 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOyvind Tafjord
Enhancing Systematic Decompositional Natural Language Inference Using Informal Logic
Feb 27, 2024
Contemporary language models enable new opportunities for structured reasoning with text, such as the construction and evaluation of intuitive, proof-like textual entailment trees without relying on brittle formal logic. However, progress in this direction has been hampered by a long-standing lack of a clear protocol for determining what valid compositional entailment is. This absence causes noisy datasets and limited performance gains by modern neuro-symbolic engines. To address these problems, we formulate a consistent and theoretically grounded approach to annotating decompositional entailment datasets, and evaluate its impact on LLM-based textual inference. We find that our resulting dataset, RDTE (Recognizing Decompositional Textual Entailment), has a substantially higher internal consistency (+9%) than prior decompositional entailment datasets, suggesting that RDTE is a significant step forward in the long-standing problem of forming a clear protocol for discerning entailment. We also find that training an RDTE-oriented entailment classifier via knowledge distillation and employing it in a modern neuro-symbolic reasoning engine significantly improves results (both accuracy and proof quality) over other entailment classifier baselines, illustrating the practical benefit of this advance for textual inference.
OLMo: Accelerating the Science of Language Models
Feb 07, 2024Language models (LMs) have become ubiquitous in both NLP research and in commercial product offerings. As their commercial importance has surged, the most powerful models have become closed off, gated behind proprietary interfaces, with important details of their training data, architectures, and development undisclosed. Given the importance of these details in scientifically studying these models, including their biases and potential risks, we believe it is essential for the research community to have access to powerful, truly open LMs. To this end, this technical report details the first release of OLMo, a state-of-the-art, truly Open Language Model and its framework to build and study the science of language modeling. Unlike most prior efforts that have only released model weights and inference code, we release OLMo and the whole framework, including training data and training and evaluation code. We hope this release will empower and strengthen the open research community and inspire a new wave of innovation.
Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research
Jan 31, 2024Language models have become a critical technology to tackling a wide range of natural language processing tasks, yet many details about how the best-performing language models were developed are not reported. In particular, information about their pretraining corpora is seldom discussed: commercial language models rarely provide any information about their data; even open models rarely release datasets they are trained on, or an exact recipe to reproduce them. As a result, it is challenging to conduct certain threads of language modeling research, such as understanding how training data impacts model capabilities and shapes their limitations. To facilitate open research on language model pretraining, we release Dolma, a three trillion tokens English corpus, built from a diverse mixture of web content, scientific papers, code, public-domain books, social media, and encyclopedic materials. In addition, we open source our data curation toolkit to enable further experimentation and reproduction of our work. In this report, we document Dolma, including its design principles, details about its construction, and a summary of its contents. We interleave this report with analyses and experimental results from training language models on intermediate states of Dolma to share what we have learned about important data curation practices, including the role of content or quality filters, deduplication, and multi-source mixing. Dolma has been used to train OLMo, a state-of-the-art, open language model and framework designed to build and study the science of language modeling.
Paloma: A Benchmark for Evaluating Language Model Fit
Dec 16, 2023Language models (LMs) commonly report perplexity on monolithic data held out from training. Implicitly or explicitly, this data is composed of domains$\unicode{x2013}$varying distributions of language. Rather than assuming perplexity on one distribution extrapolates to others, Perplexity Analysis for Language Model Assessment (Paloma), measures LM fit to 585 text domains, ranging from nytimes.com to r/depression on Reddit. We invite submissions to our benchmark and organize results by comparability based on compliance with guidelines such as removal of benchmark contamination from pretraining. Submissions can also record parameter and training token count to make comparisons of Pareto efficiency for performance as a function of these measures of cost. We populate our benchmark with results from 6 baselines pretrained on popular corpora. In case studies, we demonstrate analyses that are possible with Paloma, such as finding that pretraining without data beyond Common Crawl leads to inconsistent fit to many domains.
