 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaohe Liu
SemantiCodec: An Ultra Low Bitrate Semantic Audio Codec for General Sound
Apr 30, 2024
Large language models (LLMs) have significantly advanced audio processing through audio codecs that convert audio into discrete tokens, enabling the application of language modelling techniques to audio data. However, traditional codecs often operate at high bitrates or within narrow domains such as speech and lack the semantic clues required for efficient language modelling. Addressing these challenges, we introduce SemantiCodec, a novel codec designed to compress audio into fewer than a hundred tokens per second across diverse audio types, including speech, general audio, and music, without compromising quality. SemantiCodec features a dual-encoder architecture: a semantic encoder using a self-supervised AudioMAE, discretized using k-means clustering on extensive audio data, and an acoustic encoder to capture the remaining details. The semantic and acoustic encoder outputs are used to reconstruct audio via a diffusion-model-based decoder. SemantiCodec is presented in three variants with token rates of 25, 50, and 100 per second, supporting a range of ultra-low bit rates between 0.31 kbps and 1.43 kbps. Experimental results demonstrate that SemantiCodec significantly outperforms the state-of-the-art Descript codec on reconstruction quality. Our results also suggest that SemantiCodec contains significantly richer semantic information than all evaluated audio codecs, even at significantly lower bitrates. Our code and demos are available at https://haoheliu.github.io/SemantiCodec/.
T-CLAP: Temporal-Enhanced Contrastive Language-Audio Pretraining
Apr 27, 2024Contrastive language-audio pretraining~(CLAP) has been developed to align the representations of audio and language, achieving remarkable performance in retrieval and classification tasks. However, current CLAP struggles to capture temporal information within audio and text features, presenting substantial limitations for tasks such as audio retrieval and generation. To address this gap, we introduce T-CLAP, a temporal-enhanced CLAP model. We use Large Language Models~(LLMs) and mixed-up strategies to generate temporal-contrastive captions for audio clips from extensive audio-text datasets. Subsequently, a new temporal-focused contrastive loss is designed to fine-tune the CLAP model by incorporating these synthetic data. We conduct comprehensive experiments and analysis in multiple downstream tasks. T-CLAP shows improved capability in capturing the temporal relationship of sound events and outperforms state-of-the-art models by a significant margin.
FlashSpeech: Efficient Zero-Shot Speech Synthesis
Apr 25, 2024Recent progress in large-scale zero-shot speech synthesis has been significantly advanced by language models and diffusion models. However, the generation process of both methods is slow and computationally intensive. Efficient speech synthesis using a lower computing budget to achieve quality on par with previous work remains a significant challenge. In this paper, we present FlashSpeech, a large-scale zero-shot speech synthesis system with approximately 5\% of the inference time compared with previous work. FlashSpeech is built on the latent consistency model and applies a novel adversarial consistency training approach that can train from scratch without the need for a pre-trained diffusion model as the teacher. Furthermore, a new prosody generator module enhances the diversity of prosody, making the rhythm of the speech sound more natural. The generation processes of FlashSpeech can be achieved efficiently with one or two sampling steps while maintaining high audio quality and high similarity to the audio prompt for zero-shot speech generation. Our experimental results demonstrate the superior performance of FlashSpeech. Notably, FlashSpeech can be about 20 times faster than other zero-shot speech synthesis systems while maintaining comparable performance in terms of voice quality and similarity. Furthermore, FlashSpeech demonstrates its versatility by efficiently performing tasks like voice conversion, speech editing, and diverse speech sampling. Audio samples can be found in https://flashspeech.github.io/.
