 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTao Han
Revealing the structure-property relationships of copper alloys with FAGC
Apr 19, 2024
Understanding how the structure of materials affects their properties is a cornerstone of materials science and engineering. However, traditional methods have struggled to accurately describe the quantitative structure-property relationships for complex structures. In our study, we bridge this gap by leveraging machine learning to analyze images of materials' microstructures, thus offering a novel way to understand and predict the properties of materials based on their microstructures. We introduce a method known as FAGC (Feature Augmentation on Geodesic Curves), specifically demonstrated for Cu-Cr-Zr alloys. This approach utilizes machine learning to examine the shapes within images of the alloys' microstructures and predict their mechanical and electronic properties. This generative FAGC approach can effectively expand the relatively small training datasets due to the limited availability of materials images labeled with quantitative properties. The process begins with extracting features from the images using neural networks. These features are then mapped onto the Pre-shape space to construct the Geodesic curves. Along these curves, new features are generated, effectively increasing the dataset. Moreover, we design a pseudo-labeling mechanism for these newly generated features to further enhance the training dataset. Our FAGC method has shown remarkable results, significantly improving the accuracy of predicting the electronic conductivity and hardness of Cu-Cr-Zr alloys, with R-squared values of 0.978 and 0.998, respectively. These outcomes underscore the potential of FAGC to address the challenge of limited image data in materials science, providing a powerful tool for establishing detailed and quantitative relationships between complex microstructures and material properties.
DiPrompT: Disentangled Prompt Tuning for Multiple Latent Domain Generalization in Federated Learning
Mar 11, 2024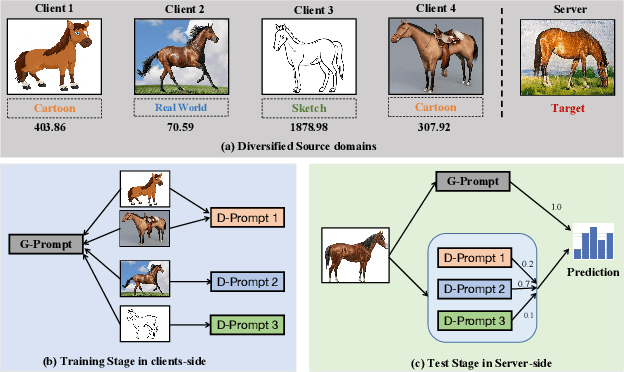
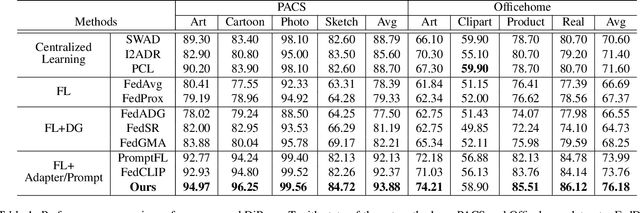
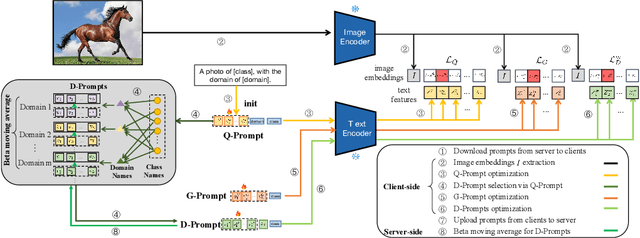
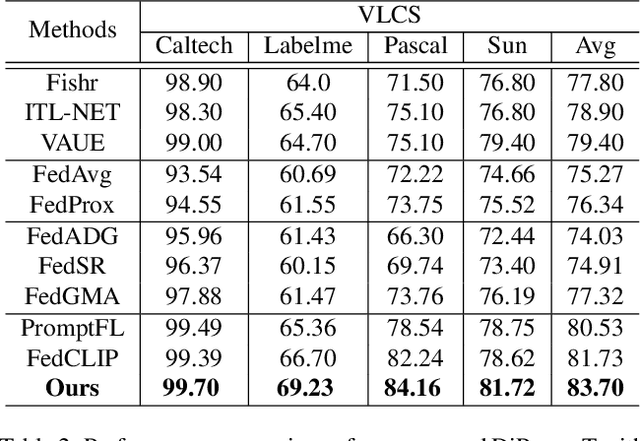
Federated learning (FL) has emerged as a powerful paradigm for learning from decentralized data, and federated domain generalization further considers the test dataset (target domain) is absent from the decentralized training data (source domains). However, most existing FL methods assume that domain labels are provided during training, and their evaluation imposes explicit constraints on the number of domains, which must strictly match the number of clients. Because of the underutilization of numerous edge devices and additional cross-client domain annotations in the real world, such restrictions may be impractical and involve potential privacy leaks. In this paper, we propose an efficient and novel approach, called Disentangled Prompt Tuning (DiPrompT), a method that tackles the above restrictions by learning adaptive prompts for domain generalization in a distributed manner. Specifically, we first design two types of prompts, i.e., global prompt to capture general knowledge across all clients and domain prompts to capture domain-specific knowledge. They eliminate the restriction on the one-to-one mapping between source domains and local clients. Furthermore, a dynamic query metric is introduced to automatically search the suitable domain label for each sample, which includes two-substep text-image alignments based on prompt tuning without labor-intensive annotation. Extensive experiments on multiple datasets demonstrate that our DiPrompT achieves superior domain generalization performance over state-of-the-art FL methods when domain labels are not provided, and even outperforms many centralized learning methods using domain labels.
