 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWenwu Wang
SemantiCodec: An Ultra Low Bitrate Semantic Audio Codec for General Sound
Apr 30, 2024
Large language models (LLMs) have significantly advanced audio processing through audio codecs that convert audio into discrete tokens, enabling the application of language modelling techniques to audio data. However, traditional codecs often operate at high bitrates or within narrow domains such as speech and lack the semantic clues required for efficient language modelling. Addressing these challenges, we introduce SemantiCodec, a novel codec designed to compress audio into fewer than a hundred tokens per second across diverse audio types, including speech, general audio, and music, without compromising quality. SemantiCodec features a dual-encoder architecture: a semantic encoder using a self-supervised AudioMAE, discretized using k-means clustering on extensive audio data, and an acoustic encoder to capture the remaining details. The semantic and acoustic encoder outputs are used to reconstruct audio via a diffusion-model-based decoder. SemantiCodec is presented in three variants with token rates of 25, 50, and 100 per second, supporting a range of ultra-low bit rates between 0.31 kbps and 1.43 kbps. Experimental results demonstrate that SemantiCodec significantly outperforms the state-of-the-art Descript codec on reconstruction quality. Our results also suggest that SemantiCodec contains significantly richer semantic information than all evaluated audio codecs, even at significantly lower bitrates. Our code and demos are available at https://haoheliu.github.io/SemantiCodec/.
ComposerX: Multi-Agent Symbolic Music Composition with LLMs
Apr 30, 2024Music composition represents the creative side of humanity, and itself is a complex task that requires abilities to understand and generate information with long dependency and harmony constraints. While demonstrating impressive capabilities in STEM subjects, current LLMs easily fail in this task, generating ill-written music even when equipped with modern techniques like In-Context-Learning and Chain-of-Thoughts. To further explore and enhance LLMs' potential in music composition by leveraging their reasoning ability and the large knowledge base in music history and theory, we propose ComposerX, an agent-based symbolic music generation framework. We find that applying a multi-agent approach significantly improves the music composition quality of GPT-4. The results demonstrate that ComposerX is capable of producing coherent polyphonic music compositions with captivating melodies, while adhering to user instructions.
T-CLAP: Temporal-Enhanced Contrastive Language-Audio Pretraining
Apr 27, 2024Contrastive language-audio pretraining~(CLAP) has been developed to align the representations of audio and language, achieving remarkable performance in retrieval and classification tasks. However, current CLAP struggles to capture temporal information within audio and text features, presenting substantial limitations for tasks such as audio retrieval and generation. To address this gap, we introduce T-CLAP, a temporal-enhanced CLAP model. We use Large Language Models~(LLMs) and mixed-up strategies to generate temporal-contrastive captions for audio clips from extensive audio-text datasets. Subsequently, a new temporal-focused contrastive loss is designed to fine-tune the CLAP model by incorporating these synthetic data. We conduct comprehensive experiments and analysis in multiple downstream tasks. T-CLAP shows improved capability in capturing the temporal relationship of sound events and outperforms state-of-the-art models by a significant margin.
