 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong Li
How Do Humans Write Code? Large Models Do It the Same Way Too
Feb 24, 2024
Large Language Models (LLMs) often make errors when performing numerical calculations. In contrast to traditional chain-of-thought reasoning, the program-of-thoughts approach involves generating executable code to solve problems. By executing this code, it achieves more precise results. Using generated executable code instead of natural language can reduce computational errors. However, we observe that when LLMs solve mathematical problems using code, they tend to generate more incorrect reasoning than when using natural language. To address this issue, we propose Human-Think Language (HTL), a straightforward yet highly efficient approach inspired by human coding practices. The approach first generates problem-solving methods described in the natural language by the model, then converts them into code, mirroring the process where people think through the logic in natural language before writing it as code. Additionally, it utilizes the Proximal Policy Optimization (PPO) algorithm, enabling it to provide feedback to itself based on the correctness of mathematical answers, much like humans do. Finally, we introduce a focus-attention mechanism that masks the question segment, enhancing its reliance on natural language inference solutions during code generation. We conduct our experiments without introducing any additional information, and the results across five mathematical calculation datasets showcase the effectiveness of our approach. Notably, on the NumGLUE dataset, the LlaMA-2-7B-based model achieves a superior performance rate (75.1%) compared to the previous best performance with the LlaMA-2-70B model (74.4%).
Weaver: Foundation Models for Creative Writing
Jan 30, 2024This work introduces Weaver, our first family of large language models (LLMs) dedicated to content creation. Weaver is pre-trained on a carefully selected corpus that focuses on improving the writing capabilities of large language models. We then fine-tune Weaver for creative and professional writing purposes and align it to the preference of professional writers using a suit of novel methods for instruction data synthesis and LLM alignment, making it able to produce more human-like texts and follow more diverse instructions for content creation. The Weaver family consists of models of Weaver Mini (1.8B), Weaver Base (6B), Weaver Pro (14B), and Weaver Ultra (34B) sizes, suitable for different applications and can be dynamically dispatched by a routing agent according to query complexity to balance response quality and computation cost. Evaluation on a carefully curated benchmark for assessing the writing capabilities of LLMs shows Weaver models of all sizes outperform generalist LLMs several times larger than them. Notably, our most-capable Weaver Ultra model surpasses GPT-4, a state-of-the-art generalist LLM, on various writing scenarios, demonstrating the advantage of training specialized LLMs for writing purposes. Moreover, Weaver natively supports retrieval-augmented generation (RAG) and function calling (tool usage). We present various use cases of these abilities for improving AI-assisted writing systems, including integration of external knowledge bases, tools, or APIs, and providing personalized writing assistance. Furthermore, we discuss and summarize a guideline and best practices for pre-training and fine-tuning domain-specific LLMs.
Agents: An Open-source Framework for Autonomous Language Agents
Sep 14, 2023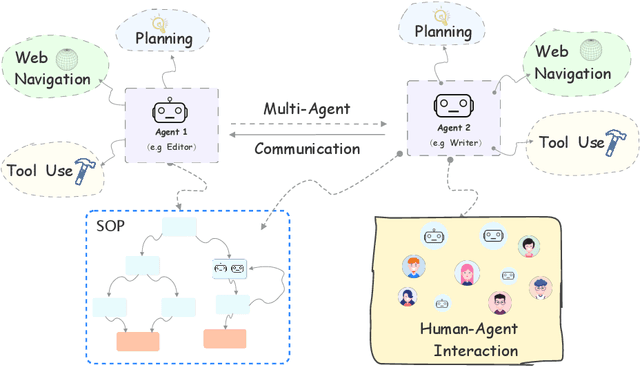

