 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYi Xiao
Weaver: Foundation Models for Creative Writing
Jan 30, 2024
This work introduces Weaver, our first family of large language models (LLMs) dedicated to content creation. Weaver is pre-trained on a carefully selected corpus that focuses on improving the writing capabilities of large language models. We then fine-tune Weaver for creative and professional writing purposes and align it to the preference of professional writers using a suit of novel methods for instruction data synthesis and LLM alignment, making it able to produce more human-like texts and follow more diverse instructions for content creation. The Weaver family consists of models of Weaver Mini (1.8B), Weaver Base (6B), Weaver Pro (14B), and Weaver Ultra (34B) sizes, suitable for different applications and can be dynamically dispatched by a routing agent according to query complexity to balance response quality and computation cost. Evaluation on a carefully curated benchmark for assessing the writing capabilities of LLMs shows Weaver models of all sizes outperform generalist LLMs several times larger than them. Notably, our most-capable Weaver Ultra model surpasses GPT-4, a state-of-the-art generalist LLM, on various writing scenarios, demonstrating the advantage of training specialized LLMs for writing purposes. Moreover, Weaver natively supports retrieval-augmented generation (RAG) and function calling (tool usage). We present various use cases of these abilities for improving AI-assisted writing systems, including integration of external knowledge bases, tools, or APIs, and providing personalized writing assistance. Furthermore, we discuss and summarize a guideline and best practices for pre-training and fine-tuning domain-specific LLMs.
Deep Blind Super-Resolution for Satellite Video
Jan 13, 2024Recent efforts have witnessed remarkable progress in Satellite Video Super-Resolution (SVSR). However, most SVSR methods usually assume the degradation is fixed and known, e.g., bicubic downsampling, which makes them vulnerable in real-world scenes with multiple and unknown degradations. To alleviate this issue, blind SR has thus become a research hotspot. Nevertheless, existing approaches are mainly engaged in blur kernel estimation while losing sight of another critical aspect for VSR tasks: temporal compensation, especially compensating for blurry and smooth pixels with vital sharpness from severely degraded satellite videos. Therefore, this paper proposes a practical Blind SVSR algorithm (BSVSR) to explore more sharp cues by considering the pixel-wise blur levels in a coarse-to-fine manner. Specifically, we employed multi-scale deformable convolution to coarsely aggregate the temporal redundancy into adjacent frames by window-slid progressive fusion. Then the adjacent features are finely merged into mid-feature using deformable attention, which measures the blur levels of pixels and assigns more weights to the informative pixels, thus inspiring the representation of sharpness. Moreover, we devise a pyramid spatial transformation module to adjust the solution space of sharp mid-feature, resulting in flexible feature adaptation in multi-level domains. Quantitative and qualitative evaluations on both simulated and real-world satellite videos demonstrate that our BSVSR performs favorably against state-of-the-art non-blind and blind SR models. Code will be available at https://github.com/XY-boy/Blind-Satellite-VSR
* Published in IEEE TGRS
FengWu-4DVar: Coupling the Data-driven Weather Forecasting Model with 4D Variational Assimilation
Dec 16, 2023Weather forecasting is a crucial yet highly challenging task. With the maturity of Artificial Intelligence (AI), the emergence of data-driven weather forecasting models has opened up a new paradigm for the development of weather forecasting systems. Despite the significant successes that have been achieved (e.g., surpassing advanced traditional physical models for global medium-range forecasting), existing data-driven weather forecasting models still rely on the analysis fields generated by the traditional assimilation and forecasting system, which hampers the significance of data-driven weather forecasting models regarding both computational cost and forecasting accuracy. In this work, we explore the possibility of coupling the data-driven weather forecasting model with data assimilation by integrating the global AI weather forecasting model, FengWu, with one of the most popular assimilation algorithms, Four-Dimensional Variational (4DVar) assimilation, and develop an AI-based cyclic weather forecasting system, FengWu-4DVar. FengWu-4DVar can incorporate observational data into the data-driven weather forecasting model and consider the temporal evolution of atmospheric dynamics to obtain accurate analysis fields for making predictions in a cycling manner without the help of physical models. Owning to the auto-differentiation ability of deep learning models, FengWu-4DVar eliminates the need of developing the cumbersome adjoint model, which is usually required in the traditional implementation of the 4DVar algorithm. Experiments on the simulated observational dataset demonstrate that FengWu-4DVar is capable of generating reasonable analysis fields for making accurate and efficient iterative predictions.
