 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRongyu Zhang
Second Edition FRCSyn Challenge at CVPR 2024: Face Recognition Challenge in the Era of Synthetic Data
Apr 16, 2024
Synthetic data is gaining increasing relevance for training machine learning models. This is mainly motivated due to several factors such as the lack of real data and intra-class variability, time and errors produced in manual labeling, and in some cases privacy concerns, among others. This paper presents an overview of the 2nd edition of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at CVPR 2024. FRCSyn aims to investigate the use of synthetic data in face recognition to address current technological limitations, including data privacy concerns, demographic biases, generalization to novel scenarios, and performance constraints in challenging situations such as aging, pose variations, and occlusions. Unlike the 1st edition, in which synthetic data from DCFace and GANDiffFace methods was only allowed to train face recognition systems, in this 2nd edition we propose new sub-tasks that allow participants to explore novel face generative methods. The outcomes of the 2nd FRCSyn Challenge, along with the proposed experimental protocol and benchmarking contribute significantly to the application of synthetic data to face recognition.
* arXiv admin note: text overlap with arXiv:2311.10476
Intuition-aware Mixture-of-Rank-1-Experts for Parameter Efficient Finetuning
Apr 13, 2024Large Language Models (LLMs) have demonstrated significant potential in performing multiple tasks in multimedia applications, ranging from content generation to interactive entertainment, and artistic creation. However, the diversity of downstream tasks in multitask scenarios presents substantial adaptation challenges for LLMs. While traditional methods often succumb to knowledge confusion on their monolithic dense models, Mixture-of-Experts (MoE) has been emerged as a promising solution with its sparse architecture for effective task decoupling. Inspired by the principles of human cognitive neuroscience, we design a novel framework \texttt{Intuition-MoR1E} that leverages the inherent semantic clustering of instances to mimic the human brain to deal with multitask, offering implicit guidance to router for optimized feature allocation. Moreover, we introduce cutting-edge Rank-1 Experts formulation designed to manage a spectrum of intuitions, demonstrating enhanced parameter efficiency and effectiveness in multitask LLM finetuning. Extensive experiments demonstrate that Intuition-MoR1E achieves superior efficiency and 2.15\% overall accuracy improvement across 14 public datasets against other state-of-the-art baselines.
VeCAF: VLM-empowered Collaborative Active Finetuning with Training Objective Awareness
Jan 15, 2024Finetuning a pretrained vision model (PVM) is a common technique for learning downstream vision tasks. The conventional finetuning process with the randomly sampled data points results in diminished training efficiency. To address this drawback, we propose a novel approach, VLM-empowered Collaborative Active Finetuning (VeCAF). VeCAF optimizes a parametric data selection model by incorporating the training objective of the model being tuned. Effectively, this guides the PVM towards the performance goal with improved data and computational efficiency. As vision-language models (VLMs) have achieved significant advancements by establishing a robust connection between image and language domains, we exploit the inherent semantic richness of the text embedding space and utilize text embedding of pretrained VLM models to augment PVM image features for better data selection and finetuning. Furthermore, the flexibility of text-domain augmentation gives VeCAF a unique ability to handle out-of-distribution scenarios without external augmented data. Extensive experiments show the leading performance and high efficiency of VeCAF that is superior to baselines in both in-distribution and out-of-distribution image classification tasks. On ImageNet, VeCAF needs up to 3.3x less training batches to reach the target performance compared to full finetuning and achieves 2.8% accuracy improvement over SOTA methods with the same number of batches.
Efficient Deweather Mixture-of-Experts with Uncertainty-aware Feature-wise Linear Modulation
Dec 27, 2023The Mixture-of-Experts (MoE) approach has demonstrated outstanding scalability in multi-task learning including low-level upstream tasks such as concurrent removal of multiple adverse weather effects. However, the conventional MoE architecture with parallel Feed Forward Network (FFN) experts leads to significant parameter and computational overheads that hinder its efficient deployment. In addition, the naive MoE linear router is suboptimal in assigning task-specific features to multiple experts which limits its further scalability. In this work, we propose an efficient MoE architecture with weight sharing across the experts. Inspired by the idea of linear feature modulation (FM), our architecture implicitly instantiates multiple experts via learnable activation modulations on a single shared expert block. The proposed Feature Modulated Expert (FME) serves as a building block for the novel Mixture-of-Feature-Modulation-Experts (MoFME) architecture, which can scale up the number of experts with low overhead. We further propose an Uncertainty-aware Router (UaR) to assign task-specific features to different FM modules with well-calibrated weights. This enables MoFME to effectively learn diverse expert functions for multiple tasks. The conducted experiments on the multi-deweather task show that our MoFME outperforms the baselines in the image restoration quality by 0.1-0.2 dB and achieves SOTA-compatible performance while saving more than 72% of parameters and 39% inference time over the conventional MoE counterpart. Experiments on the downstream segmentation and classification tasks further demonstrate the generalizability of MoFME to real open-world applications.
