 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFadi Boutros
GraFIQs: Face Image Quality Assessment Using Gradient Magnitudes
Apr 18, 2024
Face Image Quality Assessment (FIQA) estimates the utility of face images for automated face recognition (FR) systems. We propose in this work a novel approach to assess the quality of face images based on inspecting the required changes in the pre-trained FR model weights to minimize differences between testing samples and the distribution of the FR training dataset. To achieve that, we propose quantifying the discrepancy in Batch Normalization statistics (BNS), including mean and variance, between those recorded during FR training and those obtained by processing testing samples through the pretrained FR model. We then generate gradient magnitudes of pretrained FR weights by backpropagating the BNS through the pretrained model. The cumulative absolute sum of these gradient magnitudes serves as the FIQ for our approach. Through comprehensive experimentation, we demonstrate the effectiveness of our training-free and quality labeling-free approach, achieving competitive performance to recent state-of-theart FIQA approaches without relying on quality labeling, the need to train regression networks, specialized architectures, or designing and optimizing specific loss functions.
Second Edition FRCSyn Challenge at CVPR 2024: Face Recognition Challenge in the Era of Synthetic Data
Apr 16, 2024Synthetic data is gaining increasing relevance for training machine learning models. This is mainly motivated due to several factors such as the lack of real data and intra-class variability, time and errors produced in manual labeling, and in some cases privacy concerns, among others. This paper presents an overview of the 2nd edition of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at CVPR 2024. FRCSyn aims to investigate the use of synthetic data in face recognition to address current technological limitations, including data privacy concerns, demographic biases, generalization to novel scenarios, and performance constraints in challenging situations such as aging, pose variations, and occlusions. Unlike the 1st edition, in which synthetic data from DCFace and GANDiffFace methods was only allowed to train face recognition systems, in this 2nd edition we propose new sub-tasks that allow participants to explore novel face generative methods. The outcomes of the 2nd FRCSyn Challenge, along with the proposed experimental protocol and benchmarking contribute significantly to the application of synthetic data to face recognition.
* arXiv admin note: text overlap with arXiv:2311.10476
AI-KD: Towards Alignment Invariant Face Image Quality Assessment Using Knowledge Distillation
Apr 15, 2024Face Image Quality Assessment (FIQA) techniques have seen steady improvements over recent years, but their performance still deteriorates if the input face samples are not properly aligned. This alignment sensitivity comes from the fact that most FIQA techniques are trained or designed using a specific face alignment procedure. If the alignment technique changes, the performance of most existing FIQA techniques quickly becomes suboptimal. To address this problem, we present in this paper a novel knowledge distillation approach, termed AI-KD that can extend on any existing FIQA technique, improving its robustness to alignment variations and, in turn, performance with different alignment procedures. To validate the proposed distillation approach, we conduct comprehensive experiments on 6 face datasets with 4 recent face recognition models and in comparison to 7 state-of-the-art FIQA techniques. Our results show that AI-KD consistently improves performance of the initial FIQA techniques not only with misaligned samples, but also with properly aligned facial images. Furthermore, it leads to a new state-of-the-art, when used with a competitive initial FIQA approach. The code for AI-KD is made publicly available from: https://github.com/LSIbabnikz/AI-KD.
SDFR: Synthetic Data for Face Recognition Competition
Apr 09, 2024Large-scale face recognition datasets are collected by crawling the Internet and without individuals' consent, raising legal, ethical, and privacy concerns. With the recent advances in generative models, recently several works proposed generating synthetic face recognition datasets to mitigate concerns in web-crawled face recognition datasets. This paper presents the summary of the Synthetic Data for Face Recognition (SDFR) Competition held in conjunction with the 18th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2024) and established to investigate the use of synthetic data for training face recognition models. The SDFR competition was split into two tasks, allowing participants to train face recognition systems using new synthetic datasets and/or existing ones. In the first task, the face recognition backbone was fixed and the dataset size was limited, while the second task provided almost complete freedom on the model backbone, the dataset, and the training pipeline. The submitted models were trained on existing and also new synthetic datasets and used clever methods to improve training with synthetic data. The submissions were evaluated and ranked on a diverse set of seven benchmarking datasets. The paper gives an overview of the submitted face recognition models and reports achieved performance compared to baseline models trained on real and synthetic datasets. Furthermore, the evaluation of submissions is extended to bias assessment across different demography groups. Lastly, an outlook on the current state of the research in training face recognition models using synthetic data is presented, and existing problems as well as potential future directions are also discussed.