Global Tropical Cyclone Intensity Forecasting with Multi-modal Multi-scale Causal Autoregressive Model
Feb 16, 2024Accurate forecasting of Tropical cyclone (TC) intensity is crucial for formulating disaster risk reduction strategies. Current methods predominantly rely on limited spatiotemporal information from ERA5 data and neglect the causal relationships between these physical variables, failing to fully capture the spatial and temporal patterns required for intensity forecasting. To address this issue, we propose a Multi-modal multi-Scale Causal AutoRegressive model (MSCAR), which is the first model that combines causal relationships with large-scale multi-modal data for global TC intensity autoregressive forecasting. Furthermore, given the current absence of a TC dataset that offers a wide range of spatial variables, we present the Satellite and ERA5-based Tropical Cyclone Dataset (SETCD), which stands as the longest and most comprehensive global dataset related to TCs. Experiments on the dataset show that MSCAR outperforms the state-of-the-art methods, achieving maximum reductions in global and regional forecast errors of 9.52% and 6.74%, respectively. The code and dataset are publicly available at https://anonymous.4open.science/r/MSCAR.
ExtremeCast: Boosting Extreme Value Prediction for Global Weather Forecast
Feb 02, 2024Data-driven weather forecast based on machine learning (ML) has experienced rapid development and demonstrated superior performance in the global medium-range forecast compared to traditional physics-based dynamical models. However, most of these ML models struggle with accurately predicting extreme weather, which is closely related to the extreme value prediction. Through mathematical analysis, we prove that the use of symmetric losses, such as the Mean Squared Error (MSE), leads to biased predictions and underestimation of extreme values. To address this issue, we introduce Exloss, a novel loss function that performs asymmetric optimization and highlights extreme values to obtain accurate extreme weather forecast. Furthermore, we introduce a training-free extreme value enhancement strategy named ExEnsemble, which increases the variance of pixel values and improves the forecast robustness. Combined with an advanced global weather forecast model, extensive experiments show that our solution can achieve state-of-the-art performance in extreme weather prediction, while maintaining the overall forecast accuracy comparable to the top medium-range forecast models.
Is Artificial Intelligence Providing the Second Revolution for Weather Forecasting?
Jan 30, 2024The rapid advancement of artificial intelligence technologies, particularly in recent years, has led to the emergence of several large parameter artificial intelligence weather forecast models. These models represent a significant breakthrough, overcoming the limitations of traditional numerical weather prediction models and indicating a potential second revolution for weather forecast. This study explores the evolution of these advanced artificial intelligence forecast models, and based on the identified commonalities, proposes the "Three Large Rules" for their development. We discuss the potential of artificial intelligence in revolutionizing numerical weather prediction, briefly outlining the underlying reasons for this potential. Additionally, we explore key areas for future development prospects for large artificial intelligence weather forecast models, integrating the entire numerical prediction process. Through an example that combines a large artificial intelligence model with ocean wave forecasting, we illustrate how forecasters can adapt and leverage the advanced artificial intelligence model. While acknowledging the high accuracy, computational efficiency, and ease of deployment of large artificial intelligence forecast models, we emphasize the irreplaceable values of traditional numerical forecasts. We believe that the optimal future of weather forecasting lies in achieving a seamless integration of artificial intelligence and traditional numerical models. Such a synthesis is anticipated to offer a more comprehensive and reliable approach for future weather forecasting.