EDiffSR: An Efficient Diffusion Probabilistic Model for Remote Sensing Image Super-Resolution
Oct 30, 2023Recently, convolutional networks have achieved remarkable development in remote sensing image Super-Resoltuion (SR) by minimizing the regression objectives, e.g., MSE loss. However, despite achieving impressive performance, these methods often suffer from poor visual quality with over-smooth issues. Generative adversarial networks have the potential to infer intricate details, but they are easy to collapse, resulting in undesirable artifacts. To mitigate these issues, in this paper, we first introduce Diffusion Probabilistic Model (DPM) for efficient remote sensing image SR, dubbed EDiffSR. EDiffSR is easy to train and maintains the merits of DPM in generating perceptual-pleasant images. Specifically, different from previous works using heavy UNet for noise prediction, we develop an Efficient Activation Network (EANet) to achieve favorable noise prediction performance by simplified channel attention and simple gate operation, which dramatically reduces the computational budget. Moreover, to introduce more valuable prior knowledge into the proposed EDiffSR, a practical Conditional Prior Enhancement Module (CPEM) is developed to help extract an enriched condition. Unlike most DPM-based SR models that directly generate conditions by amplifying LR images, the proposed CPEM helps to retain more informative cues for accurate SR. Extensive experiments on four remote sensing datasets demonstrate that EDiffSR can restore visual-pleasant images on simulated and real-world remote sensing images, both quantitatively and qualitatively. The code of EDiffSR will be available at https://github.com/XY-boy/EDiffSR
"Reading Between the Heat": Co-Teaching Body Thermal Signatures for Non-intrusive Stress Detection
Oct 15, 2023Stress impacts our physical and mental health as well as our social life. A passive and contactless indoor stress monitoring system can unlock numerous important applications such as workplace productivity assessment, smart homes, and personalized mental health monitoring. While the thermal signatures from a user's body captured by a thermal camera can provide important information about the "fight-flight" response of the sympathetic and parasympathetic nervous system, relying solely on thermal imaging for training a stress prediction model often lead to overfitting and consequently a suboptimal performance. This paper addresses this challenge by introducing ThermaStrain, a novel co-teaching framework that achieves high-stress prediction performance by transferring knowledge from the wearable modality to the contactless thermal modality. During training, ThermaStrain incorporates a wearable electrodermal activity (EDA) sensor to generate stress-indicative representations from thermal videos, emulating stress-indicative representations from a wearable EDA sensor. During testing, only thermal sensing is used, and stress-indicative patterns from thermal data and emulated EDA representations are extracted to improve stress assessment. The study collected a comprehensive dataset with thermal video and EDA data under various stress conditions and distances. ThermaStrain achieves an F1 score of 0.8293 in binary stress classification, outperforming the thermal-only baseline approach by over 9%. Extensive evaluations highlight ThermaStrain's effectiveness in recognizing stress-indicative attributes, its adaptability across distances and stress scenarios, real-time executability on edge platforms, its applicability to multi-individual sensing, ability to function on limited visibility and unfamiliar conditions, and the advantages of its co-teaching approach.