If It's Not Enough, Make It So: Reducing Authentic Data Demand in Face Recognition through Synthetic Faces
Apr 04, 2024Recent advances in deep face recognition have spurred a growing demand for large, diverse, and manually annotated face datasets. Acquiring authentic, high-quality data for face recognition has proven to be a challenge, primarily due to privacy concerns. Large face datasets are primarily sourced from web-based images, lacking explicit user consent. In this paper, we examine whether and how synthetic face data can be used to train effective face recognition models with reduced reliance on authentic images, thereby mitigating data collection concerns. First, we explored the performance gap among recent state-of-the-art face recognition models, trained with synthetic data only and authentic (scarce) data only. Then, we deepened our analysis by training a state-of-the-art backbone with various combinations of synthetic and authentic data, gaining insights into optimizing the limited use of the latter for verification accuracy. Finally, we assessed the effectiveness of data augmentation approaches on synthetic and authentic data, with the same goal in mind. Our results highlighted the effectiveness of FR trained on combined datasets, particularly when combined with appropriate augmentation techniques.
FRCSyn Challenge at WACV 2024:Face Recognition Challenge in the Era of Synthetic Data
Nov 17, 2023Despite the widespread adoption of face recognition technology around the world, and its remarkable performance on current benchmarks, there are still several challenges that must be covered in more detail. This paper offers an overview of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at WACV 2024. This is the first international challenge aiming to explore the use of synthetic data in face recognition to address existing limitations in the technology. Specifically, the FRCSyn Challenge targets concerns related to data privacy issues, demographic biases, generalization to unseen scenarios, and performance limitations in challenging scenarios, including significant age disparities between enrollment and testing, pose variations, and occlusions. The results achieved in the FRCSyn Challenge, together with the proposed benchmark, contribute significantly to the application of synthetic data to improve face recognition technology.
Bias and Diversity in Synthetic-based Face Recognition
Nov 07, 2023Synthetic data is emerging as a substitute for authentic data to solve ethical and legal challenges in handling authentic face data. The current models can create real-looking face images of people who do not exist. However, it is a known and sensitive problem that face recognition systems are susceptible to bias, i.e. performance differences between different demographic and non-demographics attributes, which can lead to unfair decisions. In this work, we investigate how the diversity of synthetic face recognition datasets compares to authentic datasets, and how the distribution of the training data of the generative models affects the distribution of the synthetic data. To do this, we looked at the distribution of gender, ethnicity, age, and head position. Furthermore, we investigated the concrete bias of three recent synthetic-based face recognition models on the studied attributes in comparison to a baseline model trained on authentic data. Our results show that the generator generate a similar distribution as the used training data in terms of the different attributes. With regard to bias, it can be seen that the synthetic-based models share a similar bias behavior with the authentic-based models. However, with the uncovered lower intra-identity attribute consistency seems to be beneficial in reducing bias.
