 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGus Xia
MuPT: A Generative Symbolic Music Pretrained Transformer
Apr 10, 2024
In this paper, we explore the application of Large Language Models (LLMs) to the pre-training of music. While the prevalent use of MIDI in music modeling is well-established, our findings suggest that LLMs are inherently more compatible with ABC Notation, which aligns more closely with their design and strengths, thereby enhancing the model's performance in musical composition. To address the challenges associated with misaligned measures from different tracks during generation, we propose the development of a Synchronized Multi-Track ABC Notation (SMT-ABC Notation), which aims to preserve coherence across multiple musical tracks. Our contributions include a series of models capable of handling up to 8192 tokens, covering 90% of the symbolic music data in our training set. Furthermore, we explore the implications of the Symbolic Music Scaling Law (SMS Law) on model performance. The results indicate a promising direction for future research in music generation, offering extensive resources for community-led research through our open-source contributions.
ChatMusician: Understanding and Generating Music Intrinsically with LLM
Feb 25, 2024While Large Language Models (LLMs) demonstrate impressive capabilities in text generation, we find that their ability has yet to be generalized to music, humanity's creative language. We introduce ChatMusician, an open-source LLM that integrates intrinsic musical abilities. It is based on continual pre-training and finetuning LLaMA2 on a text-compatible music representation, ABC notation, and the music is treated as a second language. ChatMusician can understand and generate music with a pure text tokenizer without any external multi-modal neural structures or tokenizers. Interestingly, endowing musical abilities does not harm language abilities, even achieving a slightly higher MMLU score. Our model is capable of composing well-structured, full-length music, conditioned on texts, chords, melodies, motifs, musical forms, etc, surpassing GPT-4 baseline. On our meticulously curated college-level music understanding benchmark, MusicTheoryBench, ChatMusician surpasses LLaMA2 and GPT-3.5 on zero-shot setting by a noticeable margin. Our work reveals that LLMs can be an excellent compressor for music, but there remains significant territory to be conquered. We release our 4B token music-language corpora MusicPile, the collected MusicTheoryBench, code, model and demo in GitHub.
Arrange, Inpaint, and Refine: Steerable Long-term Music Audio Generation and Editing via Content-based Controls
Feb 14, 2024Controllable music generation plays a vital role in human-AI music co-creation. While Large Language Models (LLMs) have shown promise in generating high-quality music, their focus on autoregressive generation limits their utility in music editing tasks. To bridge this gap, we introduce a novel Parameter-Efficient Fine-Tuning (PEFT) method. This approach enables autoregressive language models to seamlessly address music inpainting tasks. Additionally, our PEFT method integrates frame-level content-based controls, facilitating track-conditioned music refinement and score-conditioned music arrangement. We apply this method to fine-tune MusicGen, a leading autoregressive music generation model. Our experiments demonstrate promising results across multiple music editing tasks, offering more flexible controls for future AI-driven music editing tools. A demo page\footnote{\url{https://kikyo-16.github.io/AIR/}.} showcasing our work and source codes\footnote{\url{https://github.com/Kikyo-16/airgen}.} are available online.
MusicMagus: Zero-Shot Text-to-Music Editing via Diffusion Models
Feb 09, 2024Recent advances in text-to-music generation models have opened new avenues in musical creativity. However, music generation usually involves iterative refinements, and how to edit the generated music remains a significant challenge. This paper introduces a novel approach to the editing of music generated by such models, enabling the modification of specific attributes, such as genre, mood and instrument, while maintaining other aspects unchanged. Our method transforms text editing to \textit{latent space manipulation} while adding an extra constraint to enforce consistency. It seamlessly integrates with existing pretrained text-to-music diffusion models without requiring additional training. Experimental results demonstrate superior performance over both zero-shot and certain supervised baselines in style and timbre transfer evaluations. Additionally, we showcase the practical applicability of our approach in real-world music editing scenarios.
CalliPaint: Chinese Calligraphy Inpainting with Diffusion Model
Dec 03, 2023Chinese calligraphy can be viewed as a unique form of visual art. Recent advancements in computer vision hold significant potential for the future development of generative models in the realm of Chinese calligraphy. Nevertheless, methods of Chinese calligraphy inpainting, which can be effectively used in the art and education fields, remain relatively unexplored. In this paper, we introduce a new model that harnesses recent advancements in both Chinese calligraphy generation and image inpainting. We demonstrate that our proposed model CalliPaint can produce convincing Chinese calligraphy.
