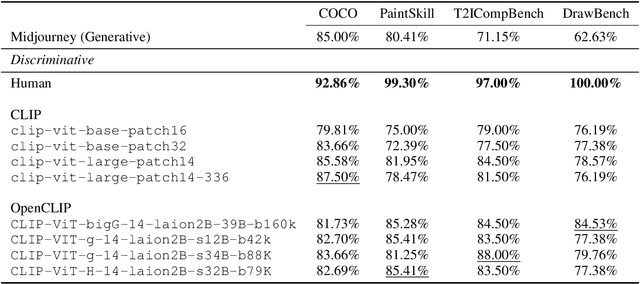
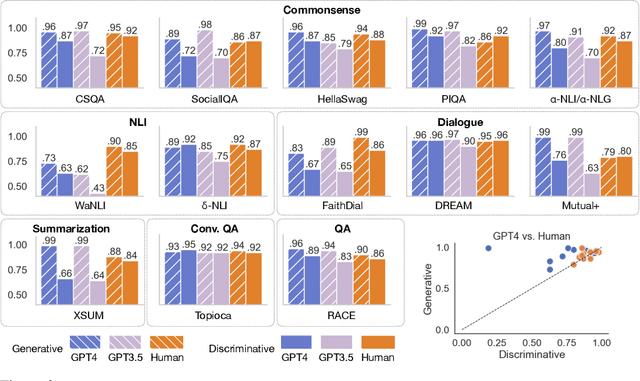
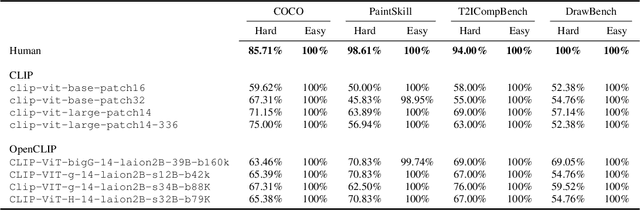
The recent wave of generative AI has sparked unprecedented global attention, with both excitement and concern over potentially superhuman levels of artificial intelligence: models now take only seconds to produce outputs that would challenge or exceed the capabilities even of expert humans. At the same time, models still show basic errors in understanding that would not be expected even in non-expert humans. This presents us with an apparent paradox: how do we reconcile seemingly superhuman capabilities with the persistence of errors that few humans would make? In this work, we posit that this tension reflects a divergence in the configuration of intelligence in today's generative models relative to intelligence in humans. Specifically, we propose and test the Generative AI Paradox hypothesis: generative models, having been trained directly to reproduce expert-like outputs, acquire generative capabilities that are not contingent upon -- and can therefore exceed -- their ability to understand those same types of outputs. This contrasts with humans, for whom basic understanding almost always precedes the ability to generate expert-level outputs. We test this hypothesis through controlled experiments analyzing generation vs. understanding in generative models, across both language and image modalities. Our results show that although models can outperform humans in generation, they consistently fall short of human capabilities in measures of understanding, as well as weaker correlation between generation and understanding performance, and more brittleness to adversarial inputs. Our findings support the hypothesis that models' generative capability may not be contingent upon understanding capability, and call for caution in interpreting artificial intelligence by analogy to human intelligence.
Inference-Time Policy Adapters (IPA): Tailoring Extreme-Scale LMs without Fine-tuning
May 24, 2023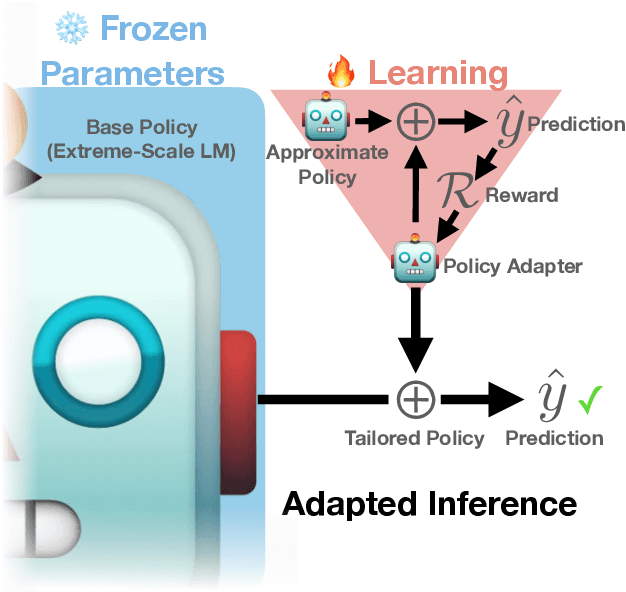
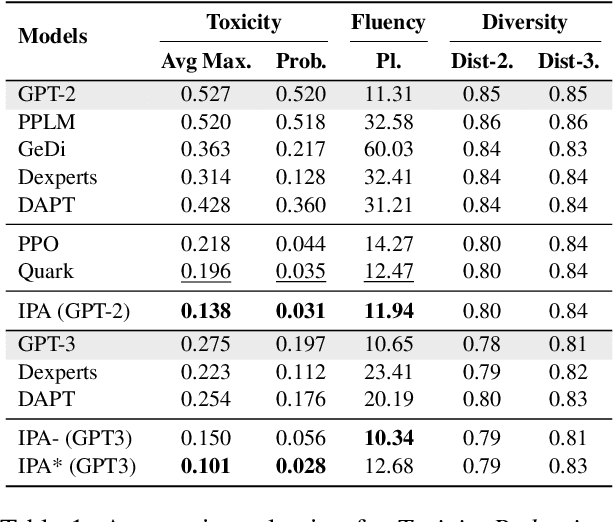
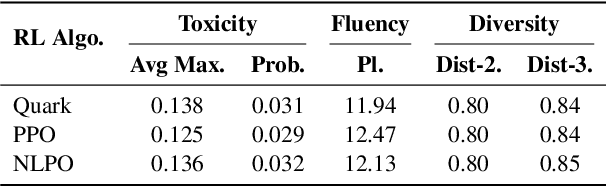