WavCraft: Audio Editing and Generation with Natural Language Prompts
Mar 15, 2024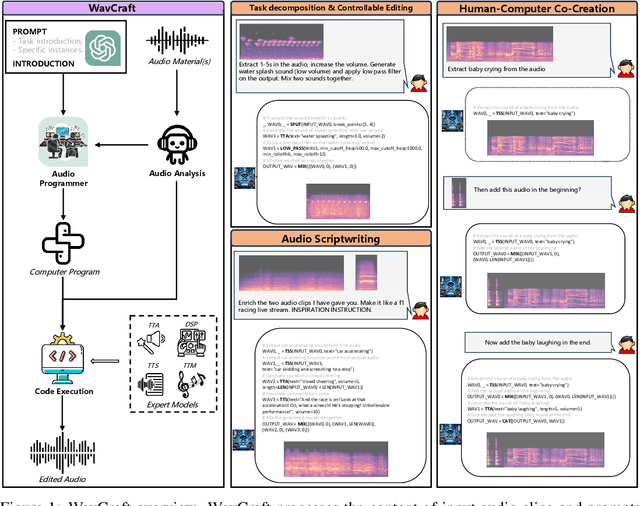
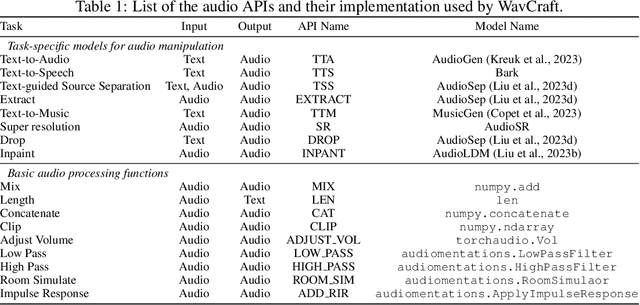
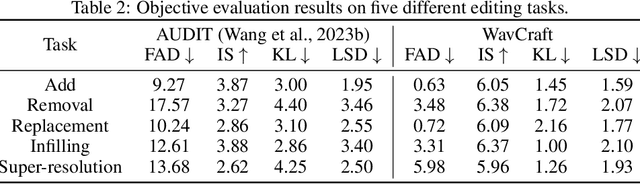

We introduce WavCraft, a collective system that leverages large language models (LLMs) to connect diverse task-specific models for audio content creation and editing. Specifically, WavCraft describes the content of raw sound materials in natural language and prompts the LLM conditioned on audio descriptions and users' requests. WavCraft leverages the in-context learning ability of the LLM to decomposes users' instructions into several tasks and tackle each task collaboratively with audio expert modules. Through task decomposition along with a set of task-specific models, WavCraft follows the input instruction to create or edit audio content with more details and rationales, facilitating users' control. In addition, WavCraft is able to cooperate with users via dialogue interaction and even produce the audio content without explicit user commands. Experiments demonstrate that WavCraft yields a better performance than existing methods, especially when adjusting the local regions of audio clips. Moreover, WavCraft can follow complex instructions to edit and even create audio content on the top of input recordings, facilitating audio producers in a broader range of applications. Our implementation and demos are available at https://github.com/JinhuaLiang/WavCraft.
Description on IEEE ICME 2024 Grand Challenge: Semi-supervised Acoustic Scene Classification under Domain Shift
Feb 05, 2024



Acoustic scene classification (ASC) is a crucial research problem in computational auditory scene analysis, and it aims to recognize the unique acoustic characteristics of an environment. One of the challenges of the ASC task is domain shift caused by a distribution gap between training and testing data. Since 2018, ASC challenges have focused on the generalization of ASC models across different recording devices. Although this task in recent years has achieved substantial progress in device generalization, the challenge of domain shift between different regions, involving characteristics such as time, space, culture, and language, remains insufficiently explored at present. In addition, considering the abundance of unlabeled acoustic scene data in the real world, it is important to study the possible ways to utilize these unlabelled data. Therefore, we introduce the task Semi-supervised Acoustic Scene Classification under Domain Shift in the ICME 2024 Grand Challenge. We encourage participants to innovate with semi-supervised learning techniques, aiming to develop more robust ASC models under domain shift.
Balanced SNR-Aware Distillation for Guided Text-to-Audio Generation
Dec 25, 2023Diffusion models have demonstrated promising results in text-to-audio generation tasks. However, their practical usability is hindered by slow sampling speeds, limiting their applicability in high-throughput scenarios. To address this challenge, progressive distillation methods have been effective in producing more compact and efficient models. Nevertheless, these methods encounter issues with unbalanced weights at both high and low noise levels, potentially impacting the quality of generated samples. In this paper, we propose the adaptation of the progressive distillation method to text-to-audio generation tasks and introduce the Balanced SNR-Aware~(BSA) method, an enhanced loss-weighting mechanism for diffusion distillation. The BSA method employs a balanced approach to weight the loss for both high and low noise levels. We evaluate our proposed method on the AudioCaps dataset and report experimental results showing superior performance during the reverse diffusion process compared to previous distillation methods with the same number of sampling steps. Furthermore, the BSA method allows for a significant reduction in sampling steps from 200 to 25, with minimal performance degradation when compared to the original teacher models.