Catwalk: A Unified Language Model Evaluation Framework for Many Datasets
Dec 15, 2023The success of large language models has shifted the evaluation paradigms in natural language processing (NLP). The community's interest has drifted towards comparing NLP models across many tasks, domains, and datasets, often at an extreme scale. This imposes new engineering challenges: efforts in constructing datasets and models have been fragmented, and their formats and interfaces are incompatible. As a result, it often takes extensive (re)implementation efforts to make fair and controlled comparisons at scale. Catwalk aims to address these issues. Catwalk provides a unified interface to a broad range of existing NLP datasets and models, ranging from both canonical supervised training and fine-tuning, to more modern paradigms like in-context learning. Its carefully-designed abstractions allow for easy extensions to many others. Catwalk substantially lowers the barriers to conducting controlled experiments at scale. For example, we finetuned and evaluated over 64 models on over 86 datasets with a single command, without writing any code. Maintained by the AllenNLP team at the Allen Institute for Artificial Intelligence (AI2), Catwalk is an ongoing open-source effort: https://github.com/allenai/catwalk.
BaRDa: A Belief and Reasoning Dataset that Separates Factual Accuracy and Reasoning Ability
Dec 12, 2023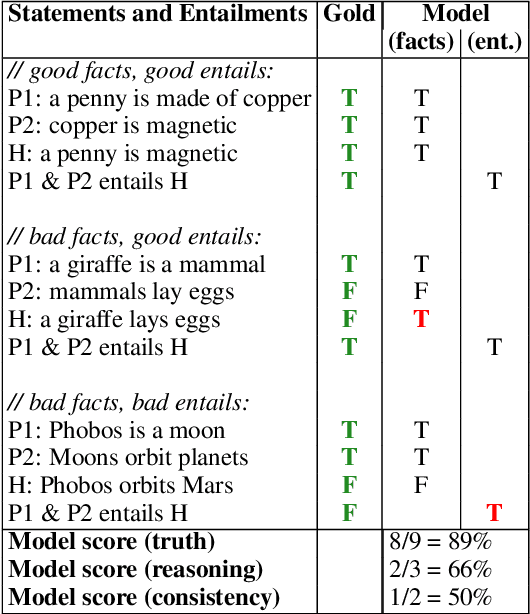
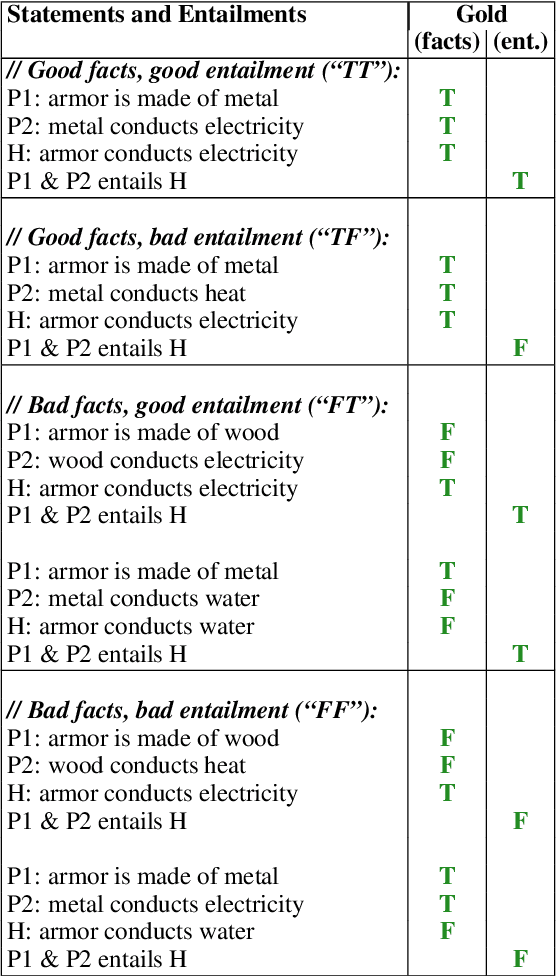
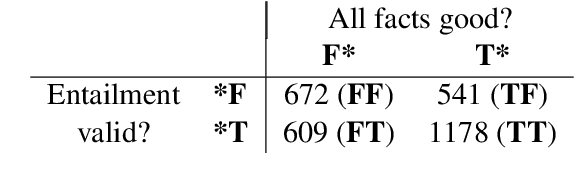
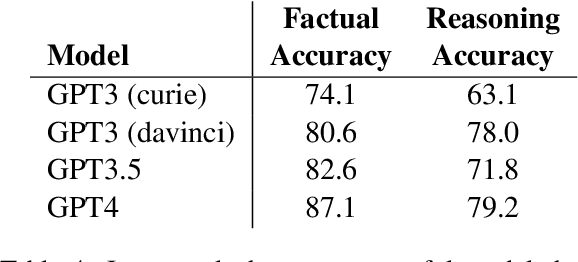
While there are numerous benchmarks comparing the performance of modern language models (LMs), end-task evaluations often conflate notions of *factual accuracy* ("truth") and *reasoning ability* ("rationality", or "honesty" in the sense of correctly reporting implications of beliefs). Our goal is a dataset that clearly distinguishes these two notions. Our approach is to leverage and extend a collection of human-annotated *entailment trees*, engineered to express both good and bad chains of reasoning, and using a mixture of true and false facts, in particular including counterfactual examples, to avoid belief bias (also known as the "content effect"). The resulting dataset, called BaRDa, contains 3000 entailments (1787 valid, 1213 invalid), using 6681 true and 2319 false statements. Testing on four GPT-series models, GPT3(curie)/GPT3(davinici)/3.5/4, we find factual accuracy (truth) scores of 74.1/80.6/82.6/87.1 and reasoning accuracy scores of 63.1/78.0/71.8/79.2. This shows the clear progression of models towards improved factual accuracy and entailment reasoning, and the dataset provides a new benchmark that more cleanly separates and quantifies these two notions.