WavCraft: Audio Editing and Generation with Natural Language Prompts
Mar 15, 2024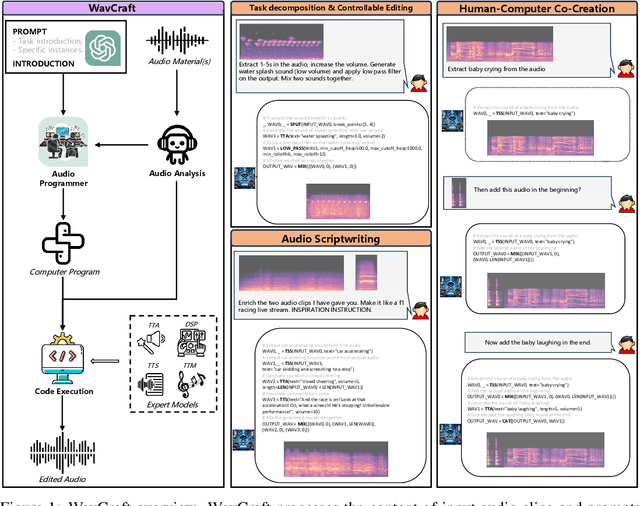
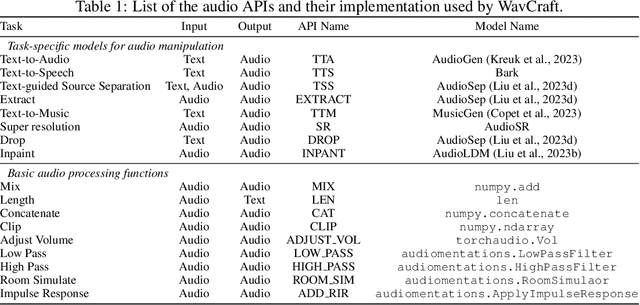
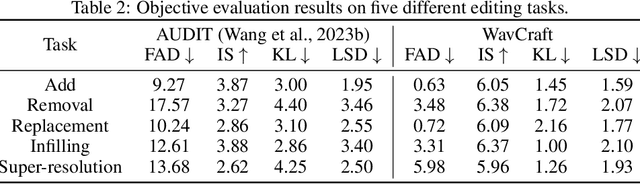

We introduce WavCraft, a collective system that leverages large language models (LLMs) to connect diverse task-specific models for audio content creation and editing. Specifically, WavCraft describes the content of raw sound materials in natural language and prompts the LLM conditioned on audio descriptions and users' requests. WavCraft leverages the in-context learning ability of the LLM to decomposes users' instructions into several tasks and tackle each task collaboratively with audio expert modules. Through task decomposition along with a set of task-specific models, WavCraft follows the input instruction to create or edit audio content with more details and rationales, facilitating users' control. In addition, WavCraft is able to cooperate with users via dialogue interaction and even produce the audio content without explicit user commands. Experiments demonstrate that WavCraft yields a better performance than existing methods, especially when adjusting the local regions of audio clips. Moreover, WavCraft can follow complex instructions to edit and even create audio content on the top of input recordings, facilitating audio producers in a broader range of applications. Our implementation and demos are available at https://github.com/JinhuaLiang/WavCraft.
Multi-level graph learning for audio event classification and human-perceived annoyance rating prediction
Dec 15, 2023WHO's report on environmental noise estimates that 22 M people suffer from chronic annoyance related to noise caused by audio events (AEs) from various sources. Annoyance may lead to health issues and adverse effects on metabolic and cognitive systems. In cities, monitoring noise levels does not provide insights into noticeable AEs, let alone their relations to annoyance. To create annoyance-related monitoring, this paper proposes a graph-based model to identify AEs in a soundscape, and explore relations between diverse AEs and human-perceived annoyance rating (AR). Specifically, this paper proposes a lightweight multi-level graph learning (MLGL) based on local and global semantic graphs to simultaneously perform audio event classification (AEC) and human annoyance rating prediction (ARP). Experiments show that: 1) MLGL with 4.1 M parameters improves AEC and ARP results by using semantic node information in local and global context aware graphs; 2) MLGL captures relations between coarse and fine-grained AEs and AR well; 3) Statistical analysis of MLGL results shows that some AEs from different sources significantly correlate with AR, which is consistent with previous research on human perception of these sound sources.
