 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKate Sanders
On the Evaluation of Machine-Generated Reports
May 02, 2024
Large Language Models (LLMs) have enabled new ways to satisfy information needs. Although great strides have been made in applying them to settings like document ranking and short-form text generation, they still struggle to compose complete, accurate, and verifiable long-form reports. Reports with these qualities are necessary to satisfy the complex, nuanced, or multi-faceted information needs of users. In this perspective paper, we draw together opinions from industry and academia, and from a variety of related research areas, to present our vision for automatic report generation, and -- critically -- a flexible framework by which such reports can be evaluated. In contrast with other summarization tasks, automatic report generation starts with a detailed description of an information need, stating the necessary background, requirements, and scope of the report. Further, the generated reports should be complete, accurate, and verifiable. These qualities, which are desirable -- if not required -- in many analytic report-writing settings, require rethinking how to build and evaluate systems that exhibit these qualities. To foster new efforts in building these systems, we present an evaluation framework that draws on ideas found in various evaluations. To test completeness and accuracy, the framework uses nuggets of information, expressed as questions and answers, that need to be part of any high-quality generated report. Additionally, evaluation of citations that map claims made in the report to their source documents ensures verifiability.
Tur[k]ingBench: A Challenge Benchmark for Web Agents
Mar 21, 2024![Figure 1 for Tur[k]ingBench: A Challenge Benchmark for Web Agents](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2F341da3f8af6edd31edd8f5a3d9452957aeaaa744%2F2-Figure1-1.png&w=640&q=75)
![Figure 2 for Tur[k]ingBench: A Challenge Benchmark for Web Agents](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2F341da3f8af6edd31edd8f5a3d9452957aeaaa744%2F3-Table1-1.png&w=640&q=75)
![Figure 3 for Tur[k]ingBench: A Challenge Benchmark for Web Agents](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2F341da3f8af6edd31edd8f5a3d9452957aeaaa744%2F5-Figure2-1.png&w=640&q=75)
![Figure 4 for Tur[k]ingBench: A Challenge Benchmark for Web Agents](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2F341da3f8af6edd31edd8f5a3d9452957aeaaa744%2F5-Figure3-1.png&w=640&q=75)
Recent chatbots have demonstrated impressive ability to understand and communicate in raw-text form. However, there is more to the world than raw text. For example, humans spend long hours of their time on web pages, where text is intertwined with other modalities and tasks are accomplished in the form of various complex interactions. Can state-of-the-art multi-modal models generalize to such complex domains? To address this question, we introduce TurkingBench, a benchmark of tasks formulated as web pages containing textual instructions with multi-modal context. Unlike existing work which employs artificially synthesized web pages, here we use natural HTML pages that were originally designed for crowdsourcing workers for various annotation purposes. The HTML instructions of each task are also instantiated with various values (obtained from the crowdsourcing tasks) to form new instances of the task. This benchmark contains 32.2K instances distributed across 158 tasks. Additionally, to facilitate the evaluation on TurkingBench, we develop an evaluation framework that connects the responses of chatbots to modifications on web pages (modifying a text box, checking a radio, etc.). We evaluate the performance of state-of-the-art models, including language-only, vision-only, and layout-only models, and their combinations, on this benchmark. Our findings reveal that these models perform significantly better than random chance, yet considerable room exists for improvement. We hope this benchmark will help facilitate the evaluation and development of web-based agents.
TV-TREES: Multimodal Entailment Trees for Neuro-Symbolic Video Reasoning
Mar 11, 2024It is challenging to perform question-answering over complex, multimodal content such as television clips. This is in part because current video-language models rely on single-modality reasoning, have lowered performance on long inputs, and lack interpetability. We propose TV-TREES, the first multimodal entailment tree generator. TV-TREES serves as an approach to video understanding that promotes interpretable joint-modality reasoning by producing trees of entailment relationships between simple premises directly entailed by the videos and higher-level conclusions. We then introduce the task of multimodal entailment tree generation to evaluate the reasoning quality of such methods. Our method's experimental results on the challenging TVQA dataset demonstrate intepretable, state-of-the-art zero-shot performance on full video clips, illustrating a best-of-both-worlds contrast to black-box methods.
Enhancing Systematic Decompositional Natural Language Inference Using Informal Logic
Feb 27, 2024Contemporary language models enable new opportunities for structured reasoning with text, such as the construction and evaluation of intuitive, proof-like textual entailment trees without relying on brittle formal logic. However, progress in this direction has been hampered by a long-standing lack of a clear protocol for determining what valid compositional entailment is. This absence causes noisy datasets and limited performance gains by modern neuro-symbolic engines. To address these problems, we formulate a consistent and theoretically grounded approach to annotating decompositional entailment datasets, and evaluate its impact on LLM-based textual inference. We find that our resulting dataset, RDTE (Recognizing Decompositional Textual Entailment), has a substantially higher internal consistency (+9%) than prior decompositional entailment datasets, suggesting that RDTE is a significant step forward in the long-standing problem of forming a clear protocol for discerning entailment. We also find that training an RDTE-oriented entailment classifier via knowledge distillation and employing it in a modern neuro-symbolic reasoning engine significantly improves results (both accuracy and proof quality) over other entailment classifier baselines, illustrating the practical benefit of this advance for textual inference.
MultiVENT: Multilingual Videos of Events with Aligned Natural Text
Jul 06, 2023



