 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulin Chen
CREST: Cross-modal Resonance through Evidential Deep Learning for Enhanced Zero-Shot Learning
Apr 15, 2024
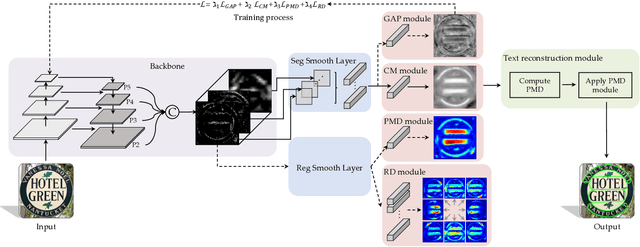
Zero-shot learning (ZSL) enables the recognition of novel classes by leveraging semantic knowledge transfer from known to unknown categories. This knowledge, typically encapsulated in attribute descriptions, aids in identifying class-specific visual features, thus facilitating visual-semantic alignment and improving ZSL performance. However, real-world challenges such as distribution imbalances and attribute co-occurrence among instances often hinder the discernment of local variances in images, a problem exacerbated by the scarcity of fine-grained, region-specific attribute annotations. Moreover, the variability in visual presentation within categories can also skew attribute-category associations. In response, we propose a bidirectional cross-modal ZSL approach CREST. It begins by extracting representations for attribute and visual localization and employs Evidential Deep Learning (EDL) to measure underlying epistemic uncertainty, thereby enhancing the model's resilience against hard negatives. CREST incorporates dual learning pathways, focusing on both visual-category and attribute-category alignments, to ensure robust correlation between latent and observable spaces. Moreover, we introduce an uncertainty-informed cross-modal fusion technique to refine visual-attribute inference. Extensive experiments demonstrate our model's effectiveness and unique explainability across multiple datasets. Our code and data are available at: Comments: Ongoing work; 10 pages, 2 Tables, 9 Figures; Repo is available at https://github.com/JethroJames/CREST.
Deep Contrastive Graph Learning with Clustering-Oriented Guidance
Feb 25, 2024Graph Convolutional Network (GCN) has exhibited remarkable potential in improving graph-based clustering. To handle the general clustering scenario without a prior graph, these models estimate an initial graph beforehand to apply GCN. Throughout the literature, we have witnessed that 1) most models focus on the initial graph while neglecting the original features. Therefore, the discriminability of the learned representation may be corrupted by a low-quality initial graph; 2) the training procedure lacks effective clustering guidance, which may lead to the incorporation of clustering-irrelevant information into the learned graph. To tackle these problems, the Deep Contrastive Graph Learning (DCGL) model is proposed for general data clustering. Specifically, we establish a pseudo-siamese network, which incorporates auto-encoder with GCN to emphasize both the graph structure and the original features. On this basis, feature-level contrastive learning is introduced to enhance the discriminative capacity, and the relationship between samples and centroids is employed as the clustering-oriented guidance. Afterward, a two-branch graph learning mechanism is designed to extract the local and global structural relationships, which are further embedded into a unified graph under the cluster-level contrastive guidance. Experimental results on several benchmark datasets demonstrate the superiority of DCGL against state-of-the-art algorithms.
Traffic Sign Interpretation in Real Road Scene
Nov 28, 2023Most existing traffic sign-related works are dedicated to detecting and recognizing part of traffic signs individually, which fails to analyze the global semantic logic among signs and may convey inaccurate traffic instruction. Following the above issues, we propose a traffic sign interpretation (TSI) task, which aims to interpret global semantic interrelated traffic signs (e.g.,~driving instruction-related texts, symbols, and guide panels) into a natural language for providing accurate instruction support to autonomous or assistant driving. Meanwhile, we design a multi-task learning architecture for TSI, which is responsible for detecting and recognizing various traffic signs and interpreting them into a natural language like a human. Furthermore, the absence of a public TSI available dataset prompts us to build a traffic sign interpretation dataset, namely TSI-CN. The dataset consists of real road scene images, which are captured from the highway and the urban way in China from a driver's perspective. It contains rich location labels of texts, symbols, and guide panels, and the corresponding natural language description labels. Experiments on TSI-CN demonstrate that the TSI task is achievable and the TSI architecture can interpret traffic signs from scenes successfully even if there is a complex semantic logic among signs. The TSI-CN dataset and the source code of the TSI architecture will be publicly available after the revision process.