First-Shot Unsupervised Anomalous Sound Detection With Unknown Anomalies Estimated by Metadata-Assisted Audio Generation
Oct 22, 2023First-shot (FS) unsupervised anomalous sound detection (ASD) is a brand-new task introduced in DCASE 2023 Challenge Task 2, where the anomalous sounds for the target machine types are unseen in training. Existing methods often rely on the availability of normal and abnormal sound data from the target machines. However, due to the lack of anomalous sound data for the target machine types, it becomes challenging when adapting the existing ASD methods to the first-shot task. In this paper, we propose a new framework for the first-shot unsupervised ASD, where metadata-assisted audio generation is used to estimate unknown anomalies, by utilising the available machine information (i.e., metadata and sound data) to fine-tune a text-to-audio generation model for generating the anomalous sounds that contain unique acoustic characteristics accounting for each different machine types. We then use the method of Time-Weighted Frequency domain audio Representation with Gaussian Mixture Model (TWFR-GMM) as the backbone to achieve the first-shot unsupervised ASD. Our proposed FS-TWFR-GMM method achieves competitive performance amongst top systems in DCASE 2023 Challenge Task 2, while requiring only 1% model parameters for detection, as validated in our experiments.
Synth-AC: Enhancing Audio Captioning with Synthetic Supervision
Sep 18, 2023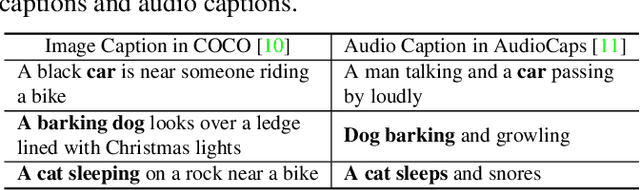
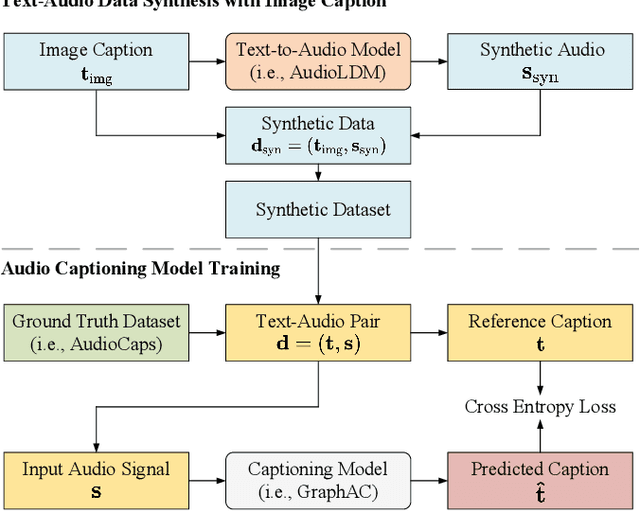


Data-driven approaches hold promise for audio captioning. However, the development of audio captioning methods can be biased due to the limited availability and quality of text-audio data. This paper proposes a SynthAC framework, which leverages recent advances in audio generative models and commonly available text corpus to create synthetic text-audio pairs, thereby enhancing text-audio representation. Specifically, the text-to-audio generation model, i.e., AudioLDM, is used to generate synthetic audio signals with captions from an image captioning dataset. Our SynthAC expands the availability of well-annotated captions from the text-vision domain to audio captioning, thus enhancing text-audio representation by learning relations within synthetic text-audio pairs. Experiments demonstrate that our SynthAC framework can benefit audio captioning models by incorporating well-annotated text corpus from the text-vision domain, offering a promising solution to the challenge caused by data scarcity. Furthermore, SynthAC can be easily adapted to various state-of-the-art methods, leading to substantial performance improvements.
