 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhihua Wu
ChuXin: 1.6B Technical Report
May 08, 2024
In this report, we present ChuXin, an entirely open-source language model with a size of 1.6 billion parameters. Unlike the majority of works that only open-sourced the model weights and architecture, we have made everything needed to train a model available, including the training data, the training process, and the evaluation code. Our goal is to empower and strengthen the open research community, fostering transparency and enabling a new wave of innovation in the field of language modeling. Furthermore, we extend the context length to 1M tokens through lightweight continual pretraining and demonstrate strong needle-in-a-haystack retrieval performance. The weights for both models are available at Hugging Face to download and use.
Efficient LLM Inference with Kcache
Apr 28, 2024Large Language Models(LLMs) have had a profound impact on AI applications, particularly in the domains of long-text comprehension and generation. KV Cache technology is one of the most widely used techniques in the industry. It ensures efficient sequence generation by caching previously computed KV states. However, it also introduces significant memory overhead. We discovered that KV Cache is not necessary and proposed a novel KCache technique to alleviate the memory bottleneck issue during the LLMs inference process. KCache can be used directly for inference without any training process, Our evaluations show that KCache improves the throughput of popular LLMs by 40% with the baseline, while keeping accuracy.
Code Comparison Tuning for Code Large Language Models
Mar 28, 2024



We present Code Comparison Tuning (CCT), a simple and effective tuning method for code large language models (Code LLMs) to better handle subtle code errors. Specifically, we integrate the concept of comparison into instruction tuning, both at the token and sequence levels, enabling the model to discern even the slightest deviations in code. To compare the original code with an erroneous version containing manually added code errors, we use token-level preference loss for detailed token-level comparisons. Additionally, we combine code segments to create a new instruction tuning sample for sequence-level comparisons, enhancing the model's bug-fixing capability. Experimental results on the HumanEvalFix benchmark show that CCT surpasses instruction tuning in pass@1 scores by up to 4 points across diverse code LLMs, and extensive analysis demonstrates the effectiveness of our method.
RecycleGPT: An Autoregressive Language Model with Recyclable Module
Aug 08, 2023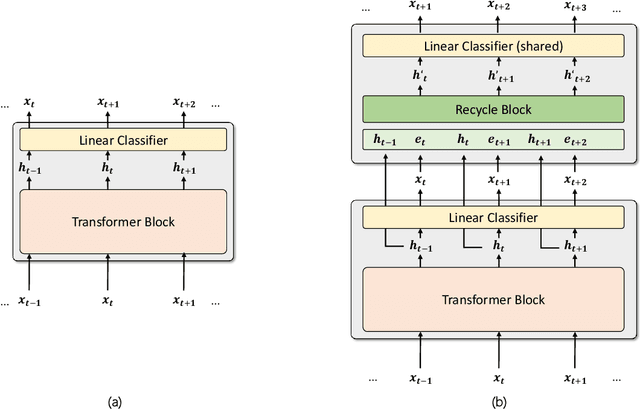
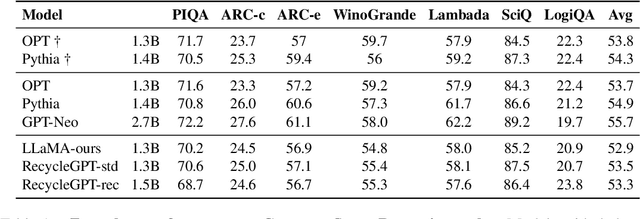
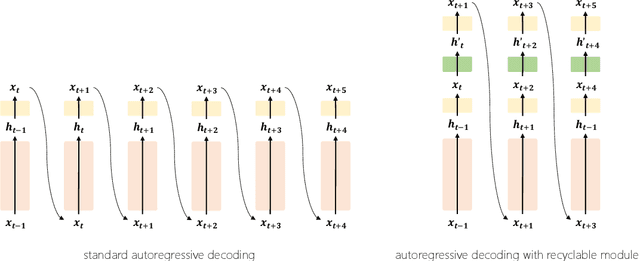
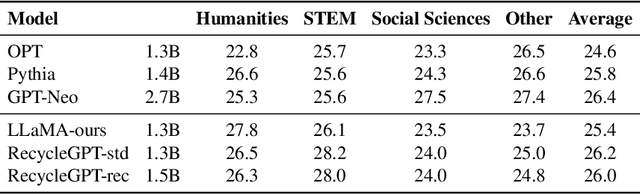
Existing large language models have to run K times to generate a sequence of K tokens. In this paper, we present RecycleGPT, a generative language model with fast decoding speed by recycling pre-generated model states without running the whole model in multiple steps. Our approach relies on the observation that adjacent tokens in a sequence usually have strong correlations and the next token in a sequence can be reasonably guessed or inferred based on the preceding ones. Experiments and analysis demonstrate the effectiveness of our approach in lowering inference latency, achieving up to 1.4x speedup while preserving high performance.