Digital Socrates: Evaluating LLMs through explanation critiques
Nov 16, 2023While LLMs can provide reasoned explanations along with their answers, the nature and quality of those explanations are still poorly understood. In response, our goal is to define a detailed way of characterizing the explanation capabilities of modern models and to create a nuanced, interpretable explanation evaluation tool that can generate such characterizations automatically, without relying on expensive API calls or human annotations. Our approach is to (a) define the new task of explanation critiquing - identifying and categorizing any main flaw in an explanation and providing suggestions to address the flaw, (b) create a sizeable, human-verified dataset for this task, and (c) train an open-source, automatic critiquing model (called Digital Socrates) using this data. Through quantitative and qualitative analysis, we demonstrate how Digital Socrates is useful for revealing insights about student models by examining their reasoning chains, and how it can provide high-quality, nuanced, automatic evaluation of those model explanations for the first time. Digital Socrates thus fills an important gap in evaluation tools for understanding and improving the explanation behavior of models.
CLIN: A Continually Learning Language Agent for Rapid Task Adaptation and Generalization
Oct 16, 2023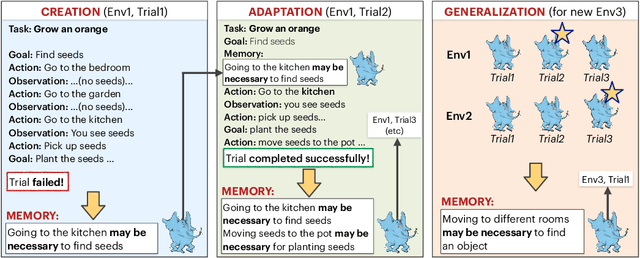
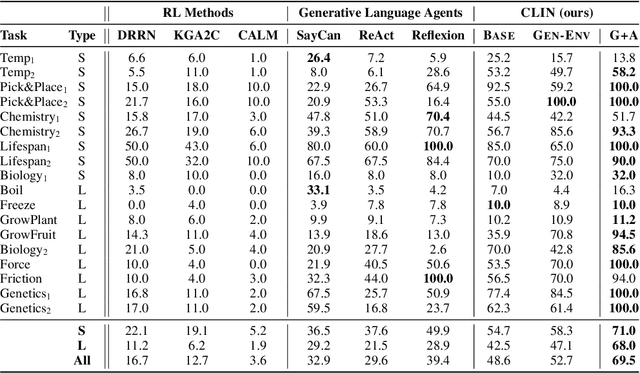

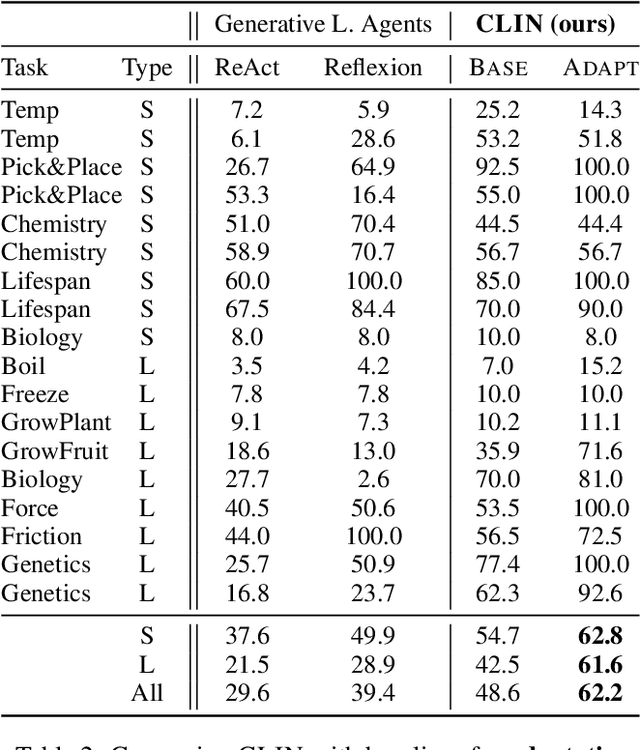
Language agents have shown some ability to interact with an external environment, e.g., a virtual world such as ScienceWorld, to perform complex tasks, e.g., growing a plant, without the startup costs of reinforcement learning. However, despite their zero-shot capabilities, these agents to date do not continually improve over time beyond performance refinement on a specific task. Here we present CLIN, the first language-based agent to achieve this, so that it continually improves over multiple trials, including when both the environment and task are varied, and without requiring parameter updates. Our