ChatIllusion: Efficient-Aligning Interleaved Generation ability with Visual Instruction Model
Nov 29, 2023As the capabilities of Large-Language Models (LLMs) become widely recognized, there is an increasing demand for human-machine chat applications. Human interaction with text often inherently invokes mental imagery, an aspect that existing LLM-based chatbots like GPT-4 do not currently emulate, as they are confined to generating text-only content. To bridge this gap, we introduce ChatIllusion, an advanced Generative multimodal large language model (MLLM) that combines the capabilities of LLM with not only visual comprehension but also creativity. Specifically, ChatIllusion integrates Stable Diffusion XL and Llama, which have been fine-tuned on modest image-caption data, to facilitate multiple rounds of illustrated chats. The central component of ChatIllusion is the "GenAdapter," an efficient approach that equips the multimodal language model with capabilities for visual representation, without necessitating modifications to the foundational model. Extensive experiments validate the efficacy of our approach, showcasing its ability to produce diverse and superior-quality image outputs Simultaneously, it preserves semantic consistency and control over the dialogue, significantly enhancing the overall user's quality of experience (QoE). The code is available at https://github.com/litwellchi/ChatIllusion.
NTIRE 2023 Quality Assessment of Video Enhancement Challenge
Jul 19, 2023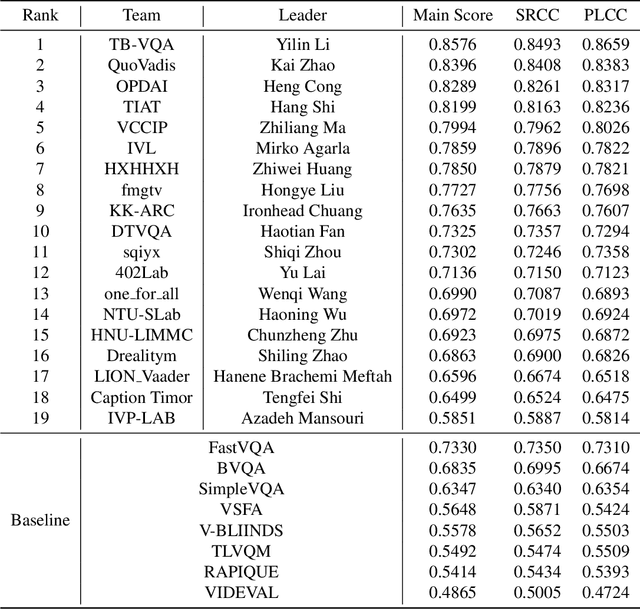
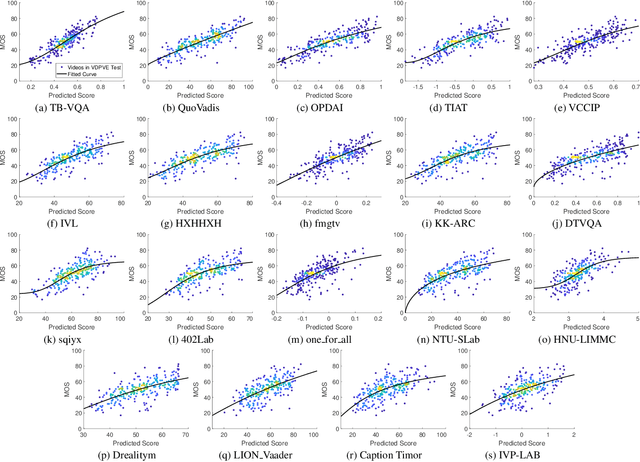
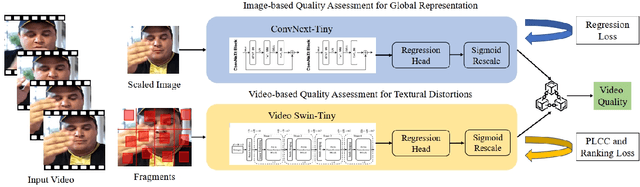
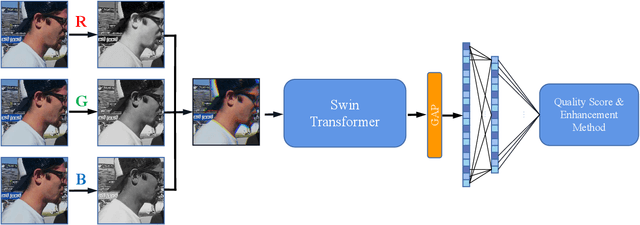
This paper reports on the NTIRE 2023 Quality Assessment of Video Enhancement Challenge, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2023. This challenge is to address a major challenge in the field of video processing, namely, video quality assessment (VQA) for enhanced videos. The challenge uses the VQA Dataset for Perceptual Video Enhancement (VDPVE), which has a total of 1211 enhanced videos, including 600 videos with color, brightness, and contrast enhancements, 310 videos with deblurring, and 301 deshaked videos. The challenge has a total of 167 registered participants. 