 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuling Gu
WorldValuesBench: A Large-Scale Benchmark Dataset for Multi-Cultural Value Awareness of Language Models
Apr 25, 2024
The awareness of multi-cultural human values is critical to the ability of language models (LMs) to generate safe and personalized responses. However, this awareness of LMs has been insufficiently studied, since the computer science community lacks access to the large-scale real-world data about multi-cultural values. In this paper, we present WorldValuesBench, a globally diverse, large-scale benchmark dataset for the multi-cultural value prediction task, which requires a model to generate a rating response to a value question based on demographic contexts. Our dataset is derived from an influential social science project, World Values Survey (WVS), that has collected answers to hundreds of value questions (e.g., social, economic, ethical) from 94,728 participants worldwide. We have constructed more than 20 million examples of the type "(demographic attributes, value question) $\rightarrow$ answer" from the WVS responses. We perform a case study using our dataset and show that the task is challenging for strong open and closed-source models. On merely $11.1\%$, $25.0\%$, $72.2\%$, and $75.0\%$ of the questions, Alpaca-7B, Vicuna-7B-v1.5, Mixtral-8x7B-Instruct-v0.1, and GPT-3.5 Turbo can respectively achieve $<0.2$ Wasserstein 1-distance from the human normalized answer distributions. WorldValuesBench opens up new research avenues in studying limitations and opportunities in multi-cultural value awareness of LMs.
PROC2PDDL: Open-Domain Planning Representations from Texts
Feb 29, 2024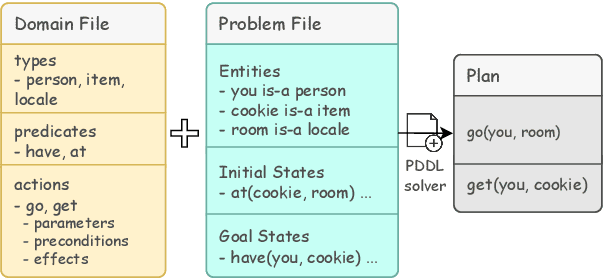
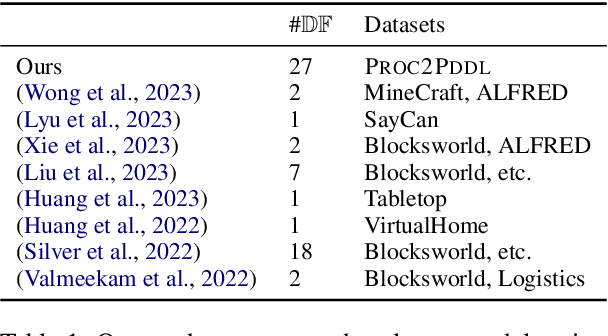
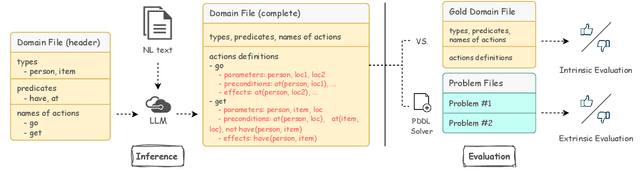
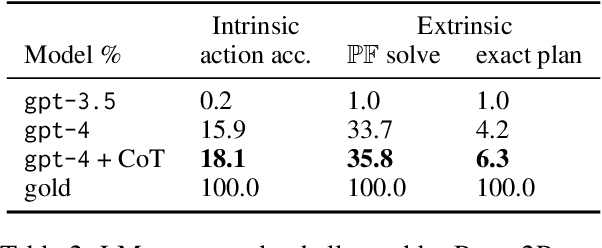
Planning in a text-based environment continues to be a major challenge for AI systems. Recent approaches have used language models to predict a planning domain definition (e.g., PDDL) but have only been evaluated in closed-domain simulated environments. To address this, we present Proc2PDDL , the first dataset containing open-domain procedural texts paired with expert-annotated PDDL representations. Using this dataset, we evaluate state-of-the-art models on defining the preconditions and effects of actions. We show that Proc2PDDL is highly challenging, with GPT-3.5's success rate close to 0% and GPT-4's around 35%. Our analysis shows both syntactic and semantic errors, indicating LMs' deficiency in both generating domain-specific prgorams and reasoning about events. We hope this analysis and dataset helps future progress towards integrating the best of LMs and formal planning.