LARA: A Light and Anti-overfitting Retraining Approach for Unsupervised Anomaly Detection
Oct 09, 2023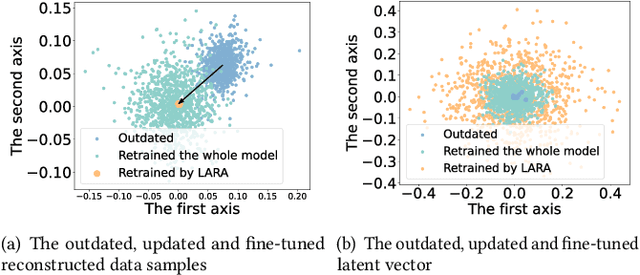

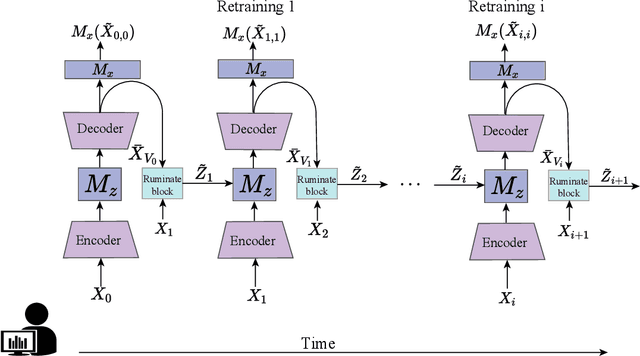
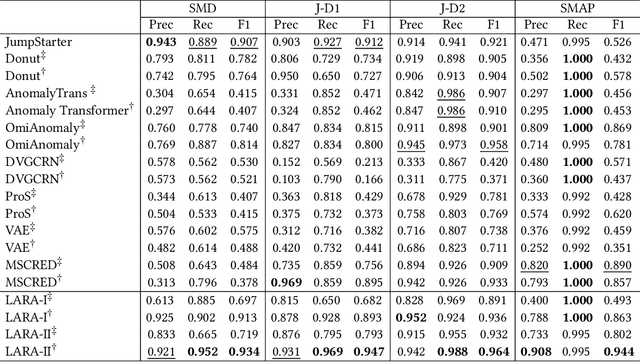
Most of current anomaly detection models assume that the normal pattern remains same all the time. However, the normal patterns of Web services change dramatically and frequently. The model trained on old-distribution data is outdated after such changes. Retraining the whole model every time is expensive. Besides, at the beginning of normal pattern changes, there is not enough observation data from the new distribution. Retraining a large neural network model with limited data is vulnerable to overfitting. Thus, we propose a Light and Anti-overfitting Retraining Approach (LARA) for deep variational auto-encoder based time series anomaly detection methods (VAEs). This work aims to make three novel contributions: 1) the retraining process is formulated as a convex problem and can converge at a fast rate as well as prevent overfitting; 2) designing a ruminate block, which leverages the historical data without the need to store them; 3) mathematically proving that when fine-tuning the latent vector and reconstructed data, the linear formations can achieve the least adjusting errors between the ground truths and the fine-tuned ones. Moreover, we have performed many experiments to verify that retraining LARA with even 43 time slots of data from new distribution can result in its competitive F1 Score in comparison with the state-of-the-art anomaly detection models trained with sufficient data. Besides, we verify its light overhead.
Classifying Rhoticity of /r/ in Speech Sound Disorder using Age-and-Sex Normalized Formants
May 25, 2023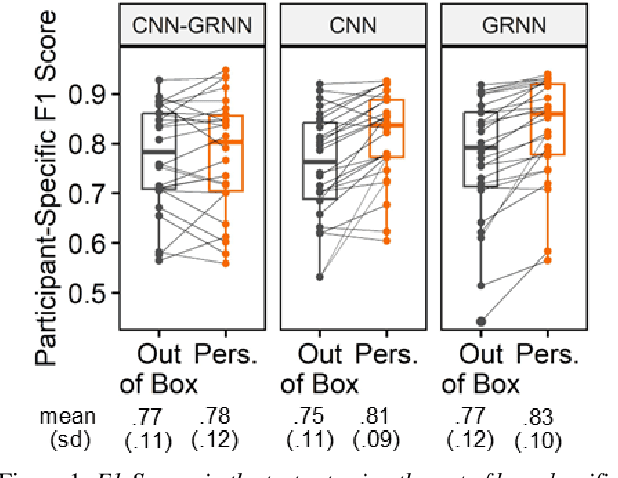

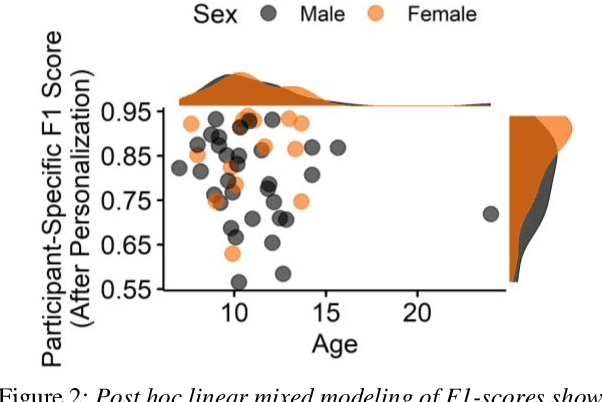
Mispronunciation detection tools could increase treatment access for speech sound disorders impacting, e.g., /r/. We show age-and-sex normalized formant estimation outperforms cepstral representation for detection of fully rhotic vs. derhotic /r/ in the PERCEPT-R Corpus. Gated recurrent neural networks trained on this feature set achieve a mean test participant-specific F1-score =.81 ({\sigma}x=.10, med = .83, n = 48), with post hoc modeling showing no significant effect of child age or sex.