IDiff-Face: Synthetic-based Face Recognition through Fizzy Identity-Conditioned Diffusion Models
Aug 10, 2023
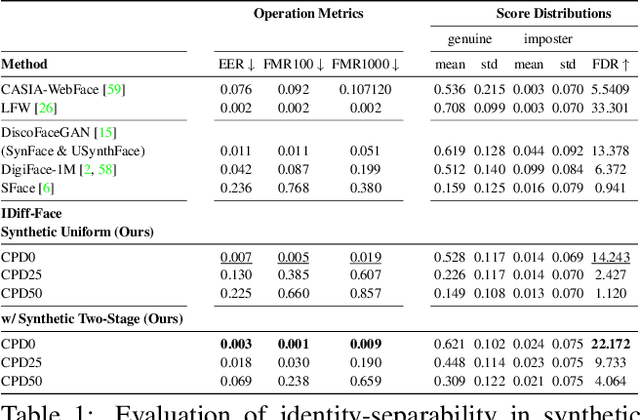

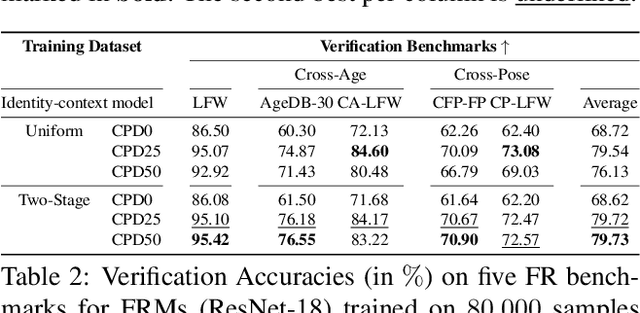
The availability of large-scale authentic face databases has been crucial to the significant advances made in face recognition research over the past decade. However, legal and ethical concerns led to the recent retraction of many of these databases by their creators, raising questions about the continuity of future face recognition research without one of its key resources. Synthetic datasets have emerged as a promising alternative to privacy-sensitive authentic data for face recognition development. However, recent synthetic datasets that are used to train face recognition models suffer either from limitations in intra-class diversity or cross-class (identity) discrimination, leading to less optimal accuracies, far away from the accuracies achieved by models trained on authentic data. This paper targets this issue by proposing IDiff-Face, a novel approach based on conditional latent diffusion models for synthetic identity generation with realistic identity variations for face recognition training. Through extensive evaluations, our proposed synthetic-based face recognition approach pushed the limits of state-of-the-art performances, achieving, for example, 98.00% accuracy on the Labeled Faces in the Wild (LFW) benchmark, far ahead from the recent synthetic-based face recognition solutions with 95.40% and bridging the gap to authentic-based face recognition with 99.82% accuracy.
EFaR 2023: Efficient Face Recognition Competition
Aug 08, 2023
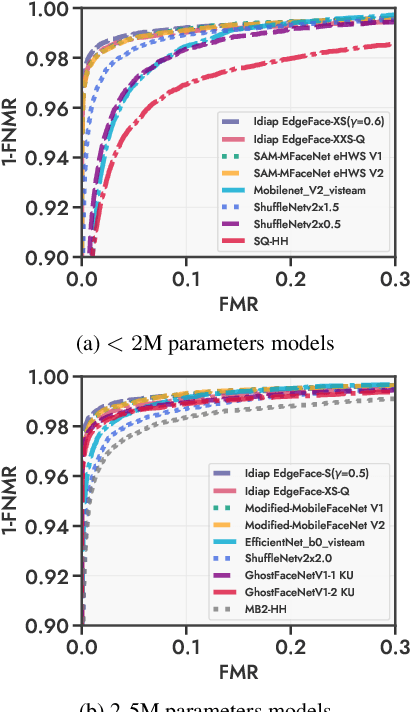
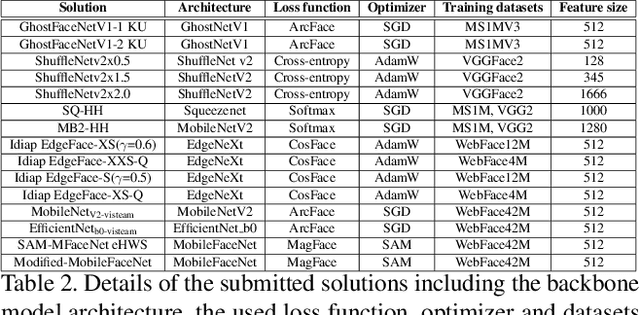
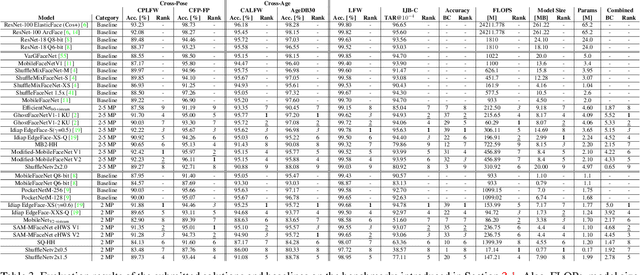
This paper presents the summary of the Efficient Face Recognition Competition (EFaR) held at the 2023 International Joint Conference on Biometrics (IJCB 2023). The competition received 17 submissions from 6 different teams. To drive further development of efficient face recognition models, the submitted solutions are ranked based on a weighted score of the achieved verification accuracies on a diverse set of benchmarks, as well as the deployability given by the number of floating-point operations and model size. The evaluation of submissions is extended to bias, cross-quality, and large-scale recognition benchmarks. Overall, the paper gives an overview of the achieved performance values of the submitted solutions as well as a diverse set of baselines. The submitted solutions use small, efficient network architectures to reduce the computational cost, some solutions apply model quantization. An outlook on possible techniques that are underrepresented in current solutions is given as well.