Everyday news coverage has shifted from traditional broadcasts towards a wide range of presentation formats such as first-hand, unedited video footage. Datasets that reflect the diverse array of multimodal, multilingual news sources available online could be used to teach models to benefit from this shift, but existing news video datasets focus on traditional news broadcasts produced for English-speaking audiences. We address this limitation by constructing MultiVENT, a dataset of multilingual, event-centric videos grounded in text documents across five target languages. MultiVENT includes both news broadcast videos and non-professional event footage, which we use to analyze the state of online news videos and how they can be leveraged to build robust, factually accurate models. Finally, we provide a model for complex, multilingual video retrieval to serve as a baseline for information retrieval using MultiVENT.
Ambiguous Images With Human Judgments for Robust Visual Event Classification
Oct 06, 2022



Contemporary vision benchmarks predominantly consider tasks on which humans can achieve near-perfect performance. However, humans are frequently presented with visual data that they cannot classify with 100% certainty, and models trained on standard vision benchmarks achieve low performance when evaluated on this data. To address this issue, we introduce a procedure for creating datasets of ambiguous images and use it to produce SQUID-E ("Squidy"), a collection of noisy images extracted from videos. All images are annotated with ground truth values and a test set is annotated with human uncertainty judgments. We use this dataset to characterize human uncertainty in vision tasks and evaluate existing visual event classification models. Experimental results suggest that existing vision models are not sufficiently equipped to provide meaningful outputs for ambiguous images and that datasets of this nature can be used to assess and improve such models through model training and direct evaluation of model calibration. These findings motivate large-scale ambiguous dataset creation and further research focusing on noisy visual data.
A Multi-Chamber Smart Suction Cup for Adaptive Gripping and Haptic Exploration
May 05, 2021



We present a novel robot end-effector for gripping and haptic exploration. Tactile sensing through suction flow monitoring is applied to a new suction cup design that contains multiple chambers for air flow. Each chamber connects with its own remote pressure transducer, which enables both absolute and differential pressure measures between chambers. By changing the overall vacuum applied to this smart suction cup, it can perform different functions such as gentle haptic exploration (low pressure) and monitoring breaks in the seal during strong astrictive gripping (high pressure). Haptic exploration of surfaces through sliding and palpation can guide the selection of suction grasp locations and help to identify the local surface geometry. During suction gripping, this design localizes breaks in the suction seal between four quadrants with up to 97% accuracy and detects breaks in the suction seal early enough to avoid total grasp failure.
Mechanical Search on Shelves using Lateral Access X-RAY
Nov 23, 2020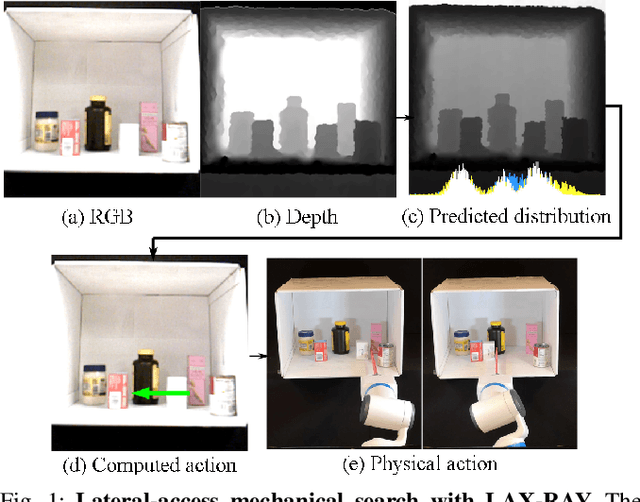



Efficiently finding an occluded object with lateral access arises in many contexts such as warehouses, retail, healthcare, shipping, and homes. We introduce LAX-RAY (Lateral Access maXimal Reduction of occupancY support Area), a system to automate the mechanical search for occluded objects on shelves. For such lateral access environments, LAX-RAY couples a perception pipeline predicting a target object occupancy support distribution with a mechanical search policy that sequentially selects occluding objects to push to the side to reveal the target as efficiently as possible. Within the context of extruded polygonal objects and a stationary target with a known aspect ratio, we explore three lateral access search policies: Distribution Area Reduction (DAR), Distribution Entropy Reduction (DER), and Distribution Entropy Reduction over Multiple Time Steps (DER-MT) utilizing the support distribution and prior information. We evaluate these policies using the First-Order Shelf Simulator (FOSS) in which we simulate 800 random shelf environments of varying difficulty, and in a physical shelf environment with a Fetch robot and an embedded PrimeSense RGBD Camera. Average simulation results of 87.3% success rate demonstrate better performance of DER-MT with 2 prediction steps. When deployed on the robot, results show a success rate of at least 80% for all policies, suggesting that LAX-RAY can efficiently reveal the target object in reality. Both results show significantly better performance of the three proposed policies compared to a baseline policy with uniform probability distribution assumption in non-trivial cases, showing the importance of distribution prediction. Code, videos, and supplementary material can be found at https://sites.google.com/berkeley.edu/lax-ray.
Non-Markov Policies to Reduce Sequential Failures in Robot Bin Picking
Jul 20, 2020



A new generation of automated bin picking systems using deep learning is evolving to support increasing demand for e-commerce. To accommodate a wide variety of products, many automated systems include multiple gripper types and/or tool changers. However, for some objects, sequential grasp failures are common: when a computed grasp fails to lift and remove the object, the bin is often left unchanged; as the sensor input is consistent, the system retries the same grasp over and over, resulting in a significant reduction in mean successful picks per hour (MPPH). Based on an empirical study of sequential failures, we characterize a class of "sequential failure objects" (SFOs) -- objects prone to sequential failures based on a novel taxonomy. We then propose three non-Markov picking policies that incorporate memory of past failures to modify subsequent actions. Simulation experiments on SFO models and the EGAD dataset suggest that the non-Markov policies significantly outperform the Markov policy in terms of the sequential failure rate and MPPH. In physical experiments on 50 heaps of 12 SFOs the most effective Non-Markov policy increased MPPH over the Dex-Net Markov policy by 107%.