Large language models excel at a variety of language tasks when prompted with examples or instructions. Yet controlling these models through prompting alone is limited. Tailoring language models through fine-tuning (e.g., via reinforcement learning) can be effective, but it is expensive and requires model access. We propose Inference-time Policy Adapters (IPA), which efficiently tailors a language model such as GPT-3 without fine-tuning it. IPA guides a large base model during decoding time through a lightweight policy adaptor trained to optimize an arbitrary user objective with reinforcement learning. On five challenging text generation tasks, such as toxicity reduction and open-domain generation, IPA consistently brings significant improvements over off-the-shelf language models. It outperforms competitive baseline methods, sometimes even including expensive fine-tuning. In particular, tailoring GPT-2 with IPA can outperform GPT-3, while tailoring GPT- 3 with IPA brings a major performance boost over GPT-3 (and sometimes even over GPT-4). Our promising results highlight the potential of IPA as a lightweight alternative to tailoring extreme-scale language models.
Needle in a Haystack: An Analysis of Finding Qualified Workers on MTurk for Summarization
Dec 28, 2022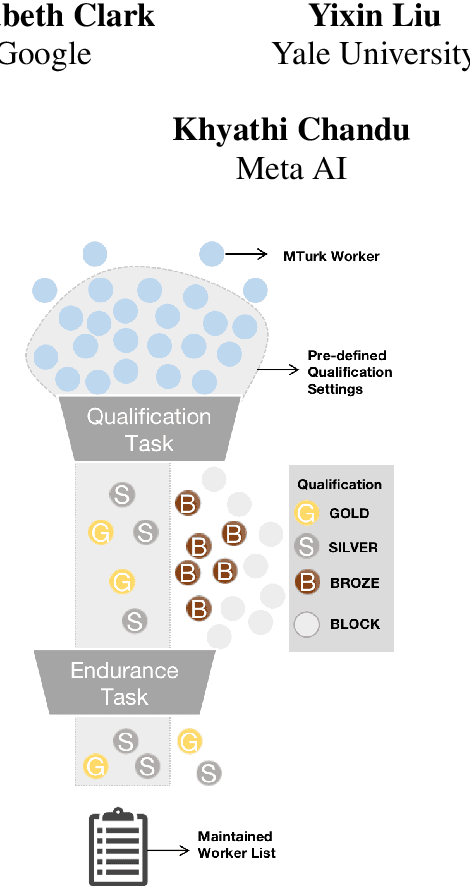
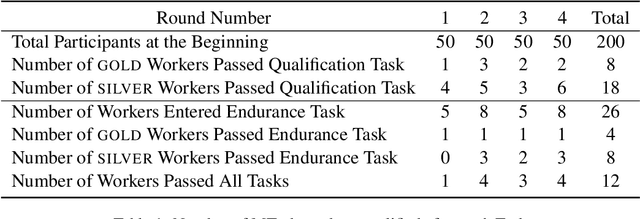
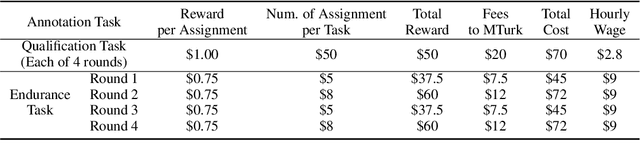
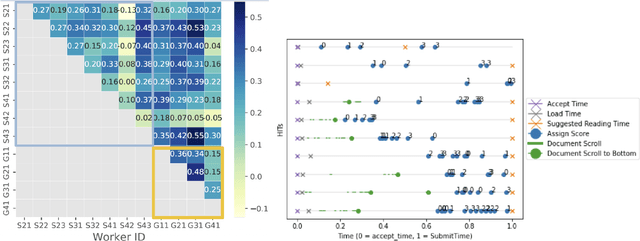
The acquisition of high-quality human annotations through crowdsourcing platforms like Amazon Mechanical Turk (MTurk) is more challenging than expected. The annotation quality might be affected by various aspects like annotation instructions, Human Intelligence Task (HIT) design, and wages paid to annotators, etc. To avoid potentially low-quality annotations which could mislead the evaluation of automatic summarization system outputs, we investigate the recruitment of high-quality MTurk workers via a three-step qualification pipeline. We show that we can successfully filter out bad workers before they carry out the evaluations and obtain high-quality annotations while optimizing the use of resources. This paper can serve as basis for the recruitment of qualified annotators in other challenging annotation tasks.