Content-based Controls For Music Large Language Modeling
Oct 26, 2023Recent years have witnessed a rapid growth of large-scale language models in the domain of music audio. Such models enable end-to-end generation of higher-quality music, and some allow conditioned generation using text descriptions. However, the control power of text controls on music is intrinsically limited, as they can only describe music indirectly through meta-data (such as singers and instruments) or high-level representations (such as genre and emotion). We aim to further equip the models with direct and content-based controls on innate music languages such as pitch, chords and drum track. To this end, we contribute Coco-Mulla, a content-based control method for music large language modeling. It uses a parameter-efficient fine-tuning (PEFT) method tailored for Transformer-based audio models. Experiments show that our approach achieved high-quality music generation with low-resource semi-supervised learning, tuning with less than 4% parameters compared to the original model and training on a small dataset with fewer than 300 songs. Moreover, our approach enables effective content-based controls, and we illustrate the control power via chords and rhythms, two of the most salient features of music audio. Furthermore, we show that by combining content-based controls and text descriptions, our system achieves flexible music variation generation and style transfer. Our source codes and demos are available online.
AccoMontage-3: Full-Band Accompaniment Arrangement via Sequential Style Transfer and Multi-Track Function Prior
Oct 25, 2023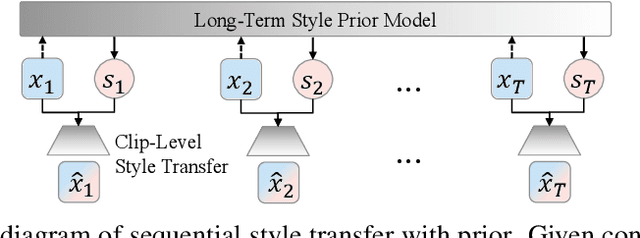
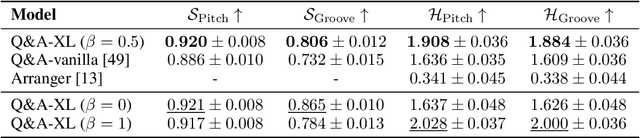

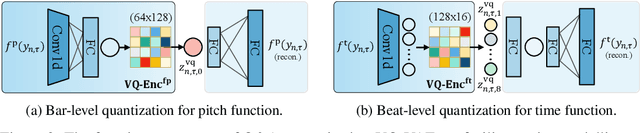
We propose AccoMontage-3, a symbolic music automation system capable of generating multi-track, full-band accompaniment based on the input of a lead melody with chords (i.e., a lead sheet). The system contains three modular components, each modelling a vital aspect of full-band composition. The first component is a piano arranger that generates piano accompaniment for the lead sheet by transferring texture styles to the chords using latent chord-texture disentanglement and heuristic retrieval of texture donors. The second component orchestrates the piano accompaniment score into full-band arrangement according to the orchestration style encoded by individual track functions. The third component, which connects the previous two, is a prior model characterizing the global structure of orchestration style over the whole piece of music. From end to end, the system learns to generate full-band accompaniment in a self-supervised fashion, applying style transfer at two levels of polyphonic composition: texture and orchestration. Experiments show that our system outperforms the baselines significantly, and the modular design offers effective controls in a musically meaningful way.
Loop Copilot: Conducting AI Ensembles for Music Generation and Iterative Editing
Oct 19, 2023Creating music is iterative, requiring varied methods at each stage. However, existing AI music systems fall short in orchestrating multiple subsystems for diverse needs. To address this gap, we introduce Loop Copilot, a novel system that enables users to generate and iteratively refine music through an interactive, multi-round dialogue interface. The system uses a large language model to interpret user intentions and select appropriate AI models for task execution. Each backend model is specialized for a specific task, and their outputs are aggregated to meet the user's requirements. To ensure musical coherence, essential attributes are maintained in a centralized table. We evaluate the effectiveness of the proposed system through semi-structured interviews and questionnaires, highlighting its utility not only in facilitating music creation but also its potential for broader applications.
