 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhiwei Huang
Online,Target-Free LiDAR-Camera Extrinsic Calibration via Cross-Modal Mask Matching
Apr 28, 2024
LiDAR-camera extrinsic calibration (LCEC) is crucial for data fusion in intelligent vehicles. Offline, target-based approaches have long been the preferred choice in this field. However, they often demonstrate poor adaptability to real-world environments. This is largely because extrinsic parameters may change significantly due to moderate shocks or during extended operations in environments with vibrations. In contrast, online, target-free approaches provide greater adaptability yet typically lack robustness, primarily due to the challenges in cross-modal feature matching. Therefore, in this article, we unleash the full potential of large vision models (LVMs), which are emerging as a significant trend in the fields of computer vision and robotics, especially for embodied artificial intelligence, to achieve robust and accurate online, target-free LCEC across a variety of challenging scenarios. Our main contributions are threefold: we introduce a novel framework known as MIAS-LCEC, provide an open-source versatile calibration toolbox with an interactive visualization interface, and publish three real-world datasets captured from various indoor and outdoor environments. The cornerstone of our framework and toolbox is the cross-modal mask matching (C3M) algorithm, developed based on a state-of-the-art (SoTA) LVM and capable of generating sufficient and reliable matches. Extensive experiments conducted on these real-world datasets demonstrate the robustness of our approach and its superior performance compared to SoTA methods, particularly for the solid-state LiDARs with super-wide fields of view.
Weaver: Foundation Models for Creative Writing
Jan 30, 2024This work introduces Weaver, our first family of large language models (LLMs) dedicated to content creation. Weaver is pre-trained on a carefully selected corpus that focuses on improving the writing capabilities of large language models. We then fine-tune Weaver for creative and professional writing purposes and align it to the preference of professional writers using a suit of novel methods for instruction data synthesis and LLM alignment, making it able to produce more human-like texts and follow more diverse instructions for content creation. The Weaver family consists of models of Weaver Mini (1.8B), Weaver Base (6B), Weaver Pro (14B), and Weaver Ultra (34B) sizes, suitable for different applications and can be dynamically dispatched by a routing agent according to query complexity to balance response quality and computation cost. Evaluation on a carefully curated benchmark for assessing the writing capabilities of LLMs shows Weaver models of all sizes outperform generalist LLMs several times larger than them. Notably, our most-capable Weaver Ultra model surpasses GPT-4, a state-of-the-art generalist LLM, on various writing scenarios, demonstrating the advantage of training specialized LLMs for writing purposes. Moreover, Weaver natively supports retrieval-augmented generation (RAG) and function calling (tool usage). We present various use cases of these abilities for improving AI-assisted writing systems, including integration of external knowledge bases, tools, or APIs, and providing personalized writing assistance. Furthermore, we discuss and summarize a guideline and best practices for pre-training and fine-tuning domain-specific LLMs.
Reliable Academic Conference Question Answering: A Study Based on Large Language Model
Oct 19, 2023The rapid growth of computer science has led to a proliferation of research presented at academic conferences, fostering global scholarly communication. Researchers consistently seek accurate, current information about these events at all stages. This data surge necessitates an intelligent question-answering system to efficiently address researchers' queries and ensure awareness of the latest advancements. The information of conferences is usually published on their official website, organized in a semi-structured way with a lot of text. To address this need, we have developed the ConferenceQA dataset for 7 diverse academic conferences with human annotations. Firstly, we employ a combination of manual and automated methods to organize academic conference data in a semi-structured JSON format. Subsequently, we annotate nearly 100 question-answer pairs for each conference. Each pair is classified into four different dimensions. To ensure the reliability of the data, we manually annotate the source of each answer. In light of recent advancements, Large Language Models (LLMs) have demonstrated impressive performance in various NLP tasks. They have demonstrated impressive capabilities in information-seeking question answering after instruction fine-tuning, and as such, we present our conference QA study based on LLM. Due to hallucination and outdated knowledge of LLMs, we adopt retrieval based methods to enhance LLMs' question-answering abilities. We have proposed a structure-aware retrieval method, specifically designed to leverage inherent structural information during the retrieval process. Empirical validation on the ConferenceQA dataset has demonstrated the effectiveness of this method. The dataset and code are readily accessible on https://github.com/zjukg/ConferenceQA.