Retrieval-Augmented Text-to-Audio Generation
Sep 14, 2023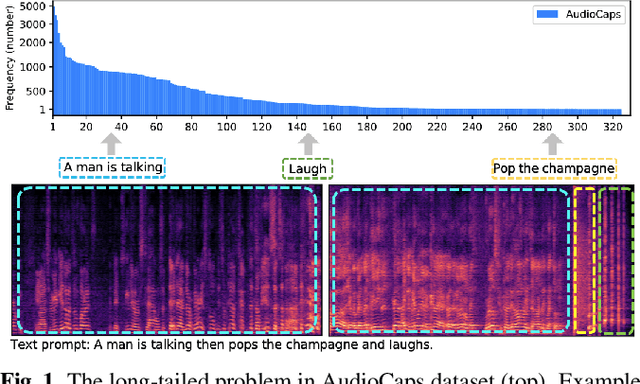

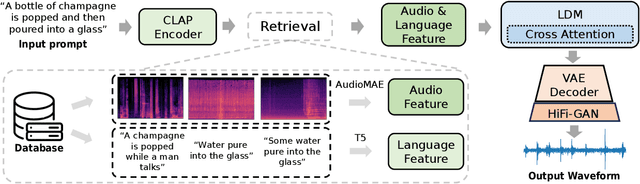
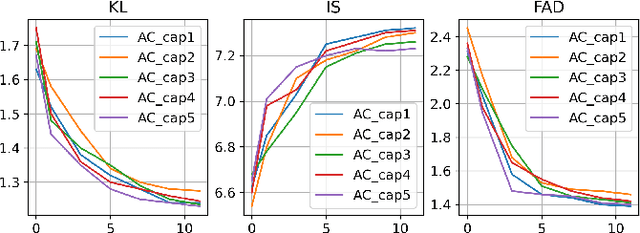
Despite recent progress in text-to-audio (TTA) generation, we show that the state-of-the-art models, such as AudioLDM, trained on datasets with an imbalanced class distribution, such as AudioCaps, are biased in their generation performance. Specifically, they excel in generating common audio classes while underperforming in the rare ones, thus degrading the overall generation performance. We refer to this problem as long-tailed text-to-audio generation. To address this issue, we propose a simple retrieval-augmented approach for TTA models. Specifically, given an input text prompt, we first leverage a Contrastive Language Audio Pretraining (CLAP) model to retrieve relevant text-audio pairs. The features of the retrieved audio-text data are then used as additional conditions to guide the learning of TTA models. We enhance AudioLDM with our proposed approach and denote the resulting augmented system as Re-AudioLDM. On the AudioCaps dataset, Re-AudioLDM achieves a state-of-the-art Frechet Audio Distance (FAD) of 1.37, outperforming the existing approaches by a large margin. Furthermore, we show that Re-AudioLDM can generate realistic audio for complex scenes, rare audio classes, and even unseen audio types, indicating its potential in TTA tasks.
AudioSR: Versatile Audio Super-resolution at Scale
Sep 13, 2023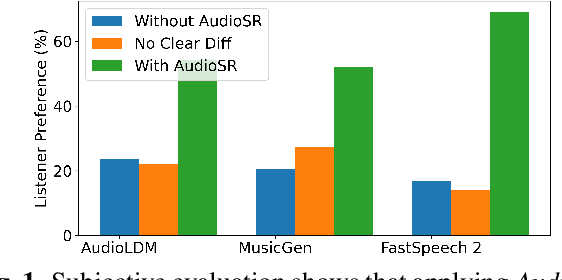

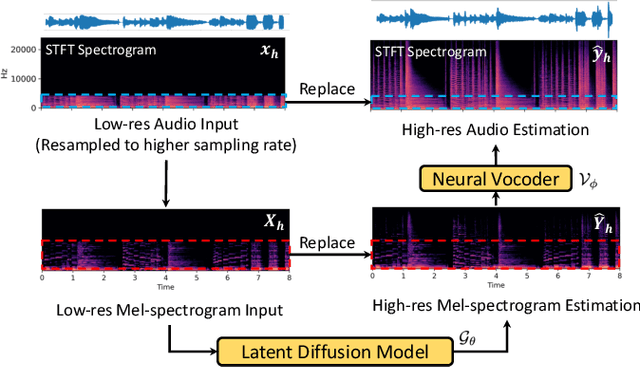

Audio super-resolution is a fundamental task that predicts high-frequency components for low-resolution audio, enhancing audio quality in digital applications. Previous methods have limitations such as the limited scope of audio types (e.g., music, speech) and specific bandwidth settings they can handle (e.g., 4kHz to 8kHz). In this paper, we introduce a diffusion-based generative model, AudioSR, that is capable of performing robust audio super-resolution on versatile audio types, including sound effects, music, and speech. Specifically, AudioSR can upsample any input audio signal within the bandwidth range of 2kHz to 16kHz to a high-resolution audio signal at 24kHz bandwidth with a sampling rate of 48kHz. Extensive objective evaluation on various audio super-resolution benchmarks demonstrates the strong result achieved by the proposed model. In addition, our subjective evaluation shows that AudioSR can acts as a plug-and-play module to enhance the generation quality of a wide range of audio generative models, including AudioLDM, Fastspeech2, and MusicGen. Our code and demo are available at https://audioldm.github.io/audiosr.