FengWu-GHR: Learning the Kilometer-scale Medium-range Global Weather Forecasting
Jan 28, 2024Kilometer-scale modeling of global atmosphere dynamics enables fine-grained weather forecasting and decreases the risk of disastrous weather and climate activity. Therefore, building a kilometer-scale global forecast model is a persistent pursuit in the meteorology domain. Active international efforts have been made in past decades to improve the spatial resolution of numerical weather models. Nonetheless, developing the higher resolution numerical model remains a long-standing challenge due to the substantial consumption of computational resources. Recent advances in data-driven global weather forecasting models utilize reanalysis data for model training and have demonstrated comparable or even higher forecasting skills than numerical models. However, they are all limited by the resolution of reanalysis data and incapable of generating higher-resolution forecasts. This work presents FengWu-GHR, the first data-driven global weather forecasting model running at the 0.09$^{\circ}$ horizontal resolution. FengWu-GHR introduces a novel approach that opens the door for operating ML-based high-resolution forecasts by inheriting prior knowledge from a pretrained low-resolution model. The hindcast of weather prediction in 2022 indicates that FengWu-GHR is superior to the IFS-HRES. Furthermore, evaluations on station observations and case studies of extreme events support the competitive operational forecasting skill of FengWu-GHR at the high resolution.
Towards an End-to-End Artificial Intelligence Driven Global Weather Forecasting System
Dec 18, 2023The weather forecasting system is important for science and society, and significant achievements have been made in applying artificial intelligence (AI) to medium-range weather forecasting. However, existing AI-based weather forecasting models still rely on analysis or reanalysis products from the traditional numerical weather prediction (NWP) systems as initial conditions for making predictions, preventing them from being fully independent systems. As a crucial component of an end-to-end global weather forecasting system, data assimilation is vital in generating initial states for forecasting. In this paper, we present an AI-based data assimilation model, i.e., Adas, for global weather variables, which learns to generate the analysis from the background and sparse observations. Different from existing assimilation methods, Adas employs the gated convolution module to handle sparse observations and the gated cross-attention module for capturing the interactions between observations and background efficiently, which are guided by the confidence matrix to represent the availability and quality of observations. Then, we combine Adas with the advanced AI-based weather forecasting model (i.e., FengWu) and construct the first end-to-end AI-based global weather forecasting system: FengWu-Adas. Experiments demonstrate that Adas can assimilate the simulated global observations with the AI-generated background through a one-year simulation and generate high-quality analysis stably in a cyclic manner. Based on the generated analysis, FengWu-Adas exhibits skillful performance and outperforms the Integrated Forecasting System (IFS) in weather forecasting over seven days.
FengWu-4DVar: Coupling the Data-driven Weather Forecasting Model with 4D Variational Assimilation
Dec 16, 2023Weather forecasting is a crucial yet highly challenging task. With the maturity of Artificial Intelligence (AI), the emergence of data-driven weather forecasting models has opened up a new paradigm for the development of weather forecasting systems. Despite the significant successes that have been achieved (e.g., surpassing advanced traditional physical models for global medium-range forecasting), existing data-driven weather forecasting models still rely on the analysis fields generated by the traditional assimilation and forecasting system, which hampers the significance of data-driven weather forecasting models regarding both computational cost and forecasting accuracy. In this work, we explore the possibility of coupling the data-driven weather forecasting model with data assimilation by integrating the global AI weather forecasting model, FengWu, with one of the most popular assimilation algorithms, Four-Dimensional Variational (4DVar) assimilation, and develop an AI-based cyclic weather forecasting system, FengWu-4DVar. FengWu-4DVar can incorporate observational data into the data-driven weather forecasting model and consider the temporal evolution of atmospheric dynamics to obtain accurate analysis fields for making predictions in a cycling manner without the help of physical models. Owning to the auto-differentiation ability of deep learning models, FengWu-4DVar eliminates the need of developing the cumbersome adjoint model, which is usually required in the traditional implementation of the 4DVar algorithm. Experiments on the simulated observational dataset demonstrate that FengWu-4DVar is capable of generating reasonable analysis fields for making accurate and efficient iterative predictions.