TA-MoE: Topology-Aware Large Scale Mixture-of-Expert Training
Feb 20, 2023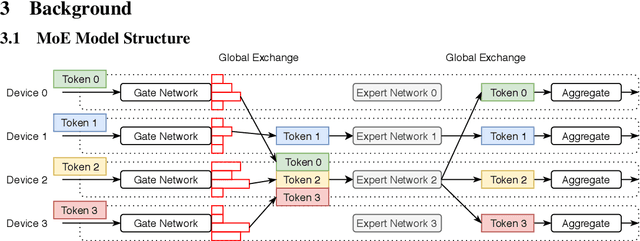
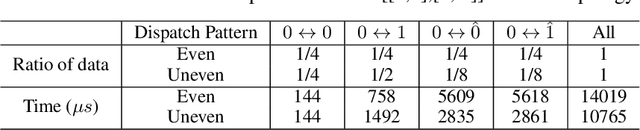
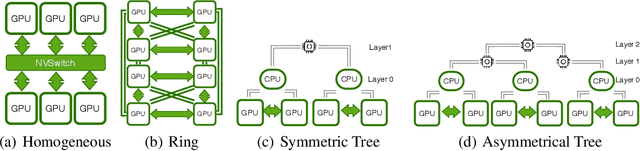

Sparsely gated Mixture-of-Expert (MoE) has demonstrated its effectiveness in scaling up deep neural networks to an extreme scale. Despite that numerous efforts have been made to improve the performance of MoE from the model design or system optimization perspective, existing MoE dispatch patterns are still not able to fully exploit the underlying heterogeneous network environments. In this paper, we propose TA-MoE, a topology-aware routing strategy for large-scale MoE trainging, from a model-system co-design perspective, which can dynamically adjust the MoE dispatch pattern according to the network topology. Based on communication modeling, we abstract the dispatch problem into an optimization objective and obtain the approximate dispatch pattern under different topologies. On top of that, we design a topology-aware auxiliary loss, which can adaptively route the data to fit in the underlying topology without sacrificing the model accuracy. Experiments show that TA-MoE can substantially outperform its counterparts on various hardware and model configurations, with roughly 1.01x-1.61x, 1.01x-4.77x, 1.25x-1.54x improvements over the popular DeepSpeed-MoE, FastMoE and FasterMoE.
HelixFold: An Efficient Implementation of AlphaFold2 using PaddlePaddle
Jul 13, 2022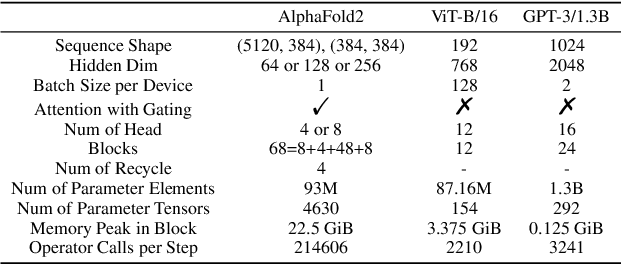
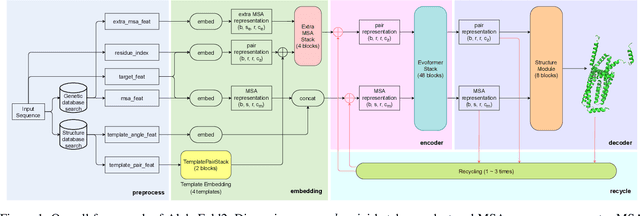

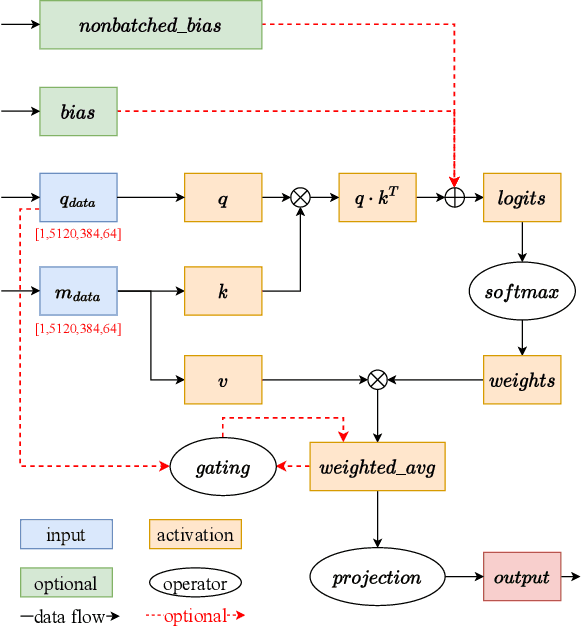
Accurate protein structure prediction can significantly accelerate the development of life science. The accuracy of AlphaFold2, a frontier end-to-end structure prediction system, is already close to that of the experimental determination techniques. Due to the complex model architecture and large memory consumption, it requires lots of computational resources and time to implement the training and inference of AlphaFold2 from scratch. The cost of running the original AlphaFold2 is expensive for most individuals and institutions. Therefore, reducing this cost could accelerate the development of life science. We implement AlphaFold2 using PaddlePaddle, namely HelixFold, to improve training and inference speed and reduce memory consumption. The performance is improved by operator fusion, tensor fusion, and hybrid parallelism computation, while the memory is optimized through Recompute, BFloat16, and memory read/write in-place. Compared