Fusion of Audio and Visual Embeddings for Sound Event Localization and Detection
Dec 14, 2023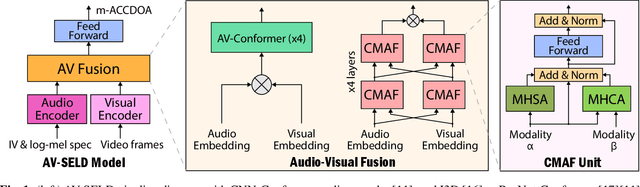
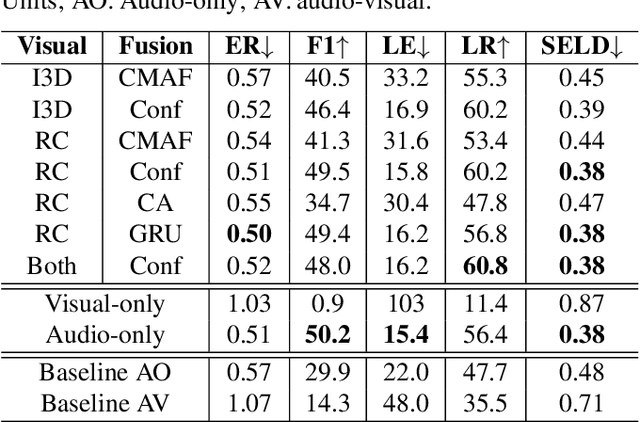

Sound event localization and detection (SELD) combines two subtasks: sound event detection (SED) and direction of arrival (DOA) estimation. SELD is usually tackled as an audio-only problem, but visual information has been recently included. Few audio-visual (AV)-SELD works have been published and most employ vision via face/object bounding boxes, or human pose keypoints. In contrast, we explore the integration of audio and visual feature embeddings extracted with pre-trained deep networks. For the visual modality, we tested ResNet50 and Inflated 3D ConvNet (I3D). Our comparison of AV fusion methods includes the AV-Conformer and Cross-Modal Attentive Fusion (CMAF) model. Our best models outperform the DCASE 2023 Task3 audio-only and AV baselines by a wide margin on the development set of the STARSS23 dataset, making them competitive amongst state-of-the-art results of the AV challenge, without model ensembling, heavy data augmentation, or prediction post-processing. Such techniques and further pre-training could be applied as next steps to improve performance.
Acoustic Prompt Tuning: Empowering Large Language Models with Audition Capabilities
Nov 30, 2023The auditory system plays a substantial role in shaping the overall human perceptual experience. While prevailing large language models (LLMs) and visual language models (VLMs) have shown their promise in solving a wide variety of vision and language understanding tasks, only a few of them can be generalised to the audio domain without compromising their domain-specific capacity. In this work, we introduce Acoustic Prompt Turning (APT), a new adapter extending LLMs and VLMs to the audio domain by soft prompting only. Specifically, APT applies an instruction-aware audio aligner to generate soft prompts, conditioned on both input text and sounds, as language model inputs. To mitigate the data scarcity in the audio domain, a multi-task learning strategy is proposed by formulating diverse audio tasks in a sequence-to-sequence manner. Moreover, we improve the framework of audio language model by using interleaved audio-text embeddings as the input sequence. This improved framework imposes zero constraints on the input format and thus is capable of tackling more understanding tasks, such as few-shot audio classification and audio reasoning. To further evaluate the reasoning ability of audio networks, we propose natural language audio reasoning (NLAR), a new task that analyses across two audio clips by comparison and summarization. Experiments show that APT-enhanced LLMs (namely APT-LLMs) achieve competitive results compared to the expert models (i.e., the networks trained on the targeted datasets) across various tasks. We finally demonstrate the APT's ability in extending frozen VLMs to the audio domain without finetuning, achieving promising results in the audio-visual question and answering task. Our code and model weights are released at https://github.com/JinhuaLiang/APT.