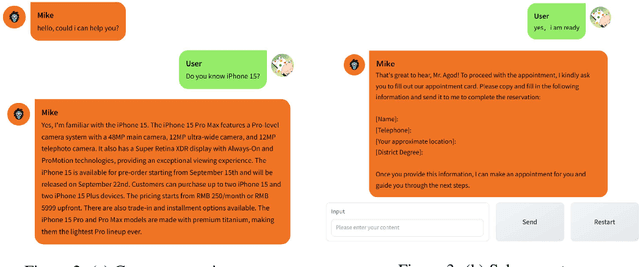
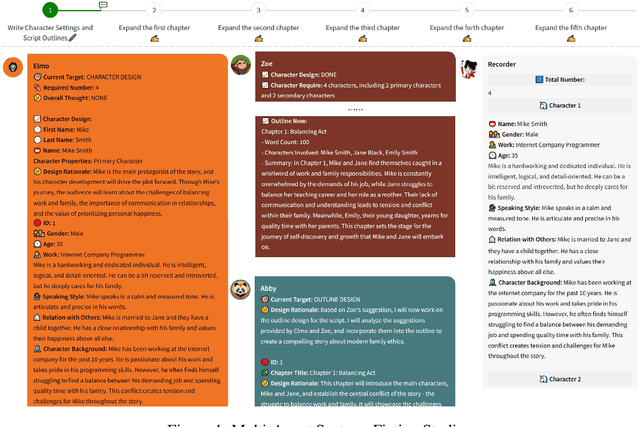
Recent advances on large language models (LLMs) enable researchers and developers to build autonomous language agents that can automatically solve various tasks and interact with environments, humans, and other agents using natural language interfaces. We consider language agents as a promising direction towards artificial general intelligence and release Agents, an open-source library with the goal of opening up these advances to a wider non-specialist audience. Agents is carefully engineered to support important features including planning, memory, tool usage, multi-agent communication, and fine-grained symbolic control. Agents is user-friendly as it enables non-specialists to build, customize, test, tune, and deploy state-of-the-art autonomous language agents without much coding. The library is also research-friendly as its modularized design makes it easily extensible for researchers. Agents is available at https://github.com/aiwaves-cn/agents.
Discriminative Co-Saliency and Background Mining Transformer for Co-Salient Object Detection
May 06, 2023



Most previous co-salient object detection works mainly focus on extracting co-salient cues via mining the consistency relations across images while ignoring explicit exploration of background regions. In this paper, we propose a Discriminative co-saliency and background Mining Transformer framework (DMT) based on several economical multi-grained correlation modules to explicitly mine both co-saliency and background information and effectively model their discrimination. Specifically, we first propose a region-to-region correlation module for introducing inter-image relations to pixel-wise segmentation features while maintaining computational efficiency. Then, we use two types of pre-defined tokens to mine co-saliency and background information via our proposed contrast-induced pixel-to-token correlation and co-saliency token-to-token correlation modules. We also design a token-guided feature refinement module to enhance the discriminability of the segmentation features under the guidance of the learned tokens. We perform iterative mutual promotion for the segmentation feature extraction and token construction. Experimental results on three benchmark datasets demonstrate the effectiveness of our proposed method. The source code is available at: https://github.com/dragonlee258079/DMT.
Nebula-I: A General Framework for Collaboratively Training Deep Learning Models on Low-Bandwidth Cloud Clusters
May 19, 2022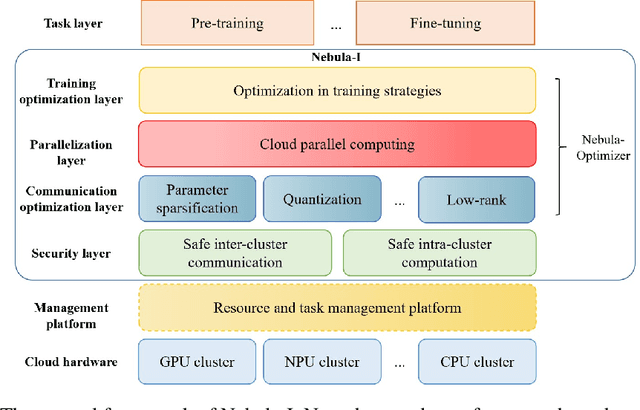
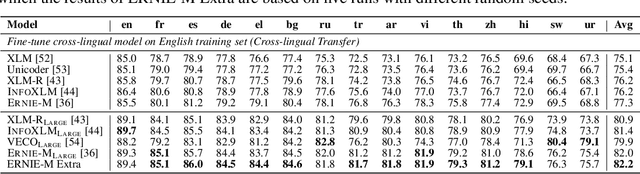
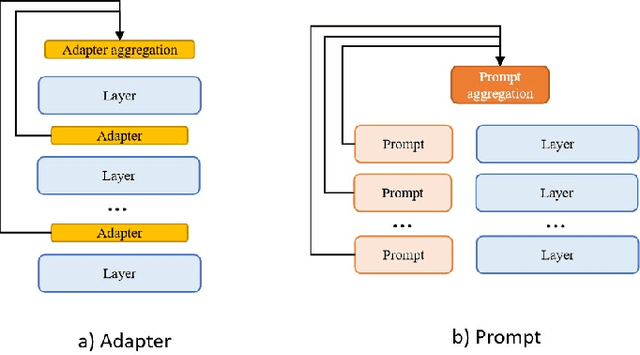
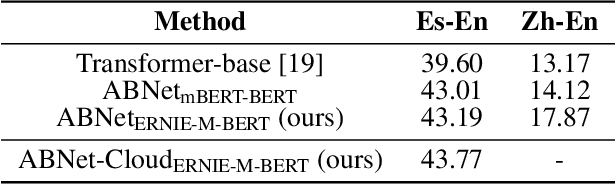
The ever-growing model size and scale of compute have attracted increasing interests in training deep learning models over multiple nodes. However, when it comes to training on cloud clusters, especially across remote clusters, huge challenges are faced. In this work, we introduce a general framework, Nebula-I, for collaboratively training deep learning models over remote heterogeneous clusters, the connections between which are low-bandwidth wide area networks (WANs). We took natural language processing (NLP) as an example to show how Nebula-I works in different training phases that include: a) pre-training a multilingual language model using two remote clusters; and b) fine-tuning a machine translation model using knowledge distilled from pre-trained models, which run through the most popular paradigm of recent deep learning. To balance the accuracy and communication efficiency, in Nebula-I, parameter-efficient training strategies, hybrid parallel computing methods and adaptive communication acceleration techniques are jointly applied. Meanwhile, security strategies are employed to guarantee the safety, reliability and privacy in intra-cluster computation and inter-cluster communication. Nebula-I is implemented with the PaddlePaddle deep learning framework, which can support collaborative training over heterogeneous hardware, e.g. GPU and NPU. Experiments demonstrate that the proposed framework could substantially maximize the training efficiency while preserving satisfactory NLP performance. By using Nebula-I, users can run large-scale training tasks over cloud clusters with minimum developments, and the utility of existed large pre-trained models could be further promoted. We also introduced new state-of-the-art results on cross-lingual natural language inference tasks, which are generated based upon a novel learning framework and Nebula-I.
Fast Electromagnetic Validations of Large-Scale Digital Coding Metasurfaces Accelerated by Recurrence Rebuild and Retrieval Method
Dec 04, 2021



