 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuibin Yuan
ComposerX: Multi-Agent Symbolic Music Composition with LLMs
Apr 30, 2024
Music composition represents the creative side of humanity, and itself is a complex task that requires abilities to understand and generate information with long dependency and harmony constraints. While demonstrating impressive capabilities in STEM subjects, current LLMs easily fail in this task, generating ill-written music even when equipped with modern techniques like In-Context-Learning and Chain-of-Thoughts. To further explore and enhance LLMs' potential in music composition by leveraging their reasoning ability and the large knowledge base in music history and theory, we propose ComposerX, an agent-based symbolic music generation framework. We find that applying a multi-agent approach significantly improves the music composition quality of GPT-4. The results demonstrate that ComposerX is capable of producing coherent polyphonic music compositions with captivating melodies, while adhering to user instructions.
MuPT: A Generative Symbolic Music Pretrained Transformer
Apr 10, 2024In this paper, we explore the application of Large Language Models (LLMs) to the pre-training of music. While the prevalent use of MIDI in music modeling is well-established, our findings suggest that LLMs are inherently more compatible with ABC Notation, which aligns more closely with their design and strengths, thereby enhancing the model's performance in musical composition. To address the challenges associated with misaligned measures from different tracks during generation, we propose the development of a Synchronized Multi-Track ABC Notation (SMT-ABC Notation), which aims to preserve coherence across multiple musical tracks. Our contributions include a series of models capable of handling up to 8192 tokens, covering 90% of the symbolic music data in our training set. Furthermore, we explore the implications of the Symbolic Music Scaling Law (SMS Law) on model performance. The results indicate a promising direction for future research in music generation, offering extensive resources for community-led research through our open-source contributions.
Chinese Tiny LLM: Pretraining a Chinese-Centric Large Language Model
Apr 09, 2024In this study, we introduce CT-LLM, a 2B large language model (LLM) that illustrates a pivotal shift towards prioritizing the Chinese language in developing LLMs. Uniquely initiated from scratch, CT-LLM diverges from the conventional methodology by primarily incorporating Chinese textual data, utilizing an extensive corpus of 1,200 billion tokens, including 800 billion Chinese tokens, 300 billion English tokens, and 100 billion code tokens. This strategic composition facilitates the model's exceptional proficiency in understanding and processing Chinese, a capability further enhanced through alignment techniques. Demonstrating remarkable performance on the CHC-Bench, CT-LLM excels in Chinese language tasks, and showcases its adeptness in English through SFT. This research challenges the prevailing paradigm of training LLMs predominantly on English corpora and then adapting them to other languages, broadening the horizons for LLM training methodologies. By open-sourcing the full process of training a Chinese LLM, including a detailed data processing procedure with the obtained Massive Appropriate Pretraining Chinese Corpus (MAP-CC), a well-chosen multidisciplinary Chinese Hard Case Benchmark (CHC-Bench), and the 2B-size Chinese Tiny LLM (CT-LLM), we aim to foster further exploration and innovation in both academia and industry, paving the way for more inclusive and versatile language models.
The Fine Line: Navigating Large Language Model Pretraining with Down-streaming Capability Analysis
Apr 01, 2024Uncovering early-stage metrics that reflect final model performance is one core principle for large-scale pretraining. The existing scaling law demonstrates the power-law correlation between pretraining loss and training flops, which serves as an important indicator of the current training state for large language models. However, this principle only focuses on the model's compression properties on the training data, resulting in an inconsistency with the ability improvements on the downstream tasks. Some follow-up works attempted to extend the scaling-law to more complex metrics (such as hyperparameters), but still lacked a comprehensive analysis of the dynamic differences among various capabilities during pretraining. To address the aforementioned limitations, this paper undertakes a comprehensive comparison of model capabilities at various pretraining intermediate checkpoints. Through this analysis, we confirm that specific downstream metrics exhibit similar training dynamics across models of different sizes, up to 67 billion parameters. In addition to our core findings, we've reproduced Amber and OpenLLaMA, releasing their intermediate checkpoints. This initiative offers valuable resources to the research community and facilitates the verification and exploration of LLM pretraining by open-source researchers. Besides, we provide empirical summaries, including performance comparisons of different models and capabilities, and tuition of key metrics for different training phases. Based on these findings, we provide a more user-friendly strategy for evaluating the optimization state, offering guidance for establishing a stable pretraining process.