One-Shot High-Fidelity Talking-Head Synthesis with Deformable Neural Radiance Field
Apr 11, 2023
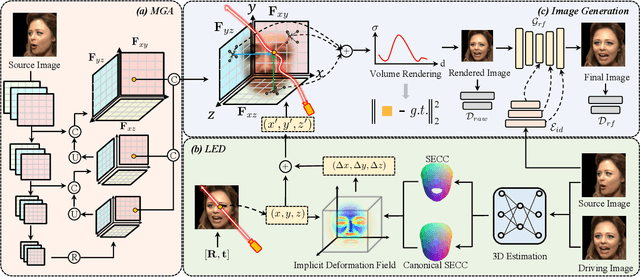


Talking head generation aims to generate faces that maintain the identity information of the source image and imitate the motion of the driving image. Most pioneering methods rely primarily on 2D representations and thus will inevitably suffer from face distortion when large head rotations are encountered. Recent works instead employ explicit 3D structural representations or implicit neural rendering to improve performance under large pose changes. Nevertheless, the fidelity of identity and expression is not so desirable, especially for novel-view synthesis. In this paper, we propose HiDe-NeRF, which achieves high-fidelity and free-view talking-head synthesis. Drawing on the recently proposed Deformable Neural Radiance Fields, HiDe-NeRF represents the 3D dynamic scene into a canonical appearance field and an implicit deformation field, where the former comprises the canonical source face and the latter models the driving pose and expression. In particular, we improve fidelity from two aspects: (i) to enhance identity expressiveness, we design a generalized appearance module that leverages multi-scale volume features to preserve face shape and details; (ii) to improve expression preciseness, we propose a lightweight deformation module that explicitly decouples the pose and expression to enable precise expression modeling. Extensive experiments demonstrate that our proposed approach can generate better results than previous works. Project page: https://www.waytron.net/hidenerf/
Fully Self-Supervised Depth Estimation from Defocus Clue
Mar 27, 2023
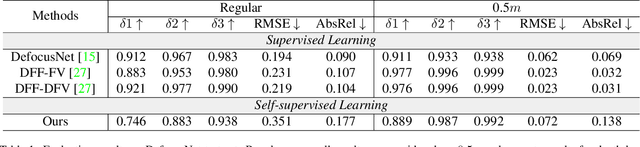
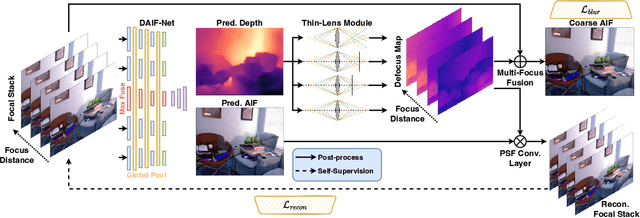
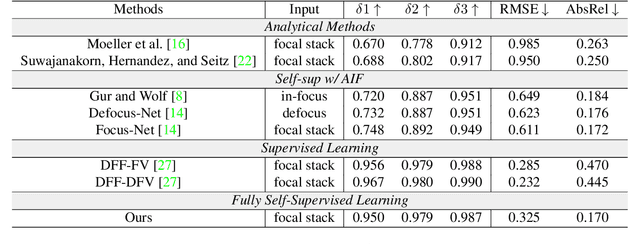
Depth-from-defocus (DFD), modeling the relationship between depth and defocus pattern in images, has demonstrated promising performance in depth estimation. Recently, several self-supervised works try to overcome the difficulties in acquiring accurate depth ground-truth. However, they depend on the all-in-focus (AIF) images, which cannot be captured in real-world scenarios. Such limitation discourages the applications of DFD methods. To tackle this issue, we propose a completely self-supervised framework that estimates depth purely from a sparse focal stack. We show that our framework circumvents the needs for the depth and AIF image ground-truth, and receives superior predictions, thus closing the gap between the theoretical success of DFD works and their applications in the real world. In particular, we propose (i) a more realistic setting for DFD tasks, where no depth or AIF image ground-truth is available; (ii) a novel self-supervision framework that provides reliable predictions of depth and AIF image under the challenging setting. The proposed framework uses a neural model to predict the depth and AIF image, and utilizes an optical model to validate and refine the prediction. We verify our framework on three benchmark datasets with rendered focal stacks and real focal stacks. Qualitative and quantitative evaluations show that our method provides a strong baseline for self-supervised DFD tasks.