OLMo: Accelerating the Science of Language Models
Feb 07, 2024Language models (LMs) have become ubiquitous in both NLP research and in commercial product offerings. As their commercial importance has surged, the most powerful models have become closed off, gated behind proprietary interfaces, with important details of their training data, architectures, and development undisclosed. Given the importance of these details in scientifically studying these models, including their biases and potential risks, we believe it is essential for the research community to have access to powerful, truly open LMs. To this end, this technical report details the first release of OLMo, a state-of-the-art, truly Open Language Model and its framework to build and study the science of language modeling. Unlike most prior efforts that have only released model weights and inference code, we release OLMo and the whole framework, including training data and training and evaluation code. We hope this release will empower and strengthen the open research community and inspire a new wave of innovation.
Digital Socrates: Evaluating LLMs through explanation critiques
Nov 16, 2023While LLMs can provide reasoned explanations along with their answers, the nature and quality of those explanations are still poorly understood. In response, our goal is to define a detailed way of characterizing the explanation capabilities of modern models and to create a nuanced, interpretable explanation evaluation tool that can generate such characterizations automatically, without relying on expensive API calls or human annotations. Our approach is to (a) define the new task of explanation critiquing - identifying and categorizing any main flaw in an explanation and providing suggestions to address the flaw, (b) create a sizeable, human-verified dataset for this task, and (c) train an open-source, automatic critiquing model (called Digital Socrates) using this data. Through quantitative and qualitative analysis, we demonstrate how Digital Socrates is useful for revealing insights about student models by examining their reasoning chains, and how it can provide high-quality, nuanced, automatic evaluation of those model explanations for the first time. Digital Socrates thus fills an important gap in evaluation tools for understanding and improving the explanation behavior of models.
What Makes it Ok to Set a Fire? Iterative Self-distillation of Contexts and Rationales for Disambiguating Defeasible Social and Moral Situations
Nov 01, 2023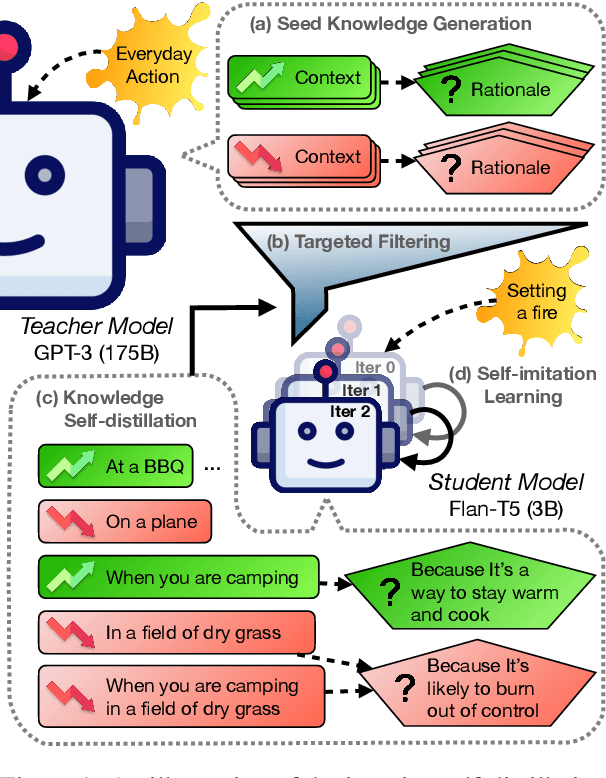
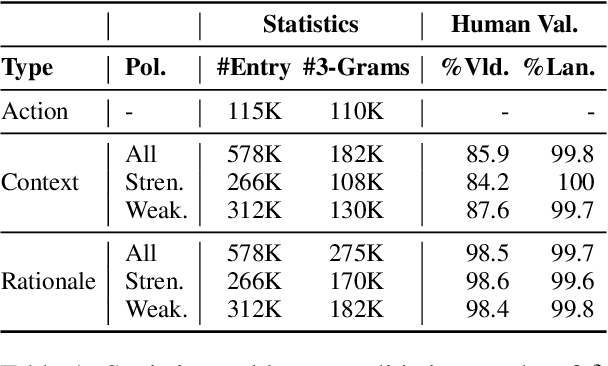

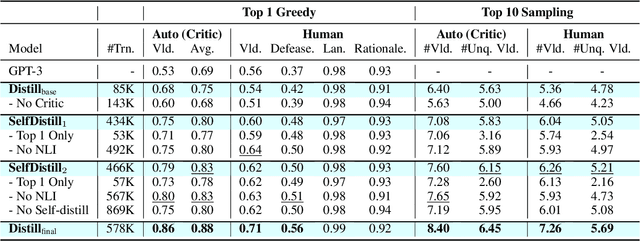
Moral or ethical judgments rely heavily on the specific contexts in which they occur. Understanding varying shades of defeasible contextualizations (i.e., additional information that strengthens or attenuates the moral acceptability of an action) is critical to accurately represent the subtlety and intricacy of grounded human moral judgment in real-life scenarios. We introduce defeasible moral reasoning: a task to provide grounded contexts that make an action more or less morally acceptable, along with commonsense rationales that justify the reasoning. To elicit high-quality task data, we take an iterative self-distillation approach that starts from a small amount of unstructured seed knowledge from GPT-3 and then alternates between (1) self-distillation from student models; (2) targeted filtering with a critic model trained by human judgment (to boost validity) and NLI (to boost diversity); (3) self-imitation learning (to amplify the desired data quality). This process yields a student model that produces defeasible contexts with improved validity, diversity, and defeasibility. From this model we distill a high-quality dataset, \delta-Rules-of-Thumb, of 1.2M entries of contextualizations and rationales for 115K defeasible moral actions rated highly by human annotators 85.9% to 99.8% of the time. Using \delta-RoT we obtain a final student model that wins over all intermediate student models by a notable margin.
