 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeter Jansen
Enhancing Systematic Decompositional Natural Language Inference Using Informal Logic
Feb 27, 2024
Contemporary language models enable new opportunities for structured reasoning with text, such as the construction and evaluation of intuitive, proof-like textual entailment trees without relying on brittle formal logic. However, progress in this direction has been hampered by a long-standing lack of a clear protocol for determining what valid compositional entailment is. This absence causes noisy datasets and limited performance gains by modern neuro-symbolic engines. To address these problems, we formulate a consistent and theoretically grounded approach to annotating decompositional entailment datasets, and evaluate its impact on LLM-based textual inference. We find that our resulting dataset, RDTE (Recognizing Decompositional Textual Entailment), has a substantially higher internal consistency (+9%) than prior decompositional entailment datasets, suggesting that RDTE is a significant step forward in the long-standing problem of forming a clear protocol for discerning entailment. We also find that training an RDTE-oriented entailment classifier via knowledge distillation and employing it in a modern neuro-symbolic reasoning engine significantly improves results (both accuracy and proof quality) over other entailment classifier baselines, illustrating the practical benefit of this advance for textual inference.
Self-Supervised Behavior Cloned Transformers are Path Crawlers for Text Games
Dec 07, 2023In this work, we introduce a self-supervised behavior cloning transformer for text games, which are challenging benchmarks for multi-step reasoning in virtual environments. Traditionally, Behavior Cloning Transformers excel in such tasks but rely on supervised training data. Our approach auto-generates training data by exploring trajectories (defined by common macro-action sequences) that lead to reward within the games, while determining the generality and utility of these trajectories by rapidly training small models then evaluating their performance on unseen development games. Through empirical analysis, we show our method consistently uncovers generalizable training data, achieving about 90\% performance of supervised systems across three benchmark text games.
CLIN: A Continually Learning Language Agent for Rapid Task Adaptation and Generalization
Oct 16, 2023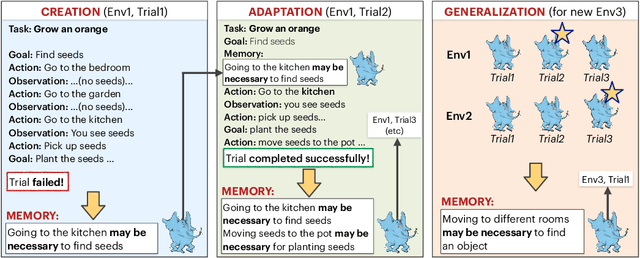
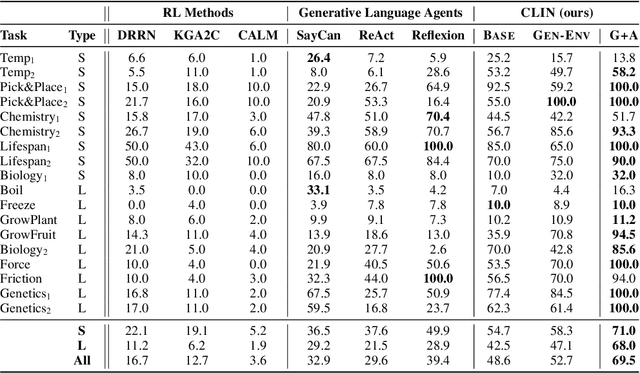