Propagate And Calibrate: Real-time Passive Non-line-of-sight Tracking
Mar 27, 2023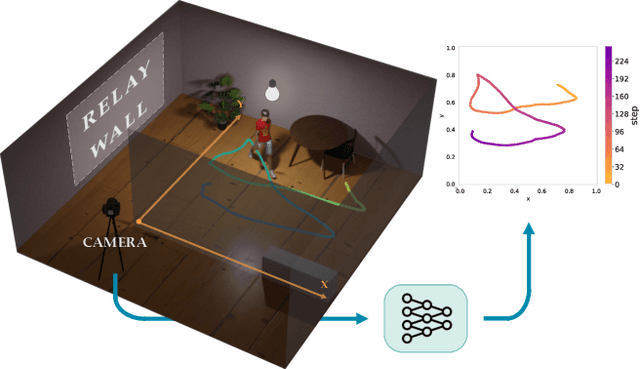
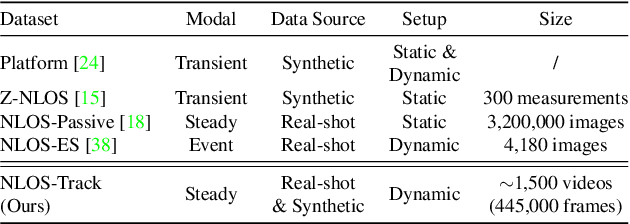


Non-line-of-sight (NLOS) tracking has drawn increasing attention in recent years, due to its ability to detect object motion out of sight. Most previous works on NLOS tracking rely on active illumination, e.g., laser, and suffer from high cost and elaborate experimental conditions. Besides, these techniques are still far from practical application due to oversimplified settings. In contrast, we propose a purely passive method to track a person walking in an invisible room by only observing a relay wall, which is more in line with real application scenarios, e.g., security. To excavate imperceptible changes in videos of the relay wall, we introduce difference frames as an essential carrier of temporal-local motion messages. In addition, we propose PAC-Net, which consists of alternating propagation and calibration, making it capable of leveraging both dynamic and static messages on a frame-level granularity. To evaluate the proposed method, we build and publish the first dynamic passive NLOS tracking dataset, NLOS-Track, which fills the vacuum of realistic NLOS datasets. NLOS-Track contains thousands of NLOS video clips and corresponding trajectories. Both real-shot and synthetic data are included. Our codes and dataset are available at https://againstentropy.github.io/NLOS-Track/.
Adaptive Shrink-Mask for Text Detection
Nov 18, 2021

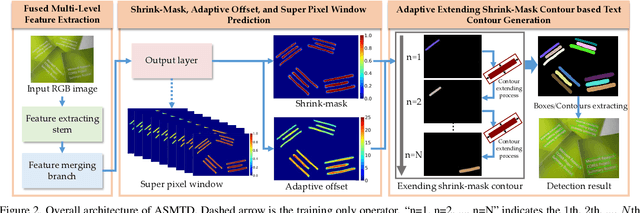

Existing real-time text detectors reconstruct text contours by shrink-masks directly, which simplifies the framework and can make the model run fast. However, the strong dependence on predicted shrink-masks leads to unstable detection results. Moreover, the discrimination of shrink-masks is a pixelwise prediction task. Supervising the network by shrink-masks only will lose much semantic context, which leads to the false detection of shrink-masks. To address these problems, we construct an efficient text detection network, Adaptive Shrink-Mask for Text Detection (ASMTD), which improves the accuracy during training and reduces the complexity of the inference process. At first, the Adaptive Shrink-Mask (ASM) is proposed to represent texts by shrink-masks and independent adaptive offsets. It weakens the coupling of texts to shrink-masks, which improves the robustness of detection results. Then, the Super-pixel Window (SPW) is designed to supervise the network. It utilizes the surroundings of each pixel to improve the reliability of predicted shrink-masks and does not appear during testing. In the end, a lightweight feature merging branch is constructed to reduce the computational cost. As demonstrated in the experiments, our method is superior to existing state-of-the-art (SOTA) methods in both detection accuracy and speed on multiple benchmarks.