61 participating teams submitted their prediction results during the development phase, with a total of 3168 submissions. A total of 176 submissions were submitted by 37 participating teams during the final testing phase. Finally, 19 participating teams submitted their models and fact sheets, and detailed the methods they used. Some methods have achieved better results than baseline methods, and the winning methods have demonstrated superior prediction performance.
Unimodal Training-Multimodal Prediction: Cross-modal Federated Learning with Hierarchical Aggregation
Mar 27, 2023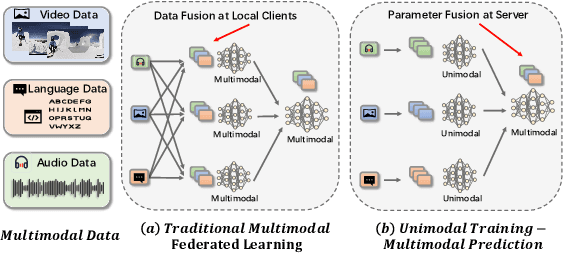
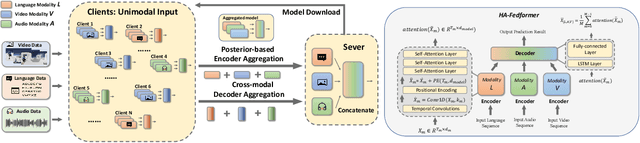


Multimodal learning has seen great success mining data features from multiple modalities with remarkable model performance improvement. Meanwhile, federated learning (FL) addresses the data sharing problem, enabling privacy-preserved collaborative training to provide sufficient precious data. Great potential, therefore, arises with the confluence of them, known as multimodal federated learning. However, limitation lies in the predominant approaches as they often assume that each local dataset records samples from all modalities. In this paper, we aim to bridge this gap by proposing an Unimodal Training - Multimodal Prediction (UTMP) framework under the context of multimodal federated learning. We design HA-Fedformer, a novel transformer-based model that empowers unimodal training with only a unimodal dataset at the client and multimodal testing by aggregating multiple clients' knowledge for better accuracy. The key advantages are twofold. Firstly, to alleviate the impact of data non-IID, we develop an uncertainty-aware aggregation method for the local encoders with layer-wise Markov Chain Monte Carlo sampling. Secondly, to overcome the challenge of unaligned language sequence, we implement a cross-modal decoder aggregation to capture the hidden signal correlation between decoders trained by data from different modalities. Our experiments on popular sentiment analysis benchmarks, CMU-MOSI and CMU-MOSEI, demonstrate that HA-Fedformer significantly outperforms state-of-the-art multimodal models under the UTMP federated learning frameworks, with 15%-20% improvement on most attributes.