with the original AlphaFold2 (implemented with Jax) and OpenFold (implemented with PyTorch), HelixFold needs only 7.5 days to complete the full end-to-end training and only 5.3 days when using hybrid parallelism, while both AlphaFold2 and OpenFold take about 11 days. HelixFold saves 1x training time. We verified that HelixFold's accuracy could be on par with AlphaFold2 on the CASP14 and CAMEO datasets. HelixFold's code is available on GitHub for free download: https://github.com/PaddlePaddle/PaddleHelix/tree/dev/apps/protein_folding/helixfold, and we also provide stable web services on https://paddlehelix.baidu.com/app/drug/protein/forecast.
SE-MoE: A Scalable and Efficient Mixture-of-Experts Distributed Training and Inference System
May 20, 2022With the increasing diversity of ML infrastructures nowadays, distributed training over heterogeneous computing systems is desired to facilitate the production of big models. Mixture-of-Experts (MoE) models have been proposed to lower the cost of training subject to the overall size of models/data through gating and parallelism in a divide-and-conquer fashion. While DeepSpeed has made efforts in carrying out large-scale MoE training over heterogeneous infrastructures, the efficiency of training and inference could be further improved from several system aspects, including load balancing, communication/computation efficiency, and memory footprint limits. In this work, we present SE-MoE that proposes Elastic MoE training with 2D prefetch and Fusion communication over Hierarchical storage, so as to enjoy efficient parallelisms in various types. For scalable inference in a single node, especially when the model size is larger than GPU memory, SE-MoE forms the CPU-GPU memory jointly into a ring of sections to load the model, and executes the computation tasks across the memory sections in a round-robin manner for efficient inference. We carried out extensive experiments to evaluate SE-MoE, where SE-MoE successfully trains a Unified Feature Optimization (UFO) model with a Sparsely-Gated Mixture-of-Experts model of 12B parameters in 8 days on 48 A100 GPU cards. The comparison against the state-of-the-art shows that SE-MoE outperformed DeepSpeed with 33% higher throughput (tokens per second) in training and 13% higher throughput in inference in general. Particularly, under unbalanced MoE Tasks, e.g., UFO, SE-MoE achieved 64% higher throughput with 18% lower memory footprints. The code of the framework will be released on: https://github.com/PaddlePaddle/Paddle.