MT: Multi-Perspective Feature Learning Network for Scene Text Detection
May 12, 2021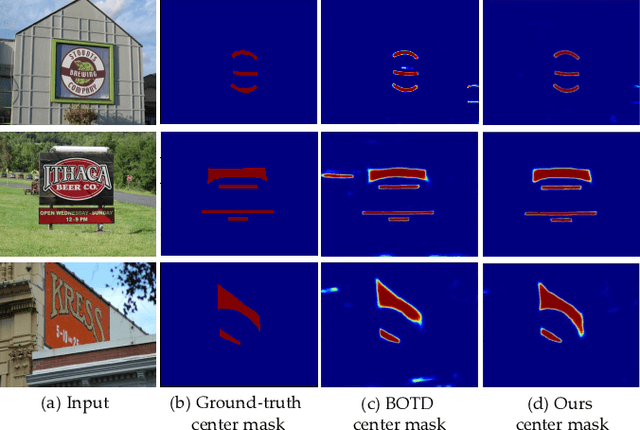


Text detection, the key technology for understanding scene text, has become an attractive research topic. For detecting various scene texts, researchers propose plenty of detectors with different advantages: detection-based models enjoy fast detection speed, and segmentation-based algorithms are not limited by text shapes. However, for most intelligent systems, the detector needs to detect arbitrary-shaped texts with high speed and accuracy simultaneously. Thus, in this study, we design an efficient pipeline named as MT, which can detect adhesive arbitrary-shaped texts with only a single binary mask in the inference stage. This paper presents the contributions on three aspects: (1) a light-weight detection framework is designed to speed up the inference process while keeping high detection accuracy; (2) a multi-perspective feature module is proposed to learn more discriminative representations to segment the mask accurately; (3) a multi-factor constraints IoU minimization loss is introduced for training the proposed model. The effectiveness of MT is evaluated on four real-world scene text datasets, and it surpasses all the state-of-the-art competitors to a large extent.
Spatial-Spectral Clustering with Anchor Graph for Hyperspectral Image
Apr 24, 2021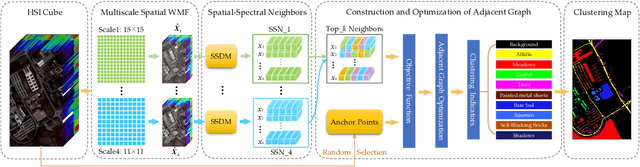

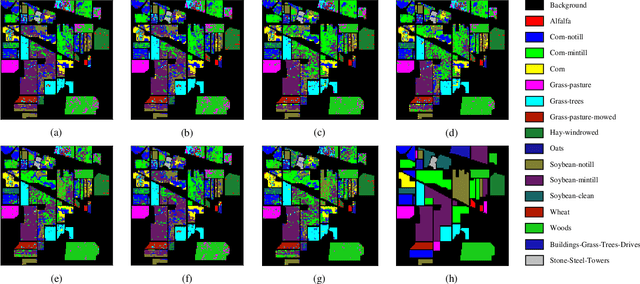
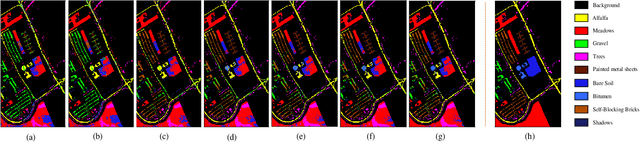
Hyperspectral image (HSI) clustering, which aims at dividing hyperspectral pixels into clusters, has drawn significant attention in practical applications. Recently, many graph-based clustering methods, which construct an adjacent graph to model the data relationship, have shown dominant performance. However, the high dimensionality of HSI data makes it hard to construct the pairwise adjacent graph. Besides, abundant spatial structures are often overlooked during the clustering procedure. In order to better handle the high dimensionality problem and preserve the spatial structures, this paper proposes a novel unsupervised approach called spatial-spectral clustering with anchor graph (SSCAG) for HSI data clustering. The SSCAG has the following contributions: 1) the anchor graph-based strategy is used to construct a tractable large graph for HSI data, which effectively exploits all data points and reduces the computational complexity; 2) a new similarity metric is presented to embed the spatial-spectral information into the combined adjacent graph, which can mine the intrinsic property structure of HSI data; 3) an effective neighbors assignment strategy is adopted in the optimization, which performs the singular value decomposition (SVD) on the adjacent graph to get solutions efficiently. Extensive experiments on three public HSI datasets show that the proposed SSCAG is competitive against the state-of-the-art approaches.