Audio-Visual Speaker Tracking: Progress, Challenges, and Future Directions
Oct 23, 2023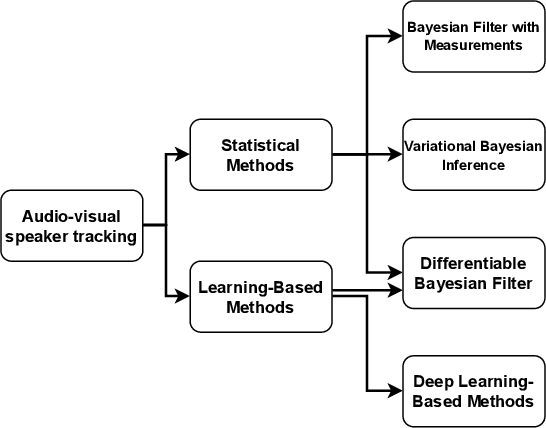
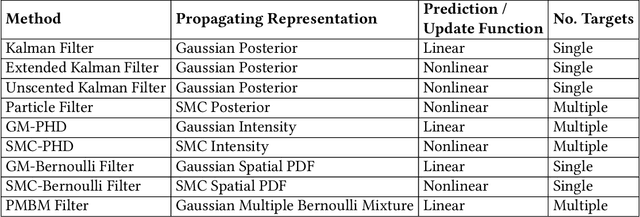

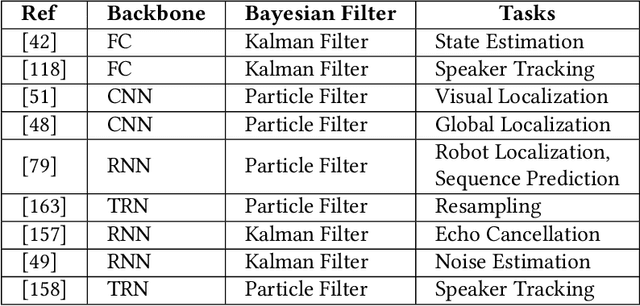
Audio-visual speaker tracking has drawn increasing attention over the past few years due to its academic values and wide application. Audio and visual modalities can provide complementary information for localization and tracking. With audio and visual information, the Bayesian-based filter can solve the problem of data association, audio-visual fusion and track management. In this paper, we conduct a comprehensive overview of audio-visual speaker tracking. To our knowledge, this is the first extensive survey over the past five years. We introduce the family of Bayesian filters and summarize the methods for obtaining audio-visual measurements. In addition, the existing trackers and their performance on AV16.3 dataset are summarized. In the past few years, deep learning techniques have thrived, which also boosts the development of audio visual speaker tracking. The influence of deep learning techniques in terms of measurement extraction and state estimation is also discussed. At last, we discuss the connections between audio-visual speaker tracking and other areas such as speech separation and distributed speaker tracking.
First-Shot Unsupervised Anomalous Sound Detection With Unknown Anomalies Estimated by Metadata-Assisted Audio Generation
Oct 22, 2023First-shot (FS) unsupervised anomalous sound detection (ASD) is a brand-new task introduced in DCASE 2023 Challenge Task 2, where the anomalous sounds for the target machine types are unseen in training. Existing methods often rely on the availability of normal and abnormal sound data from the target machines. However, due to the lack of anomalous sound data for the target machine types, it becomes challenging when adapting the existing ASD methods to the first-shot task. In this paper, we propose a new framework for the first-shot unsupervised ASD, where metadata-assisted audio generation is used to estimate unknown anomalies, by utilising the available machine information (i.e., metadata and sound data) to fine-tune a text-to-audio generation model for generating the anomalous sounds that contain unique acoustic characteristics accounting for each different machine types. We then use the method of Time-Weighted Frequency domain audio Representation with Gaussian Mixture Model (TWFR-GMM) as the backbone to achieve the first-shot unsupervised ASD. Our proposed FS-TWFR-GMM method achieves competitive performance amongst top systems in DCASE 2023 Challenge Task 2, while requiring only 1% model parameters for detection, as validated in our experiments.
Transformer-based Autoencoder with ID Constraint for Unsupervised Anomalous Sound Detection
Oct 13, 2023Unsupervised anomalous sound detection (ASD) aims to detect unknown anomalous sounds of devices when only normal sound data is available. The autoencoder (AE) and self-supervised learning based methods are two mainstream methods. However, the AE-based methods could be limited as the feature learned from normal sounds can also fit with anomalous sounds, reducing the ability of the model in detecting anomalies from sound. The self-supervised methods are not always stable and perform differently, even for machines of the same type. In addition, the anomalous sound may be short-lived, making it even harder to distinguish from normal sound. This paper proposes an ID constrained Transformer-based autoencoder (IDC-TransAE) architecture with weighted anomaly score computation for unsupervised ASD. Machine ID is employed to constrain the latent space of the Transformer-based autoencoder (TransAE) by introducing a simple ID classifier to learn the difference in the distribution for the same machine type and enhance the ability of the model in distinguishing anomalous sound. Moreover, weighted anomaly score computation is introduced to highlight the anomaly scores of anomalous events that only appear for a short time. Experiments performed on DCASE 2020 Challenge Task2 development dataset demonstrate the effectiveness and superiority of our proposed method.