RQ-RAG: Learning to Refine Queries for Retrieval Augmented Generation
Mar 31, 2024Large Language Models (LLMs) exhibit remarkable capabilities but are prone to generating inaccurate or hallucinatory responses. This limitation stems from their reliance on vast pretraining datasets, making them susceptible to errors in unseen scenarios. To tackle these challenges, Retrieval-Augmented Generation (RAG) addresses this by incorporating external, relevant documents into the response generation process, thus leveraging non-parametric knowledge alongside LLMs' in-context learning abilities. However, existing RAG implementations primarily focus on initial input for context retrieval, overlooking the nuances of ambiguous or complex queries that necessitate further clarification or decomposition for accurate responses. To this end, we propose learning to Refine Query for Retrieval Augmented Generation (RQ-RAG) in this paper, endeavoring to enhance the model by equipping it with capabilities for explicit rewriting, decomposition, and disambiguation. Our experimental results indicate that our method, when applied to a 7B Llama2 model, surpasses the previous state-of-the-art (SOTA) by an average of 1.9\% across three single-hop QA datasets, and also demonstrates enhanced performance in handling complex, multi-hop QA datasets. Our code is available at https://github.com/chanchimin/RQ-RAG.
COIG-CQIA: Quality is All You Need for Chinese Instruction Fine-tuning
Mar 26, 2024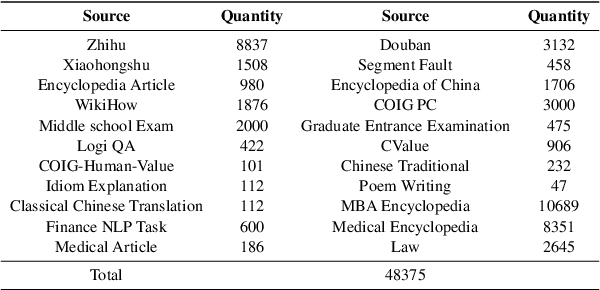
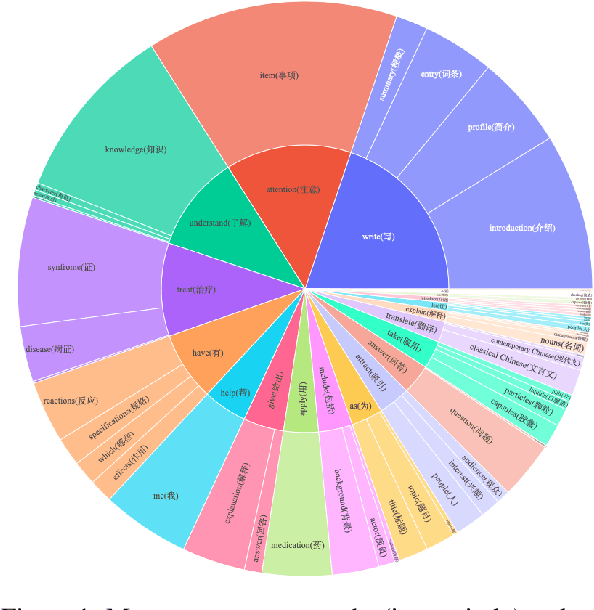
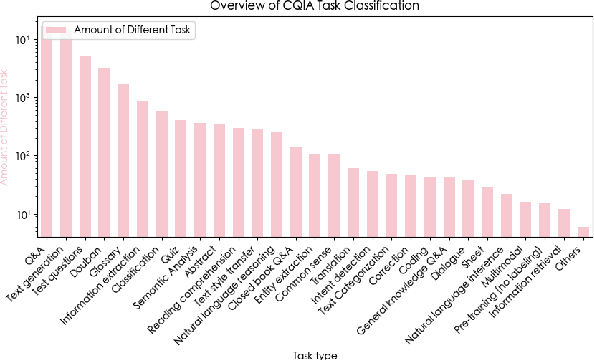
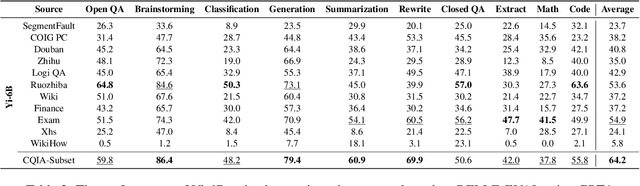
Recently, there have been significant advancements in large language models (LLMs), particularly focused on the English language. These advancements have enabled these LLMs to understand and execute complex instructions with unprecedented accuracy and fluency. However, despite these advancements, there remains a noticeable gap in the development of Chinese instruction tuning. The unique linguistic features and cultural depth of the Chinese language pose challenges