approach is to use a persistent, dynamic, textual memory centered on causal abstractions (rather than general "helpful hints") that is regularly updated after each trial so that the agent gradually learns useful knowledge for new trials. In the ScienceWorld benchmark, CLIN is able to continually improve on repeated trials on the same task and environment, outperforming state-of-the-art reflective language agents like Reflexion by 23 absolute points. CLIN can also transfer its learning to new environments (or new tasks), improving its zero-shot performance by 4 points (13 for new tasks) and can further improve performance there through continual memory updates, enhancing performance by an additional 17 points (7 for new tasks). This suggests a new architecture for agents built on frozen models that can still continually and rapidly improve over time.
Attentiveness to Answer Choices Doesn't Always Entail High QA Accuracy
May 24, 2023



When large language models (LMs) are applied in zero- or few-shot settings to discriminative tasks such as multiple-choice questions, their attentiveness (i.e., probability mass) is spread across many vocabulary tokens that are not valid choices. Such a spread across multiple surface forms with identical meaning is thought to cause an underestimation of a model's true performance, referred to as the "surface form competition" (SFC) hypothesis. This has motivated the introduction of various probability normalization methods. However, many core questions remain unanswered. How do we measure SFC or attentiveness? Are there direct ways of increasing attentiveness on valid choices? Does increasing attentiveness always improve task accuracy? We propose a mathematical formalism for studying this phenomenon, provide a metric for quantifying attentiveness, and identify a simple method for increasing it -- namely, in-context learning with even just one example containing answer choices. The formalism allows us to quantify SFC and bound its impact. Our experiments on three diverse datasets and six LMs reveal several surprising findings. For example, encouraging models to generate a valid answer choice can, in fact, be detrimental to task performance for some LMs, and prior probability normalization methods are less effective (sometimes even detrimental) to instruction-tuned LMs. We conclude with practical insights for effectively using prompted LMs for multiple-choice tasks.