Auto-weighted Multi-view Feature Selection with Graph Optimization
Apr 11, 2021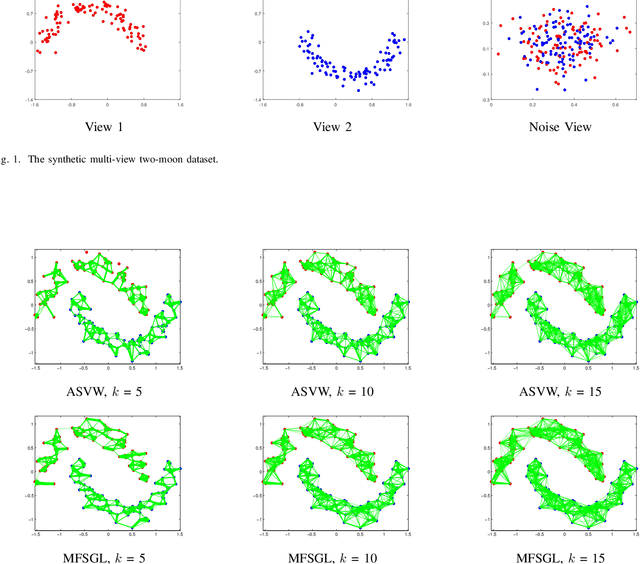
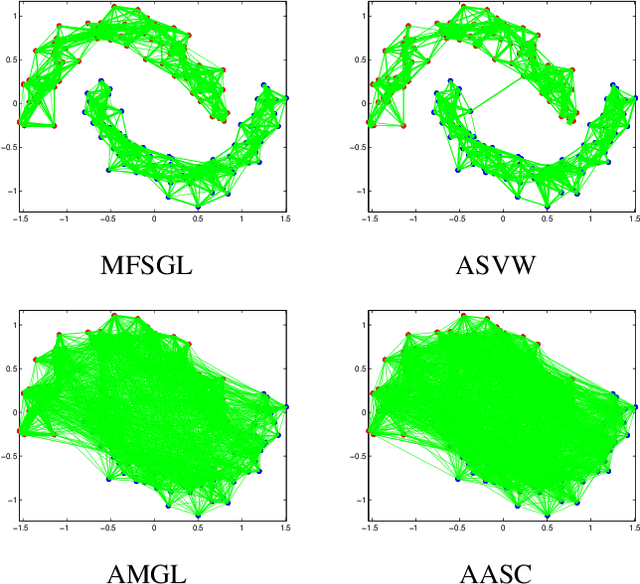
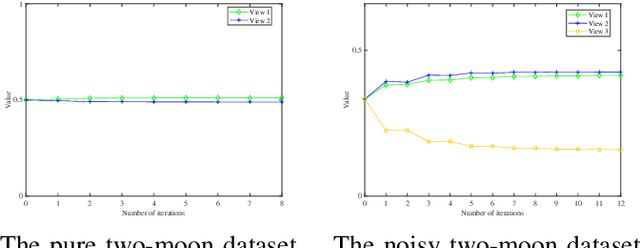
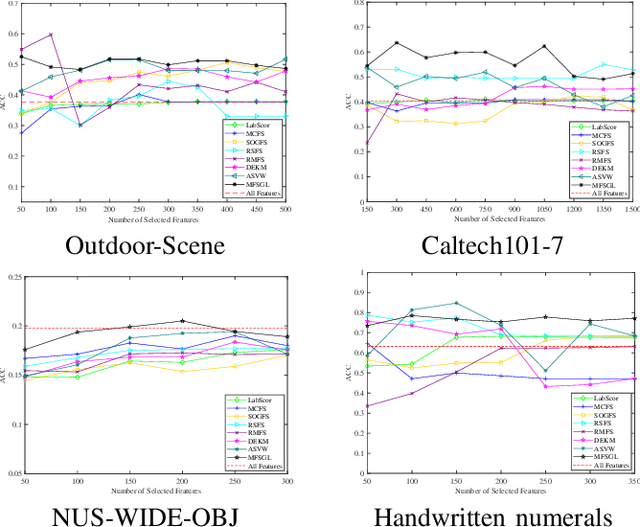
In this paper, we focus on the unsupervised multi-view feature selection which tries to handle high dimensional data in the field of multi-view learning. Although some graph-based methods have achieved satisfactory performance, they ignore the underlying data structure across different views. Besides, their pre-defined laplacian graphs are sensitive to the noises in the original data space, and fail to get the optimal neighbor assignment. To address the above problems, we propose a novel unsupervised multi-view feature selection model based on graph learning, and the contributions are threefold: (1) during the feature selection procedure, the consensus similarity graph shared by different views is learned. Therefore, the proposed model can reveal the data relationship from the feature subset. (2) a reasonable rank constraint is added to optimize the similarity matrix to obtain more accurate information; (3) an auto-weighted framework is presented to assign view weights adaptively, and an effective alternative iterative algorithm is proposed to optimize the problem. Experiments on various datasets demonstrate the superiority of the proposed method compared with the state-of-the-art methods.