for instruction tuning tasks. Existing datasets are either derived from English-centric LLMs or are ill-suited for aligning with the interaction patterns of real-world Chinese users. To bridge this gap, we introduce COIG-CQIA, a high-quality Chinese instruction tuning dataset. Our aim is to build a diverse, wide-ranging instruction-tuning dataset to better align model behavior with human interactions. To this end, we collect a high-quality human-written corpus from various sources on the Chinese Internet, including Q&A communities, Wikis, examinations, and existing NLP datasets. This corpus was rigorously filtered and carefully processed to form the COIG-CQIA dataset. Furthermore, we train models of various scales on different subsets of CQIA, following in-depth evaluation and analyses. The findings from our experiments offer valuable insights for selecting and developing Chinese instruction-tuning datasets. We also find that models trained on CQIA-Subset achieve competitive results in human assessment as well as knowledge and security benchmarks. Data are available at https://huggingface.co/datasets/m-a-p/COIG-CQIA
Modeling Analog Dynamic Range Compressors using Deep Learning and State-space Models
Mar 24, 2024We describe a novel approach for developing realistic digital models of dynamic range compressors for digital audio production by analyzing their analog prototypes. While realistic digital dynamic compressors are potentially useful for many applications, the design process is challenging because the compressors operate nonlinearly over long time scales. Our approach is based on the structured state space sequence model (S4), as implementing the state-space model (SSM) has proven to be efficient at learning long-range dependencies and is promising for modeling dynamic range compressors. We present in this paper a deep learning model with S4 layers to model the Teletronix LA-2A analog dynamic range compressor. The model is causal, executes efficiently in real time, and achieves roughly the same quality as previous deep-learning models but with fewer parameters.
AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling
Feb 26, 2024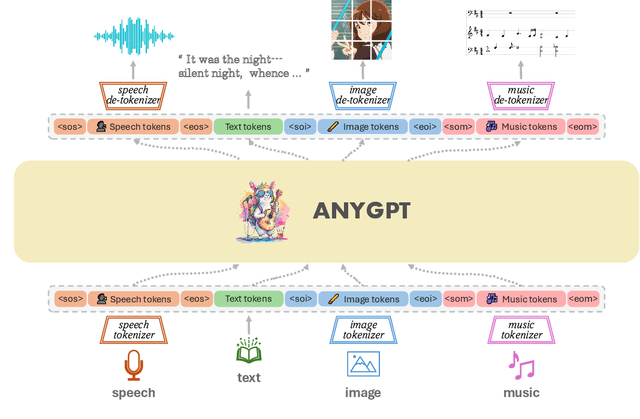

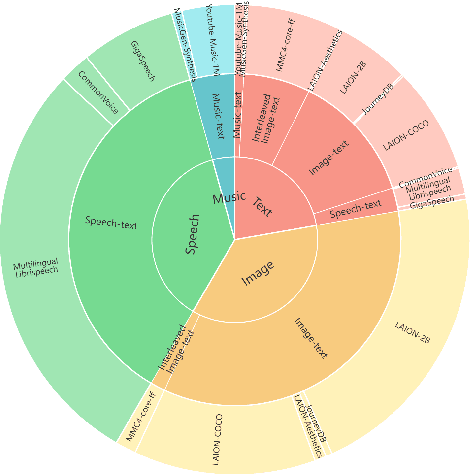
We introduce AnyGPT, an any-to-any multimodal language model that utilizes discrete representations for the unified processing of various modalities, including speech, text, images, and music. AnyGPT can be trained stably without any alterations to the current large language model (LLM) architecture or training paradigms. Instead, it relies exclusively on data-level preprocessing, facilitating the seamless integration of new modalities into LLMs, akin to the incorporation of new languages. We build a multimodal text-centric dataset for multimodal alignment pre-training. Utilizing generative models, we synthesize the first large-scale any-to-any multimodal instruction dataset. It consists of 108k samples of multi-turn conversations that intricately interweave various modalities, thus equipping the model to handle arbitrary combinations of multimodal inputs and outputs. Experimental results demonstrate that AnyGPT is capable of facilitating any-to-any multimodal conversation while achieving performance comparable to specialized models across all modalities, proving that discrete representations can effectively and conveniently unify multiple modalities within a language model. Demos are shown in https://junzhan2000.github.io/AnyGPT.github.io/
ChatMusician: Understanding and Generating Music Intrinsically with LLM
Feb 25, 2024While Large Language Models (LLMs) demonstrate impressive capabilities in text generation, we find that their ability has yet to be generalized to music, humanity's creative language. We introduce ChatMusician, an open-source LLM that integrates intrinsic musical abilities. It is based on continual pre-training and finetuning LLaMA2 on a text-compatible music representation, ABC notation, and the music is treated as a second language. ChatMusician can understand and generate music with a pure text tokenizer without any external multi-modal neural structures or tokenizers. Interestingly, endowing musical abilities does not harm language abilities, even achieving a slightly higher MMLU score. Our model is capable of composing well-structured, full-length music, conditioned on texts, chords, melodies, motifs, musical forms, etc, surpassing GPT-4 baseline. On our meticulously curated college-level music understanding benchmark, MusicTheoryBench, ChatMusician surpasses LLaMA2 and GPT-3.5 on zero-shot setting by a noticeable margin. Our work reveals that LLMs can be an excellent compressor for music, but there remains significant territory to be conquered. We release our 4B token music-language corpora MusicPile, the collected MusicTheoryBench, code, model and demo in GitHub.
CIF-Bench: A Chinese Instruction-Following Benchmark for Evaluating the Generalizability of Large Language Models
Feb 20, 2024The advancement of large language models (LLMs) has enhanced the ability to generalize across a wide range of unseen natural language processing (NLP) tasks through instruction-following. Yet, their effectiveness often diminishes in low-resource languages like Chinese, exacerbated by biased evaluations from data leakage, casting doubt on their true generalizability to new linguistic territories. In response, we introduce the Chinese Instruction-Following Benchmark (CIF-Bench), designed to evaluate the zero-shot generalizability of LLMs to the Chinese language. CIF-Bench comprises 150 tasks and 15,000 input-output pairs, developed by native speakers to test complex reasoning and Chinese cultural nuances across 20 categories. To mitigate evaluation bias, we release only half of the dataset publicly, with the remainder kept private, and introduce diversified instructions to minimize score variance, totaling 45,000 data instances. Our evaluation of 28 selected LLMs reveals a noticeable performance gap, with the best model scoring only 52.9%, highlighting the limitations of LLMs in less familiar language and task contexts. This work aims to uncover the current limitations of LLMs in handling Chinese tasks, pushing towards the development of more culturally informed and linguistically diverse models with the released data and benchmark (https://yizhilll.github.io/CIF-Bench/).