BEV-SAN: Accurate BEV 3D Object Detection via Slice Attention Networks
Dec 02, 2022



Bird's-Eye-View (BEV) 3D Object Detection is a crucial multi-view technique for autonomous driving systems. Recently, plenty of works are proposed, following a similar paradigm consisting of three essential components, i.e., camera feature extraction, BEV feature construction, and task heads. Among the three components, BEV feature construction is BEV-specific compared with 2D tasks. Existing methods aggregate the multi-view camera features to the flattened grid in order to construct the BEV feature. However, flattening the BEV space along the height dimension fails to emphasize the informative features of different heights. For example, the barrier is located at a low height while the truck is located at a high height. In this paper, we propose a novel method named BEV Slice Attention Network (BEV-SAN) for exploiting the intrinsic characteristics of different heights. Instead of flattening the BEV space, we first sample along the height dimension to build the global and local BEV slices. Then, the features of BEV slices are aggregated from the camera features and merged by the attention mechanism. Finally, we fuse the merged local and global BEV features by a transformer to generate the final feature map for task heads. The purpose of local BEV slices is to emphasize informative heights. In order to find them, we further propose a LiDAR-guided sampling strategy to leverage the statistical distribution of LiDAR to determine the heights of local slices. Compared with uniform sampling, LiDAR-guided sampling can determine more informative heights. We conduct detailed experiments to demonstrate the effectiveness of BEV-SAN. Code will be released.
Cloud-Device Collaborative Adaptation to Continual Changing Environments in the Real-world
Dec 02, 2022



When facing changing environments in the real world, the lightweight model on client devices suffers from severe performance drops under distribution shifts. The main limitations of the existing device model lie in (1) unable to update due to the computation limit of the device, (2) the limited generalization ability of the lightweight model. Meanwhile, recent large models have shown strong generalization capability on the cloud while they can not be deployed on client devices due to poor computation constraints. To enable the device model to deal with changing environments, we propose a new learning paradigm of Cloud-Device Collaborative Continual Adaptation, which encourages collaboration between cloud and device and improves the generalization of the device model. Based on this paradigm, we further propose an Uncertainty-based Visual Prompt Adapted (U-VPA) teacher-student model to transfer the generalization capability of the large model on the cloud to the device model. Specifically, we first design the Uncertainty Guided Sampling (UGS) to screen out challenging data continuously and transmit the most out-of-distribution samples from the device to the cloud. Then we propose a Visual Prompt Learning Strategy with Uncertainty guided updating (VPLU) to specifically deal with the selected samples with more distribution shifts. We transmit the visual prompts to the device and concatenate them with the incoming data to pull the device testing distribution closer to the cloud training distribution. We conduct extensive experiments on two object detection datasets with continually changing environments. Our proposed U-VPA teacher-student framework outperforms previous state-of-the-art test time adaptation and device-cloud collaboration methods. The code and datasets will be released.
Multi-latent Space Alignments for Unsupervised Domain Adaptation in Multi-view 3D Object Detection
Nov 30, 2022



Vision-Centric Bird-Eye-View (BEV) perception has shown promising potential and attracted increasing attention in autonomous driving. Recent works mainly focus on improving efficiency or accuracy but neglect the domain shift problem, resulting in severe degradation of transfer performance. With extensive observations, we figure out the significant domain gaps existing in the scene, weather, and day-night changing scenarios and make the first attempt to solve the domain adaption problem for multi-view 3D object detection. Since BEV perception approaches are usually complicated and contain several components, the domain shift accumulation on multi-latent spaces makes BEV domain adaptation challenging. In this paper, we propose a novel Multi-level Multi-space Alignment Teacher-Student ($M^{2}ATS$) framework to ease the domain shift accumulation, which consists of a Depth-Aware Teacher (DAT) and a Multi-space Feature Aligned (MFA) student model. Specifically, DAT model adopts uncertainty guidance to sample reliable depth information in target domain. After constructing domain-invariant BEV perception, it then transfers pixel and instance-level knowledge to student model. To further alleviate the domain shift at the global level, MFA student model is introduced to align task-relevant multi-space features of two domains. To verify the effectiveness of $M^{2}ATS$, we conduct BEV 3D object detection experiments on four cross domain scenarios and achieve state-of-the-art performance (e.g., +12.6% NDS and +9.1% mAP on Day-Night). Code and dataset will be released.