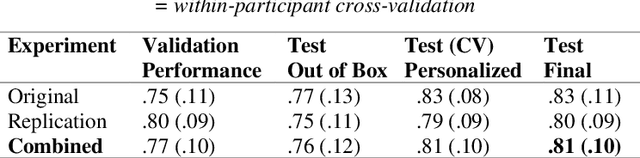
Inferring High-level Geographical Concepts via Knowledge Graph and Multi-scale Data Integration: A Case Study of C-shaped Building Pattern Recognition
Apr 19, 2023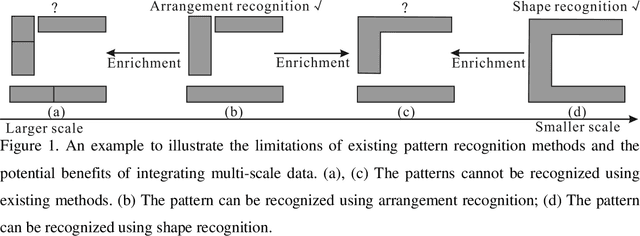
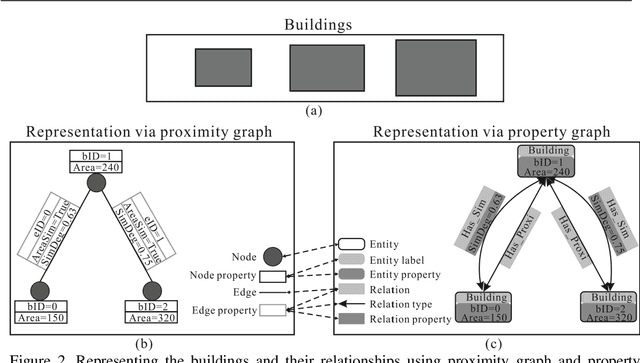

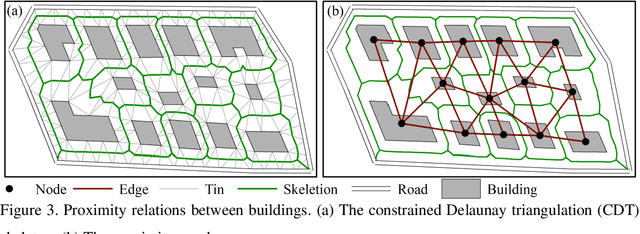
Effective building pattern recognition is critical for understanding urban form, automating map generalization, and visualizing 3D city models. Most existing studies use object-independent methods based on visual perception rules and proximity graph models to extract patterns. However, because human vision is a part-based system, pattern recognition may require decomposing shapes into parts or grouping them into clusters. Existing methods may not recognize all visually aware patterns, and the proximity graph model can be inefficient. To improve efficiency and effectiveness, we integrate multi-scale data using a knowledge graph, focusing on the recognition of C-shaped building patterns. First, we use a property graph to represent the relationships between buildings within and across different scales involved in C-shaped building pattern recognition. Next, we store this knowledge graph in a graph database and convert the rules for C-shaped pattern recognition and enrichment into query conditions. Finally, we recognize and enrich C-shaped building patterns using rule-based reasoning in the built knowledge graph. We verify the effectiveness of our method using multi-scale data with three levels of detail (LODs) collected from the Gaode Map. Our results show that our method achieves a higher recall rate of 26.4% for LOD1, 20.0% for LOD2, and 9.1% for LOD3 compared to existing approaches. We also achieve recognition efficiency improvements of 0.91, 1.37, and 9.35 times, respectively.
