 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYugang Jiang
AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling
Feb 26, 2024
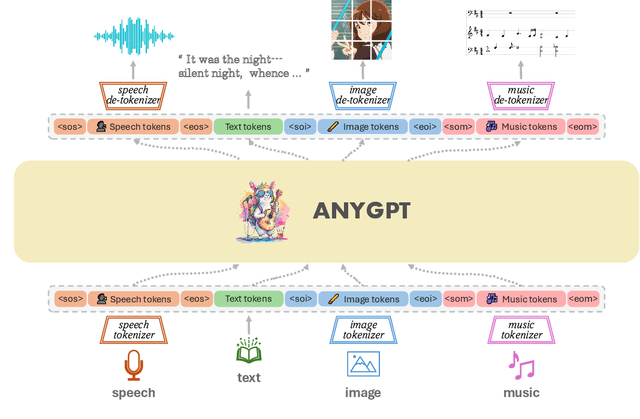

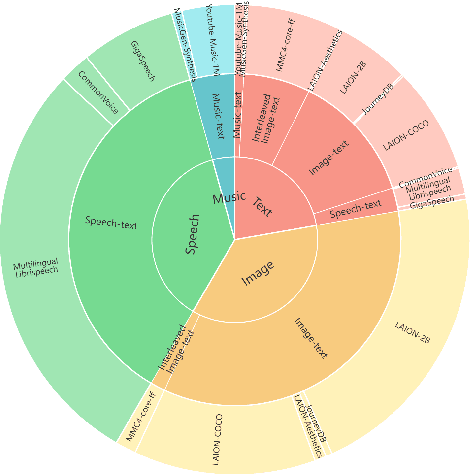
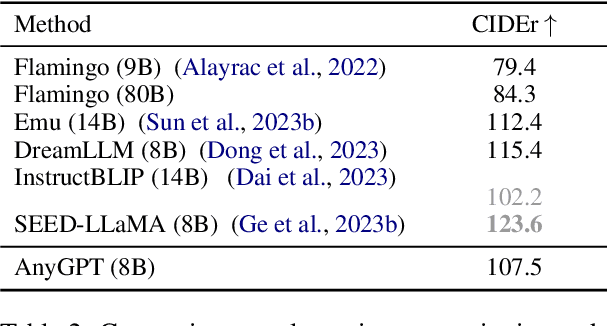
We introduce AnyGPT, an any-to-any multimodal language model that utilizes discrete representations for the unified processing of various modalities, including speech, text, images, and music. AnyGPT can be trained stably without any alterations to the current large language model (LLM) architecture or training paradigms. Instead, it relies exclusively on data-level preprocessing, facilitating the seamless integration of new modalities into LLMs, akin to the incorporation of new languages. We build a multimodal text-centric dataset for multimodal alignment pre-training. Utilizing generative models, we synthesize the first large-scale any-to-any multimodal instruction dataset. It consists of 108k samples of multi-turn conversations that intricately interweave various modalities, thus equipping the model to handle arbitrary combinations of multimodal inputs and outputs. Experimental results demonstrate that AnyGPT is capable of facilitating any-to-any multimodal conversation while achieving performance comparable to specialized models across all modalities, proving that discrete representations can effectively and conveniently unify multiple modalities within a language model. Demos are shown in https://junzhan2000.github.io/AnyGPT.github.io/
Unlearnable Clusters: Towards Label-agnostic Unlearnable Examples
Dec 31, 2022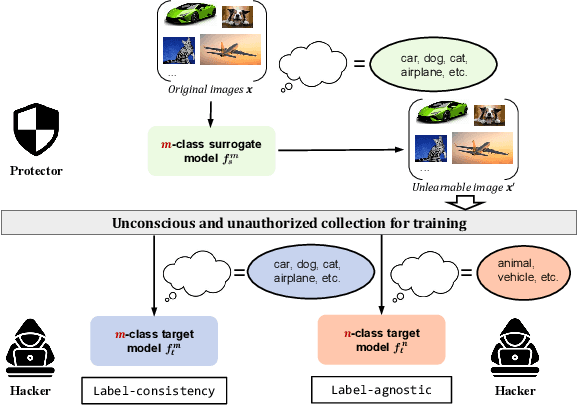
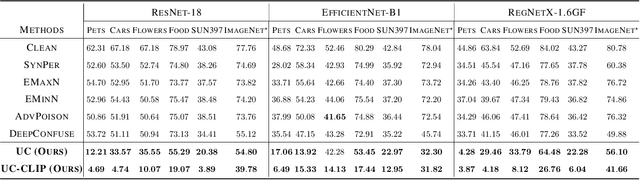
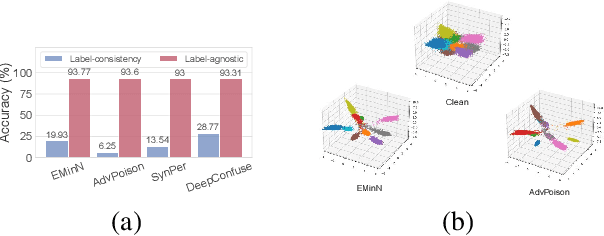
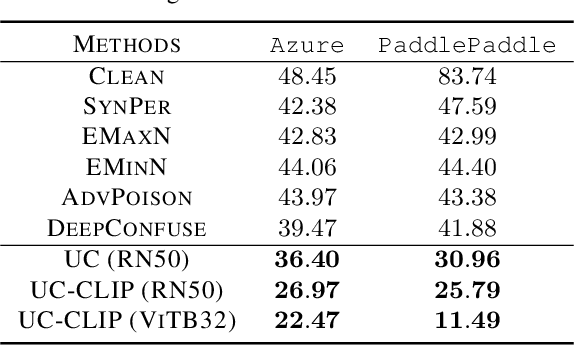
There is a growing interest in developing unlearnable examples (UEs) against visual privacy leaks on the Internet. UEs are training samples added with invisible but unlearnable noise, which have been found can prevent unauthorized training of machine learning models. UEs typically are generated via a bilevel optimization framework with a surrogate model to remove (minimize) errors from the original samples, and then applied to protect the data against unknown target models. However, existing UE generation methods all rely on an ideal assumption called label-consistency, where the hackers and protectors are assumed to hold the same label for a given sample. In this work, we propose and promote a more practical label-agnostic setting, where the hackers may exploit the protected data quite differently from the protectors. E.g., a m-class unlearnable dataset held by the protector may be exploited by the hacker as a n-class dataset. Existing UE generation methods are rendered ineffective in this challenging setting. To tackle this challenge, we present a novel technique called Unlearnable Clusters (UCs) to generate label-agnostic unlearnable examples with cluster-wise perturbations. Furthermore, we propose to leverage VisionandLanguage Pre-trained Models (VLPMs) like CLIP as the surrogate model to improve the transferability of the crafted UCs to diverse domains. We empirically verify the effectiveness of our proposed approach under a variety of settings with different datasets, target models, and even commercial platforms Microsoft Azure and Baidu PaddlePaddle.