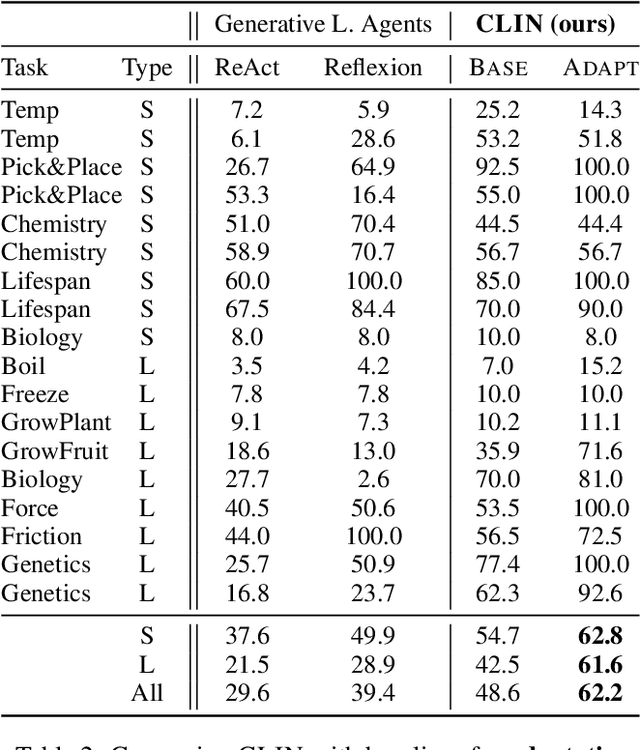
Language agents have shown some ability to interact with an external environment, e.g., a virtual world such as ScienceWorld, to perform complex tasks, e.g., growing a plant, without the startup costs of reinforcement learning. However, despite their zero-shot capabilities, these agents to date do not continually improve over time beyond performance refinement on a specific task. Here we present CLIN, the first language-based agent to achieve this, so that it continually improves over multiple trials, including when both the environment and task are varied, and without requiring parameter updates. Our approach is to use a persistent, dynamic, textual memory centered on causal abstractions (rather than general "helpful hints") that is regularly updated after each trial so that the agent gradually learns useful knowledge for new trials. In the ScienceWorld benchmark, CLIN is able to continually improve on repeated trials on the same task and environment, outperforming state-of-the-art reflective language agents like Reflexion by 23 absolute points. CLIN can also transfer its learning to new environments (or new tasks), improving its zero-shot performance by 4 points (13 for new tasks) and can further improve performance there through continual memory updates, enhancing performance by an additional 17 points (7 for new tasks). This suggests a new architecture for agents built on frozen models that can still continually and rapidly improve over time.
ByteSized32: A Corpus and Challenge Task for Generating Task-Specific World Models Expressed as Text Games
May 24, 2023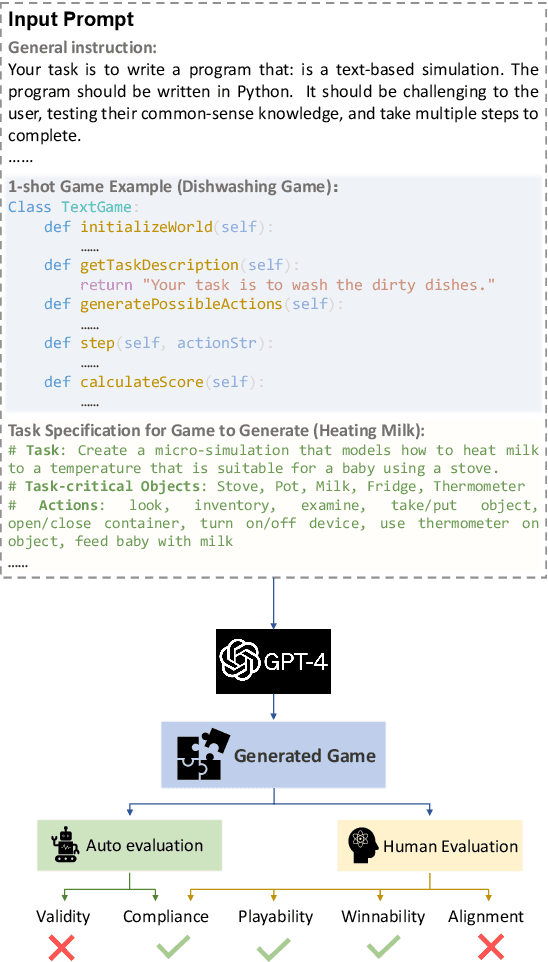


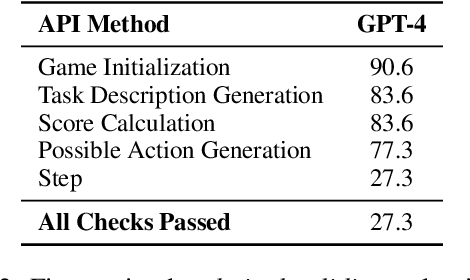
In this work we examine the ability of language models to generate explicit world models of scientific and common-sense reasoning tasks by framing this as a problem of generating text-based games. To support this, we introduce ByteSized32, a corpus of 32 highly-templated text games written in Python totaling 24k lines of code, each centered around a particular task, and paired with a set of 16 unseen text game specifications for evaluation. We propose a suite of automatic and manual metrics for assessing simulation validity, compliance with task specifications, playability, winnability, and alignment with the physical world. In a single-shot evaluation of GPT-4 on this simulation-as-code-generation task, we find it capable of producing runnable games in 27% of cases, highlighting the difficulty of this challenge task. We discuss areas of future improvement, including GPT-4's apparent capacity to perform well at simulating near canonical task solutions, with performance dropping off as simulations include distractors or deviate from canonical solutions in the action space.
From Words to Wires: Generating Functioning Electronic Devices from Natural Language Descriptions
May 24, 2023



In this work, we show that contemporary language models have a previously unknown skill -- the capacity for electronic circuit design from high-level textual descriptions, akin to code generation. We introduce two benchmarks: Pins100, assessing model knowledge of electrical components, and Micro25, evaluating a model's capability to design common microcontroller circuits and code in the Arduino ecosystem that involve input, output, sensors, motors, protocols, and logic -- with models such as GPT-4 and Claude-V1 achieving between 60% to 96% Pass@1 on generating full devices. We include six case studies of using language models as a design assistant for moderately complex devices, such as a radiation-powered random number generator, an emoji keyboard, a visible spectrometer, and several assistive devices, while offering a qualitative analysis performance, outlining evaluation challenges, and suggesting areas of development to improve complex circuit design and practical utility. With this work, we aim to spur research at the juncture of natural language processing and electronic design.
Behavior Cloned Transformers are Neurosymbolic Reasoners
Oct 13, 2022