The recurrence rebuild and retrieval method (R3M) is proposed in this paper to accelerate the electromagnetic (EM) validations of large-scale digital coding metasurfaces (DCMs). R3M aims to accelerate the EM validations of DCMs with varied codebooks, which involves the analysis of a group of similar but distinct coding patterns. The method transforms general DCMs to rigorously periodic arrays by replacing each coding unit with the macro unit, which comprises all possible coding states. The system matrix corresponding to the rigorously periodic array is globally shared for DCMs with arbitrary codebooks via implicit retrieval. The discrepancy of the interactions for edge and corner units are precluded by the basis extension of periodic boundaries. Moreover, the hierarchical pattern exploitation algorithm is leveraged to efficiently assemble the system matrix for further acceleration. Due to the fully utilization of the rigid periodicity, the computational complexity of R3M is theoretically lower than that of $\mathcal{H}$-matrix within the same paradigm. Numerical results for two types of DCMs indicate that R3M is accurate in comparison with commercial software. Besides, R3M is also compatible with the preconditioning for efficient iterative solutions. The efficiency of R3M for DCMs outperforms the conventional fast algorithms by a large margin in both the storage and CPU time cost.
Instance-Level Relative Saliency Ranking with Graph Reasoning
Jul 08, 2021



Conventional salient object detection models cannot differentiate the importance of different salient objects. Recently, two works have been proposed to detect saliency ranking by assigning different degrees of saliency to different objects. However, one of these models cannot differentiate object instances and the other focuses more on sequential attention shift order inference. In this paper, we investigate a practical problem setting that requires simultaneously segment salient instances and infer their relative saliency rank order. We present a novel unified model as the first end-to-end solution, where an improved Mask R-CNN is first used to segment salient instances and a saliency ranking branch is then added to infer the relative saliency. For relative saliency ranking, we build a new graph reasoning module by combining four graphs to incorporate the instance interaction relation, local contrast, global contrast, and a high-level semantic prior, respectively. A novel loss function is also proposed to effectively train the saliency ranking branch. Besides, a new dataset and an evaluation metric are proposed for this task, aiming at pushing forward this field of research. Finally, experimental results demonstrate that our proposed model is more effective than previous methods. We also show an example of its practical usage on adaptive image retargeting.
Weakly Supervised Video Salient Object Detection
Apr 06, 2021



Significant performance improvement has been achieved for fully-supervised video salient object detection with the pixel-wise labeled training datasets, which are time-consuming and expensive to obtain. To relieve the burden of data annotation, we present the first weakly supervised video salient object detection model based on relabeled "fixation guided scribble annotations". Specifically, an "Appearance-motion fusion module" and bidirectional ConvLSTM based framework are proposed to achieve effective multi-modal learning and long-term temporal context modeling based on our new weak annotations. Further, we design a novel foreground-background similarity loss to further explore the labeling similarity across frames. A weak annotation boosting strategy is also introduced to boost our model performance with a new pseudo-label generation technique. Extensive experimental results on six benchmark video saliency detection datasets illustrate the effectiveness of our solution.