Local-Global Temporal Difference Learning for Satellite Video Super-Resolution
Apr 10, 2023
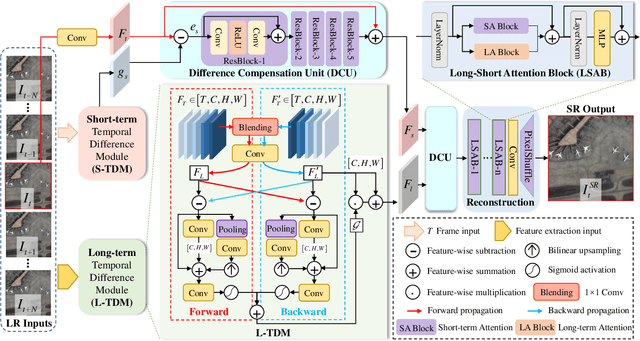
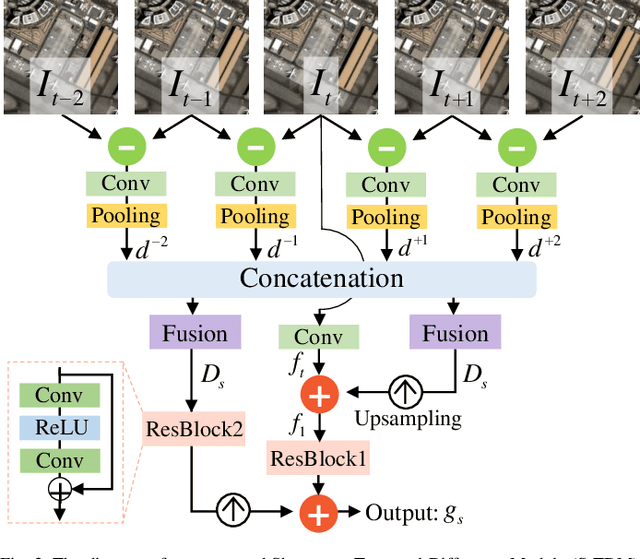

Optical-flow-based and kernel-based approaches have been widely explored for temporal compensation in satellite video super-resolution (VSR). However, these techniques involve high computational consumption and are prone to fail under complex motions. In this paper, we proposed to exploit the well-defined temporal difference for efficient and robust temporal compensation. To fully utilize the temporal information within frames, we separately modeled the short-term and long-term temporal discrepancy since they provide distinctive complementary properties. Specifically, a short-term temporal difference module is designed to extract local motion representations from residual maps between adjacent frames, which provides more clues for accurate texture representation. Meanwhile, the global dependency in the entire frame sequence is explored via long-term difference learning. The differences between forward and backward segments are incorporated and activated to modulate the temporal feature, resulting in holistic global compensation. Besides, we further proposed a difference compensation unit to enrich the interaction between the spatial distribution of the target frame and compensated results, which helps maintain spatial consistency while refining the features to avoid misalignment. Extensive objective and subjective evaluation of five mainstream satellite videos demonstrates that the proposed method performs favorably for satellite VSR. Code will be available at \url{https://github.com/XY-boy/TDMVSR}