Do language models have coherent mental models of everyday things?
Dec 20, 2022
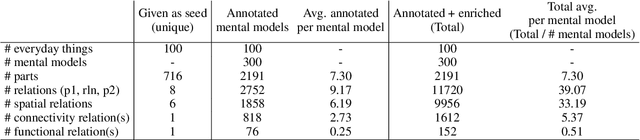


When people think of everyday things like an "egg," they typically have a mental image associated with it. This commonsense knowledge helps us understand how these everyday things work and how to interact with them. For example, when someone tries to make a fried egg, they know that it has a shell and that it can be cracked open to reveal the egg white and yolk inside. However, if a system does not have a coherent picture of such everyday things, thinking that the egg yolk surrounds the shell, then it might have to resort to ridiculous approaches such as trying to scrape the egg yolk off the shell into the pan. Do language models have a coherent picture of such everyday things? To investigate this, we propose a benchmark dataset consisting of 100 everyday things, their parts, and the relationships between these parts. We observe that state-of-the-art pre-trained language models (LMs) like GPT-3 and Macaw have fragments of knowledge about these entities, but they fail to produce consistent parts mental models. We propose a simple extension to these LMs where we apply a constraint satisfaction layer on top of raw predictions from LMs to produce more consistent and accurate parts mental models of everyday things.
Measure More, Question More: Experimental Studies on Transformer-based Language Models and Complement Coercion
Dec 20, 2022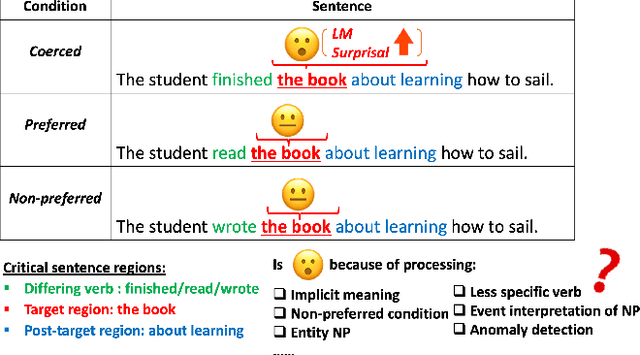


Transformer-based language models have shown strong performance on an array of natural language understanding tasks. However, the question of how these models react to implicit meaning has been largely unexplored. We investigate this using the complement coercion phenomenon, which involves sentences like "The student finished the book about sailing" where the action "reading" is implicit. We compare LMs' surprisal estimates at various critical sentence regions in sentences with and without implicit meaning. Effects associated with recovering implicit meaning were found at a critical region other than where sentences minimally differ. We then use follow-up experiments to factor out potential confounds, revealing different perspectives that offer a richer and more accurate picture.
One Venue, Two Conferences: The Separation of Chinese and American Citation Networks
Nov 17, 2022
At NeurIPS, American and Chinese institutions cite papers from each other's regions substantially less than they cite endogamously. We build a citation graph to quantify this divide, compare it to European connectivity, and discuss the causes and consequences of the separation.