Language Models with Rationality
May 23, 2023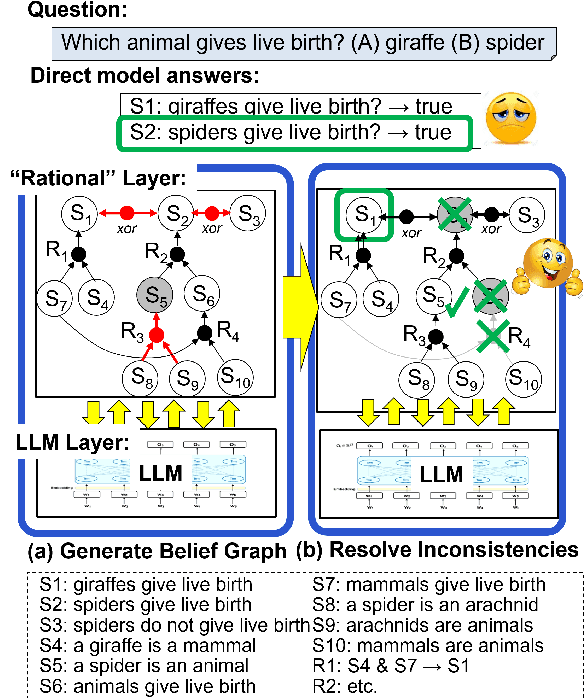

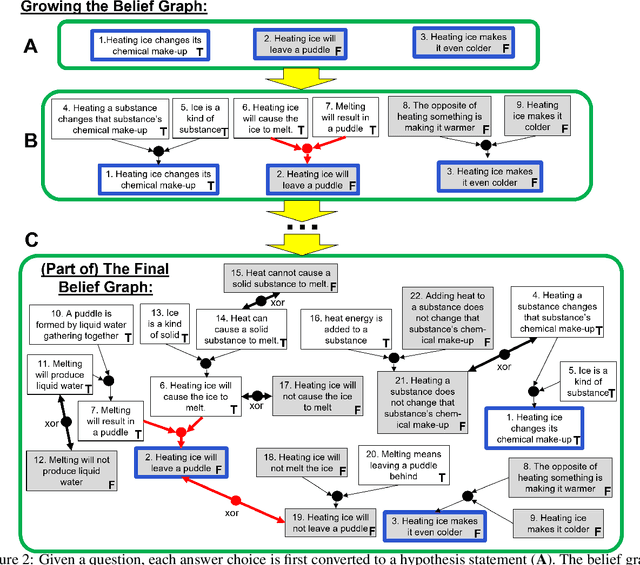
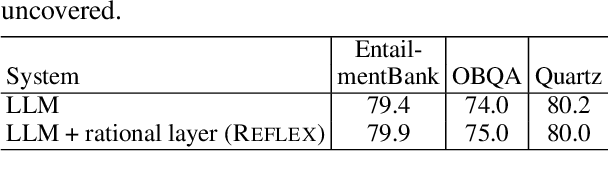
While large language models (LLMs) are proficient at question-answering (QA), the dependencies between their answers and other "beliefs" they may have about the world are typically unstated, and may even be in conflict. Our goal is to uncover such dependencies and reduce inconsistencies among them, so that answers are supported by faithful, system-believed chains of reasoning drawn from a consistent network of beliefs. Our approach, which we call REFLEX, is to add a "rational", self-reflecting layer on top of the LLM. First, given a question, we construct a belief graph using a backward-chaining process to materialize relevant model "beliefs" (including beliefs about answer candidates) and the inferential relationships between them. Second, we identify and minimize contradictions in that graph using a formal constraint reasoner. We find that REFLEX significantly improves consistency (by 8%-11% absolute) without harming overall answer accuracy, resulting in answers supported by faithful chains of reasoning drawn from a more consistent belief system. This suggests a new style of system architecture, in which an LLM extended with a rational layer of self-reflection can repair latent inconsistencies within the LLM alone.