Nebula-I: A General Framework for Collaboratively Training Deep Learning Models on Low-Bandwidth Cloud Clusters
May 19, 2022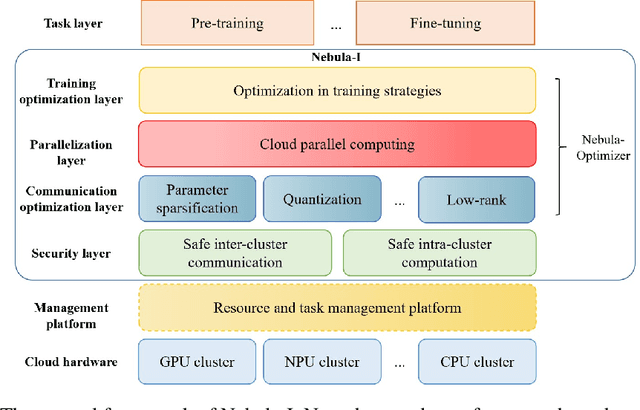
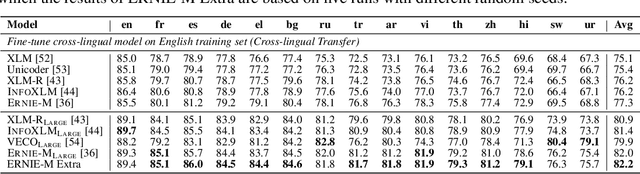
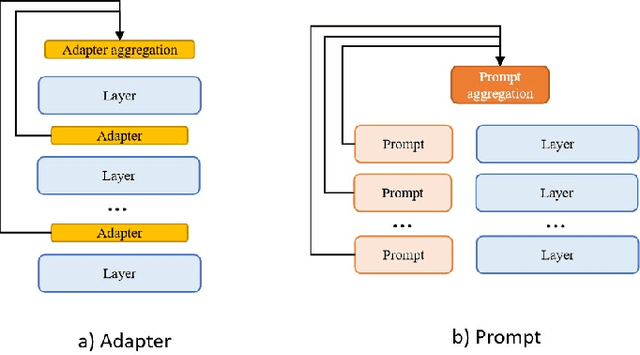
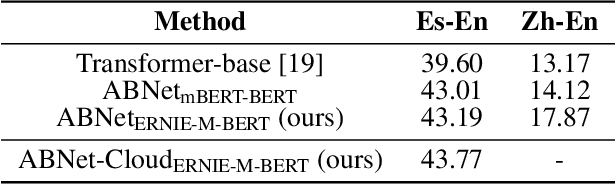
The ever-growing model size and scale of compute have attracted increasing interests in training deep learning models over multiple nodes. However, when it comes to training on cloud clusters, especially across remote clusters, huge challenges are faced. In this work, we introduce a general framework, Nebula-I, for collaboratively training deep learning models over remote heterogeneous clusters, the connections between which are low-bandwidth wide area networks (WANs). We took natural language processing (NLP) as an example to show how Nebula-I works in different training phases that include: a) pre-training a multilingual language model using two remote clusters; and b) fine-tuning a machine translation model using knowledge distilled from pre-trained models, which run through the most popular paradigm of recent deep learning. To balance the accuracy and communication efficiency, in Nebula-I, parameter-efficient training strategies, hybrid parallel computing methods and adaptive communication acceleration techniques are jointly applied. Meanwhile, security strategies are employed to guarantee the safety, reliability and privacy in intra-cluster computation and inter-cluster communication. Nebula-I is implemented with the PaddlePaddle deep learning framework, which can support collaborative training over heterogeneous hardware, e.g. GPU and NPU. Experiments demonstrate that the proposed framework could substantially maximize the training efficiency while preserving satisfactory NLP performance. By using Nebula-I, users can run large-scale training tasks over cloud clusters with minimum developments, and the utility of existed large pre-trained models could be further promoted. We also introduced new state-of-the-art results on cross-lingual natural language inference tasks, which are generated based upon a novel learning framework and Nebula-I.
ERNIE-ViLG: Unified Generative Pre-training for Bidirectional Vision-Language Generation
Dec 31, 2021



Conventional methods for the image-text generation tasks mainly tackle the naturally bidirectional generation tasks separately, focusing on designing task-specific frameworks to improve the quality and fidelity of the generated samples. Recently, Vision-Language Pre-training models have greatly improved the performance of the image-to-text generation tasks, but large-scale pre-training models for text-to-image synthesis task are still under-developed. In this paper, we propose ERNIE-ViLG, a unified generative pre-training framework for bidirectional image-text generation with transformer model. Based on the image quantization models, we formulate both image generation and text generation as autoregressive generative tasks conditioned on the text/image input. The bidirectional image-text generative modeling eases the semantic alignments across vision and language. For the text-to-image generation process, we further propose an end-to-end training method to jointly learn the visual sequence generator and the image reconstructor. To explore the landscape of large-scale pre-training for bidirectional text-image generation, we train a 10-billion parameter ERNIE-ViLG model on a large-scale dataset of 145 million (Chinese) image-text pairs which achieves state-of-the-art performance for both text-to-image and image-to-text tasks, obtaining an FID of 7.9 on MS-COCO for text-to-image synthesis and best results on COCO-CN and AIC-ICC for image captioning.
ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
Dec 23, 2021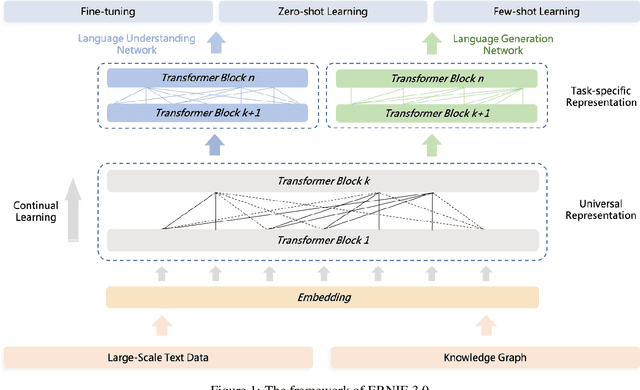
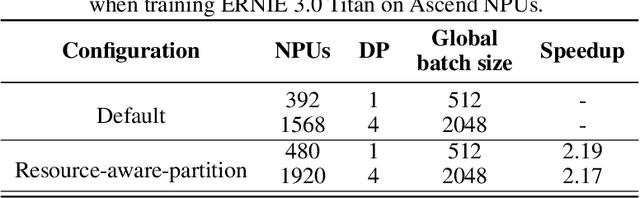
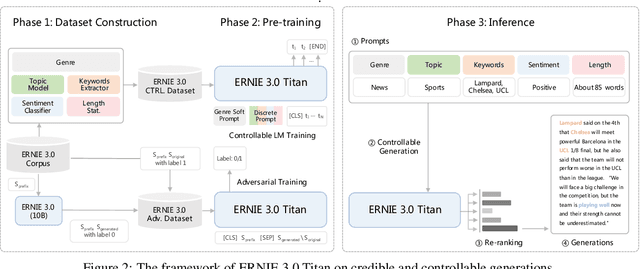
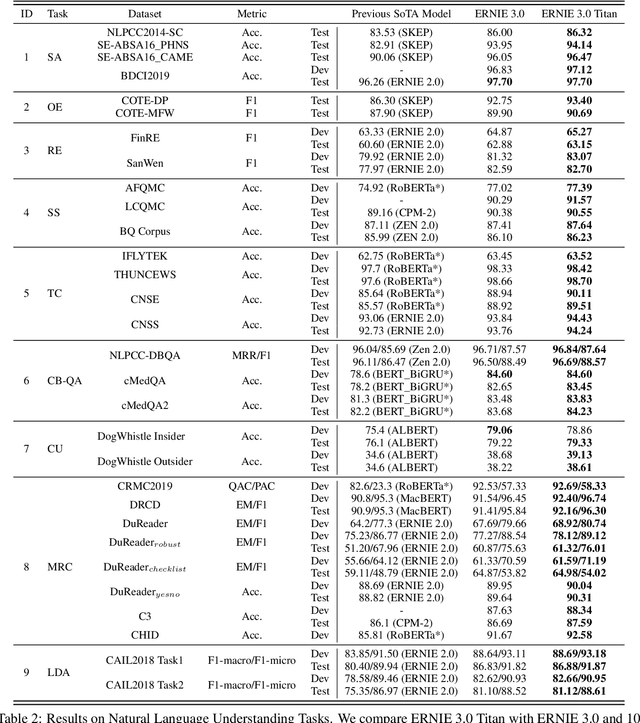
Pre-trained language models have achieved state-of-the-art results in various Natural Language Processing (NLP) tasks. GPT-3 has shown that scaling up pre-trained language models can further exploit their enormous potential. A unified framework named ERNIE 3.0 was recently proposed for pre-training large-scale knowledge enhanced models and trained a model with 10 billion parameters. ERNIE 3.0 outperformed the state-of-the-art models on various NLP tasks. In order to explore the performance of scaling up ERNIE 3.0, we train a hundred-billion-parameter model called ERNIE 3.0 Titan with up to 260 billion parameters on the PaddlePaddle platform. Furthermore, we design a self-supervised adversarial loss and a controllable language modeling loss to make ERNIE 3.0 Titan generate credible and controllable texts. To reduce the computation overhead and carbon emission, we propose an online distillation framework for ERNIE 3.0 Titan, where the teacher model will teach students and train itself simultaneously. ERNIE 3.0 Titan is the largest Chinese dense pre-trained model so far. Empirical results show that the ERNIE 3.0 Titan outperforms the state-of-the-art models on 68 NLP datasets.