Traffic Sign Interpretation in Real Road Scene
Nov 28, 2023Most existing traffic sign-related works are dedicated to detecting and recognizing part of traffic signs individually, which fails to analyze the global semantic logic among signs and may convey inaccurate traffic instruction. Following the above issues, we propose a traffic sign interpretation (TSI) task, which aims to interpret global semantic interrelated traffic signs (e.g.,~driving instruction-related texts, symbols, and guide panels) into a natural language for providing accurate instruction support to autonomous or assistant driving. Meanwhile, we design a multi-task learning architecture for TSI, which is responsible for detecting and recognizing various traffic signs and interpreting them into a natural language like a human. Furthermore, the absence of a public TSI available dataset prompts us to build a traffic sign interpretation dataset, namely TSI-CN. The dataset consists of real road scene images, which are captured from the highway and the urban way in China from a driver's perspective. It contains rich location labels of texts, symbols, and guide panels, and the corresponding natural language description labels. Experiments on TSI-CN demonstrate that the TSI task is achievable and the TSI architecture can interpret traffic signs from scenes successfully even if there is a complex semantic logic among signs. The TSI-CN dataset and the source code of the TSI architecture will be publicly available after the revision process.
STEERER: Resolving Scale Variations for Counting and Localization via Selective Inheritance Learning
Aug 21, 2023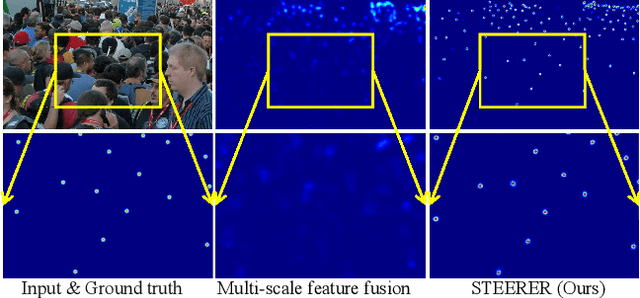
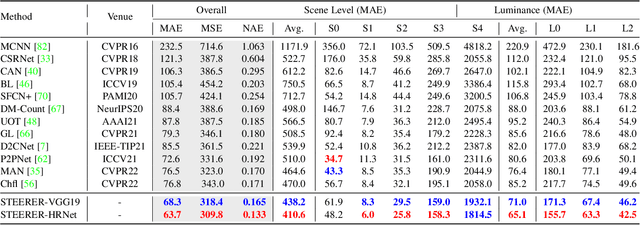

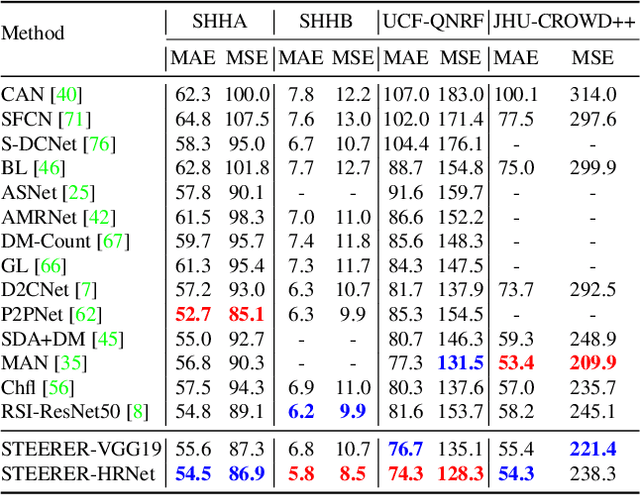
Scale variation is a deep-rooted problem in object counting, which has not been effectively addressed by existing scale-aware algorithms. An important factor is that they typically involve cooperative learning across multi-resolutions, which could be suboptimal for learning the most discriminative features from each scale. In this paper, we propose a novel method termed STEERER (\textbf{S}elec\textbf{T}iv\textbf{E} inh\textbf{ER}itance l\textbf{E}a\textbf{R}ning) that addresses the issue of scale variations in object counting. STEERER selects the most suitable scale for patch objects to boost feature extraction and only inherits discriminative features from lower to higher resolution progressively. The main insights of STEERER are a dedicated Feature Selection and Inheritance Adaptor (FSIA), which selectively forwards scale-customized features at each scale, and a Masked Selection and Inheritance Loss (MSIL) that helps to achieve high-quality density maps across all scales. Our experimental results on nine datasets with counting and localization tasks demonstrate the unprecedented scale generalization ability of STEERER. Code is available at \url{https://github.com/taohan10200/STEERER}.