NTIRE 2023 Quality Assessment of Video Enhancement Challenge
Jul 19, 2023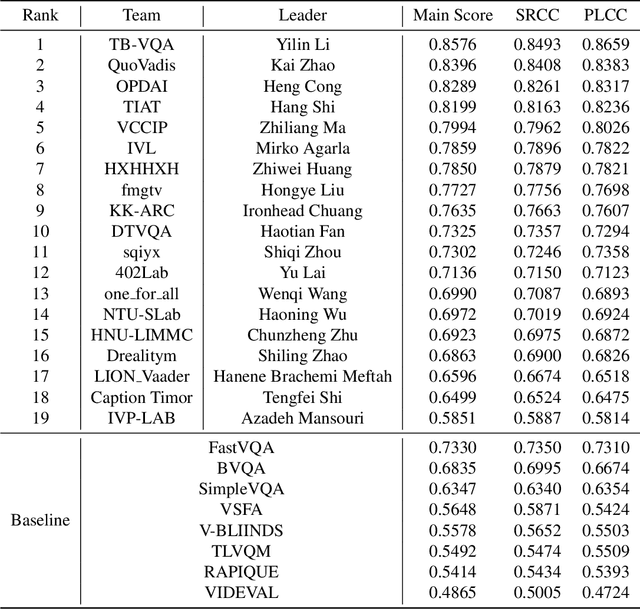
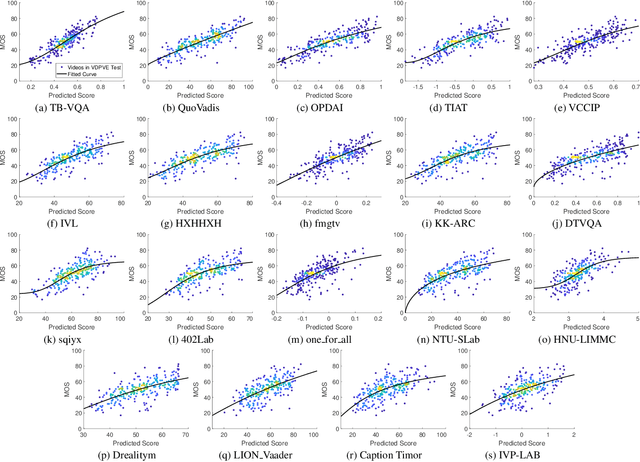
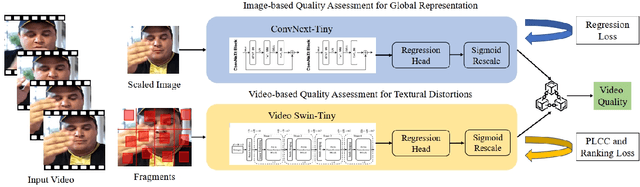
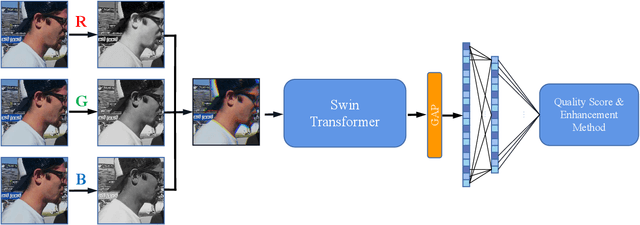
This paper reports on the NTIRE 2023 Quality Assessment of Video Enhancement Challenge, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2023. This challenge is to address a major challenge in the field of video processing, namely, video quality assessment (VQA) for enhanced videos. The challenge uses the VQA Dataset for Perceptual Video Enhancement (VDPVE), which has a total of 1211 enhanced videos, including 600 videos with color, brightness, and contrast enhancements, 310 videos with deblurring, and 301 deshaked videos. The challenge has a total of 167 registered participants. 61 participating teams submitted their prediction results during the development phase, with a total of 3168 submissions. A total of 176 submissions were submitted by 37 participating teams during the final testing phase. Finally, 19 participating teams submitted their models and fact sheets, and detailed the methods they used. Some methods have achieved better results than baseline methods, and the winning methods have demonstrated superior prediction performance.
NeuralKG-ind: A Python Library for Inductive Knowledge Graph Representation Learning
Apr 28, 2023

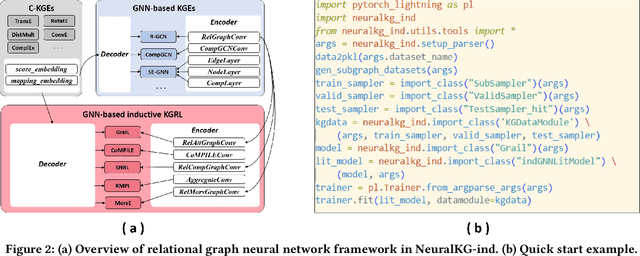

Since the dynamic characteristics of knowledge graphs, many inductive knowledge graph representation learning (KGRL) works have been proposed in recent years, focusing on enabling prediction over new entities. NeuralKG-ind is the first library of inductive KGRL as an important update of NeuralKG library. It includes standardized processes, rich existing methods, decoupled modules, and comprehensive evaluation metrics. With NeuralKG-ind, it is easy for researchers and engineers to reproduce, redevelop, and compare inductive KGRL methods. The library, experimental methodologies, and model re-implementing results of NeuralKG-ind are all publicly released at https://github.com/zjukg/NeuralKG/tree/ind .