Just-DREAM-about-it: Figurative Language Understanding with DREAM-FLUTE
Oct 28, 2022



Figurative language (e.g., "he flew like the wind") is challenging to understand, as it is hard to tell what implicit information is being conveyed from the surface form alone. We hypothesize that to perform this task well, the reader needs to mentally elaborate the scene being described to identify a sensible meaning of the language. We present DREAM-FLUTE, a figurative language understanding system that does this, first forming a "mental model" of situations described in a premise and hypothesis before making an entailment/contradiction decision and generating an explanation. DREAM-FLUTE uses an existing scene elaboration model, DREAM, for constructing its "mental model." In the FigLang2022 Shared Task evaluation, DREAM-FLUTE achieved (joint) first place (Acc@60=63.3%), and can perform even better with ensemble techniques, demonstrating the effectiveness of this approach. More generally, this work suggests that adding a reflective component to pretrained language models can improve their performance beyond standard fine-tuning (3.3% improvement in Acc@60).
Large-Scale Acoustic Characterization of Singaporean Children's English Pronunciation
Feb 18, 2022
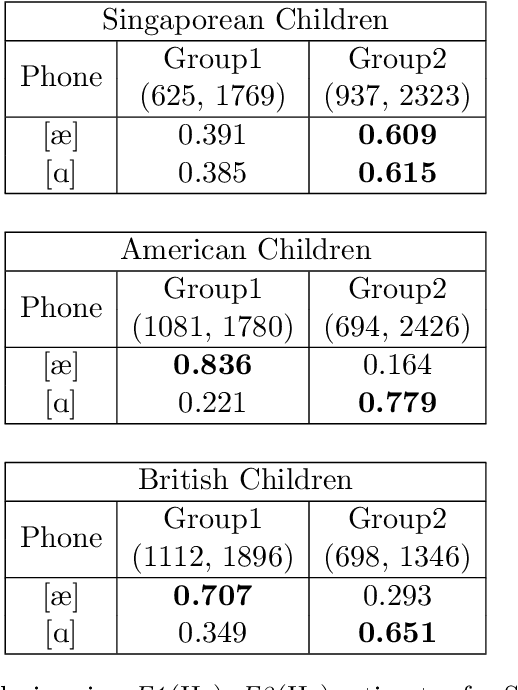
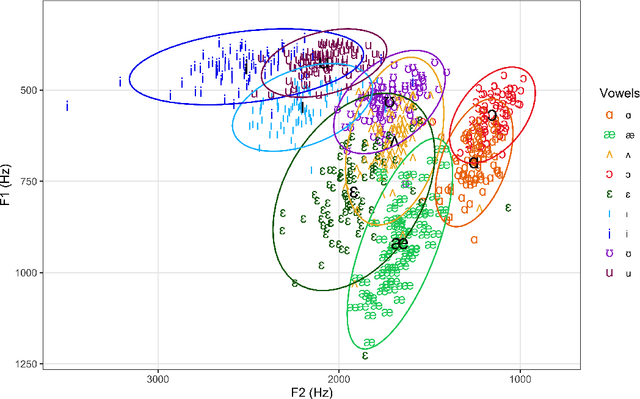

In this work, we investigate pronunciation differences in English spoken by Singaporean children in relation to their American and British counterparts by conducting Kmeans clustering and Archetypal analysis on selected vowel pairs and approximants. Given that Singapore adopts British English as the institutional standard due to historical reasons, one might expect Singaporean children to follow British pronunciation patterns. Indeed, Singaporean and British children are more similar in their production of syllable-final /r/ -- they do not lower their third formant nearly as much as American children do, suggesting a lack of rhoticity. Interestingly, Singaporean children also present similar patterns to American children when it comes to their fronting of vowels as demonstrated across various vowels including TRAP-BATH split vowels. Singaporean children's English also demonstrated characteristics that do not resemble any of the other two populations. We observe that Singaporean children's vowel height characteristics are distinct from both that of American and British children. In tense and lax vowel pairs, we also consistently observe that the distinction is less conspicuous for Singaporean children compared to the other speaker groups. Further, while American and British children demonstrate lowering of F1 and F2 formants in transitions into syllable-final /l/s, a wide gap between F2 and F3 formants, and small difference between F1 and F2 formants, all of these are not exhibited in Singaporean children's pronunciation. These findings point towards potential sociolinguistic implications of how Singapore English might be evolving to embody more than British pronunciation characteristics. Furthermore, these findings also suggest that Singapore English could be have been influenced by languages beyond American and British English, potentially due to Singapore's multilingual environment.