Motif-Centric Representation Learning for Symbolic Music
Sep 19, 2023
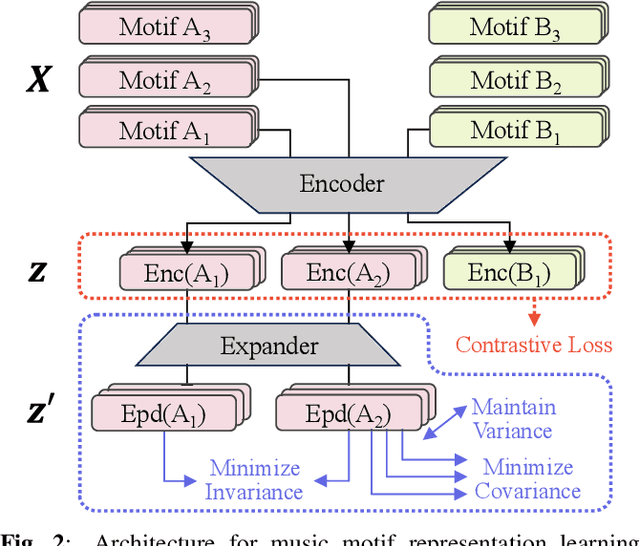
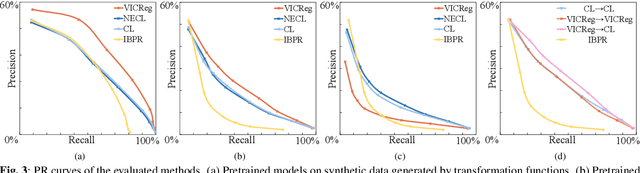
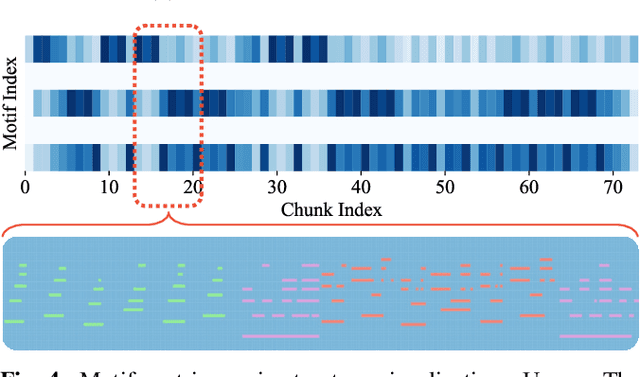
Music motif, as a conceptual building block of composition, is crucial for music structure analysis and automatic composition. While human listeners can identify motifs easily, existing computational models fall short in representing motifs and their developments. The reason is that the nature of motifs is implicit, and the diversity of motif variations extends beyond simple repetitions and modulations. In this study, we aim to learn the implicit relationship between motifs and their variations via representation learning, using the Siamese network architecture and a pretraining and fine-tuning pipeline. A regularization-based method, VICReg, is adopted for pretraining, while contrastive learning is used for fine-tuning. Experimental results on a retrieval-based task show that these two methods complement each other, yielding an improvement of 12.6% in the area under the precision-recall curve. Lastly, we visualize the acquired motif representations, offering an intuitive comprehension of the overall structure of a music piece. As far as we know, this work marks a noteworthy step forward in computational modeling of music motifs. We believe that this work lays the foundations for future applications of motifs in automatic music composition and music information retrieval.
Polyffusion: A Diffusion Model for Polyphonic Score Generation with Internal and External Controls
Jul 19, 2023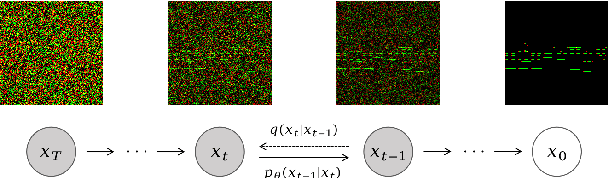

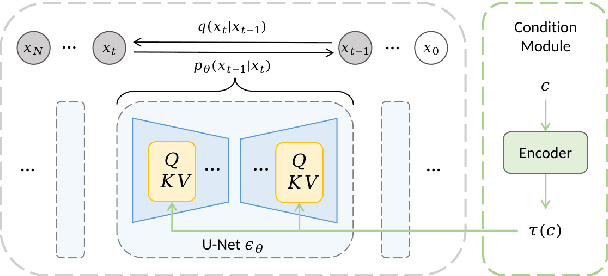
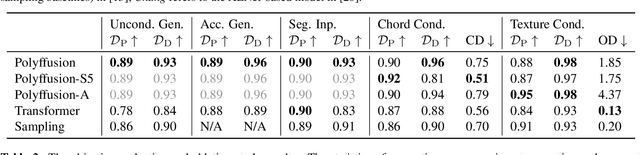
We propose Polyffusion, a diffusion model that generates polyphonic music scores by regarding music as image-like piano roll representations. The model is capable of controllable music generation with two paradigms: internal control and external control. Internal control refers to the process in which users pre-define a part of the music and then let the model infill the rest, similar to the task of masked music generation (or music inpainting). External control conditions the model with external yet related information, such as chord, texture, or other features, via the cross-attention mechanism. We show that by using internal and external controls, Polyffusion unifies a wide range of music creation tasks, including melody generation given accompaniment, accompaniment generation given melody, arbitrary music segment inpainting, and music arrangement given chords or textures. Experimental results show that our model significantly outperforms existing Transformer and sampling-based baselines, and using pre-trained disentangled representations as external conditions yields more effective controls.