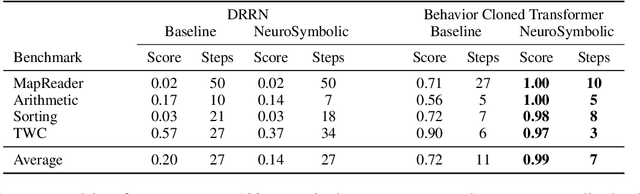
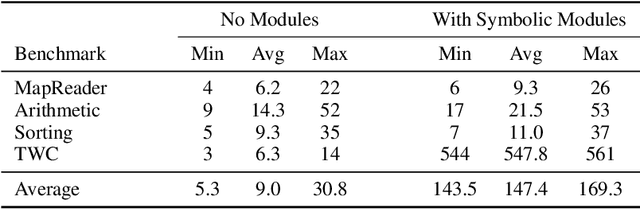
In this work, we explore techniques for augmenting interactive agents with information from symbolic modules, much like humans use tools like calculators and GPS systems to assist with arithmetic and navigation. We test our agent's abilities in text games -- challenging benchmarks for evaluating the multi-step reasoning abilities of game agents in grounded, language-based environments. Our experimental study indicates that injecting the actions from these symbolic modules into the action space of a behavior cloned transformer agent increases performance on four text game benchmarks that test arithmetic, navigation, sorting, and common sense reasoning by an average of 22%, allowing an agent to reach the highest possible performance on unseen games. This action injection technique is easily extended to new agents, environments, and symbolic modules.
ScienceWorld: Is your Agent Smarter than a 5th Grader?
Mar 14, 2022



This paper presents a new benchmark, ScienceWorld, to test agents' scientific reasoning abilities in a new interactive text environment at the level of a standard elementary school science curriculum. Despite the recent transformer-based progress seen in adjacent fields such as question-answering, scientific text processing, and the wider area of natural language processing, we find that current state-of-the-art models are unable to reason about or explain learned science concepts in novel contexts. For instance, models can easily answer what the conductivity of a previously seen material is but struggle when asked how they would conduct an experiment in a grounded, interactive environment to find the conductivity of an unknown material. This begs the question of whether current models are simply retrieving answers by way of seeing a large number of similar input examples or if they have learned to reason about concepts in a reusable manner. We hypothesize that agents need to be grounded in interactive environments to achieve such reasoning capabilities. Our experiments provide empirical evidence supporting this hypothesis -- showing that a 1.5 million parameter agent trained interactively for 100k steps outperforms a 11 billion parameter model statically trained for scientific question-answering and reasoning via millions of expert demonstrations.
Extracting Space Situational Awareness Events from News Text
Jan 15, 2022



Space situational awareness typically makes use of physical measurements from radar, telescopes, and other assets to monitor satellites and other spacecraft for operational, navigational, and defense purposes. In this work we explore using textual input for the space situational awareness task. We construct a corpus of 48.5k news articles spanning all known active satellites between 2009 and 2020. Using a dependency-rule-based extraction system designed to target three high-impact events -- spacecraft launches, failures, and decommissionings, we identify 1,787 space-event sentences that are then annotated by humans with 15.9k labels for event slots. We empirically demonstrate a state-of-the-art neural extraction system achieves an overall F1 between 53 and 91 per slot for event extraction in this low-resource, high-impact domain.
On the Challenges of Evaluating Compositional Explanations in Multi-Hop Inference: Relevance, Completeness, and Expert Ratings
Sep 07, 2021



Building compositional explanations requires models to combine two or more facts that, together, describe why the answer to a question is correct. Typically, these "multi-hop" explanations are evaluated relative to one (or a small number of) gold explanations. In this work, we show these evaluations substantially underestimate model performance, both in terms of the relevance of included facts, as well as the completeness of model-generated explanations, because models regularly discover and produce valid explanations that are different than gold explanations. To address this, we construct a large corpus of 126k domain-expert (science teacher) relevance ratings that augment a corpus of explanations to standardized science exam questions, discovering 80k additional relevant facts not rated as gold. We build three strong models based on different methodologies (generation, ranking, and schemas), and empirically show that while expert-augmented ratings provide better estimates of explanation quality, both original (gold) and expert-augmented automatic evaluations still substantially underestimate performance by up to 36% when compared with full manual expert judgements, with different models being disproportionately affected. This poses a significant methodological challenge to accurately evaluating explanations produced by compositional reasoning models.
Darmok and Jalad at Tanagra: A Dataset and Model for English-to-Tamarian Translation
Jul 16, 2021

Tamarian, a fictional language introduced in the Star Trek episode Darmok, communicates meaning through utterances of metaphorical references, such as "Darmok and Jalad at Tanagra" instead of "We should work together." This work assembles a Tamarian-English dictionary of utterances from the original episode and several follow-on novels, and uses this to construct a parallel corpus of 456 English-Tamarian utterances. A machine translation system based on a large language model (T5) is trained using this parallel corpus, and is shown to produce an accuracy of 76% when translating from English to Tamarian on known utterances.