Scaling Self-Supervised End-to-End Driving with Multi-View Attention Learning
Feb 09, 2023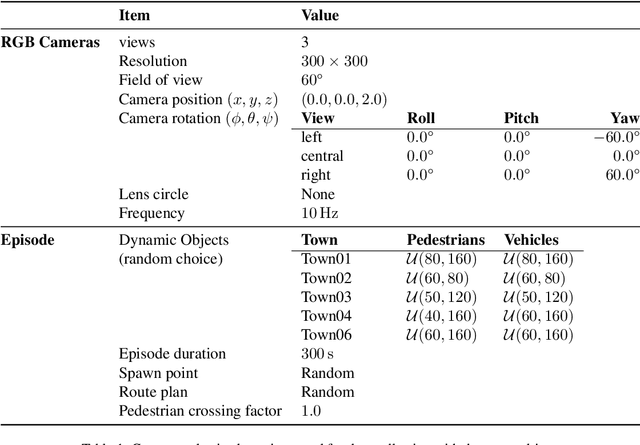
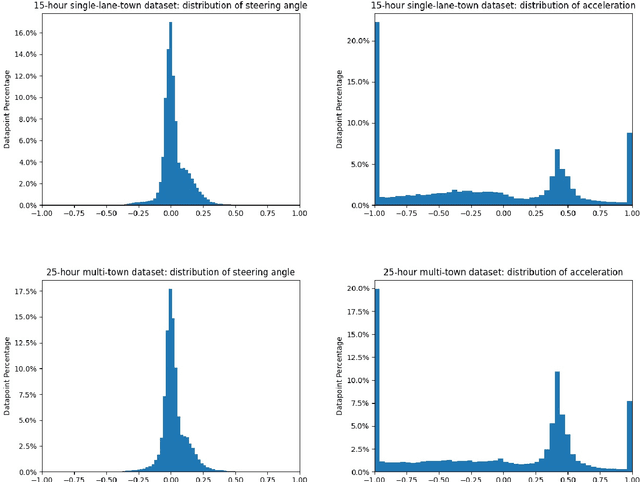
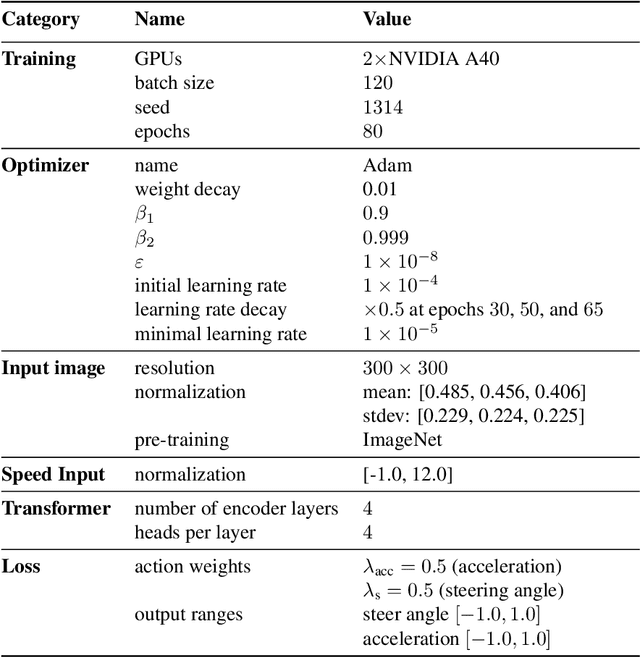

On end-to-end driving, a large amount of expert driving demonstrations is used to train an agent that mimics the expert by predicting its control actions. This process is self-supervised on vehicle signals (e.g., steering angle, acceleration) and does not require extra costly supervision (human labeling). Yet, the improvement of existing self-supervised end-to-end driving models has mostly given room to modular end-to-end models where labeling data intensive format such as semantic segmentation are required during training time. However, we argue that the latest self-supervised end-to-end models were developed in sub-optimal conditions with low-resolution images and no attention mechanisms. Further, those models are confined with limited field of view and far from the human visual cognition which can quickly attend far-apart scene features, a trait that provides an useful inductive bias. In this context, we present a new end-to-end model, trained by self-supervised imitation learning, leveraging a large field of view and a self-attention mechanism. These settings are more contributing to the agent's understanding of the driving scene, which brings a better imitation of human drivers. With only self-supervised training data, our model yields almost expert performance in CARLA's Nocrash metrics and could be rival to the SOTA models requiring large amounts of human labeled data. To facilitate further research, our code will be released.