ExFaceGAN: Exploring Identity Directions in GAN's Learned Latent Space for Synthetic Identity Generation
Jul 18, 2023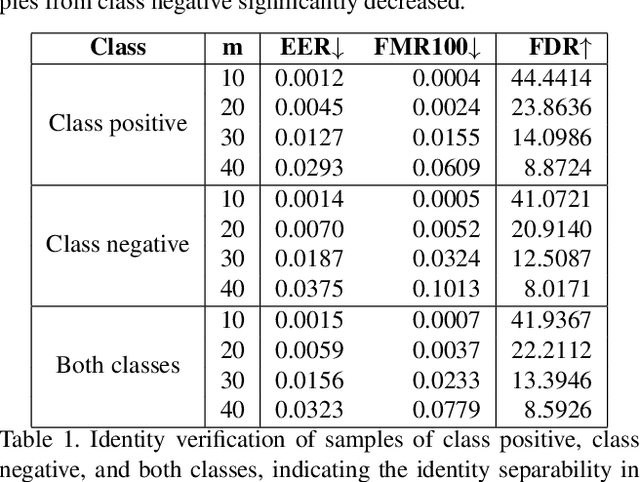
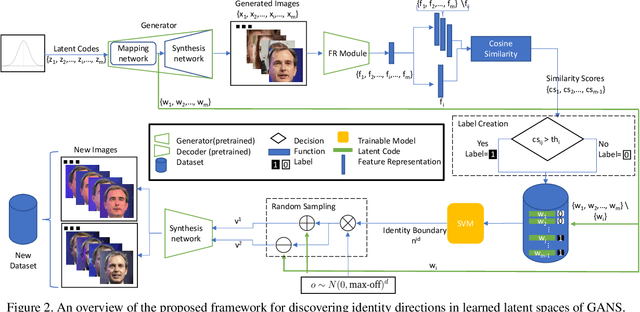
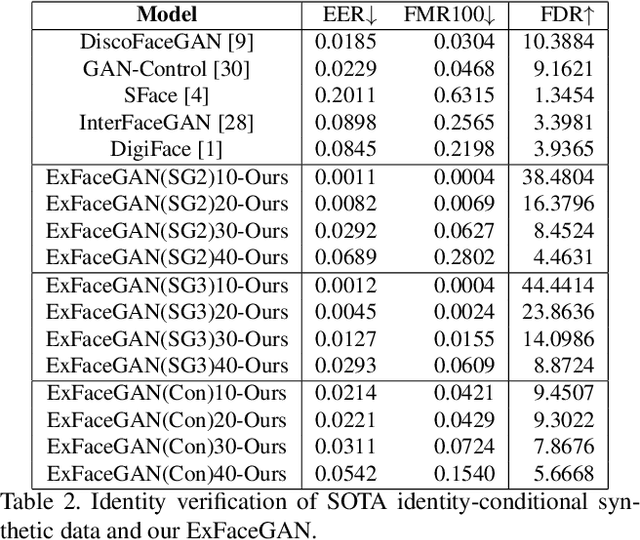
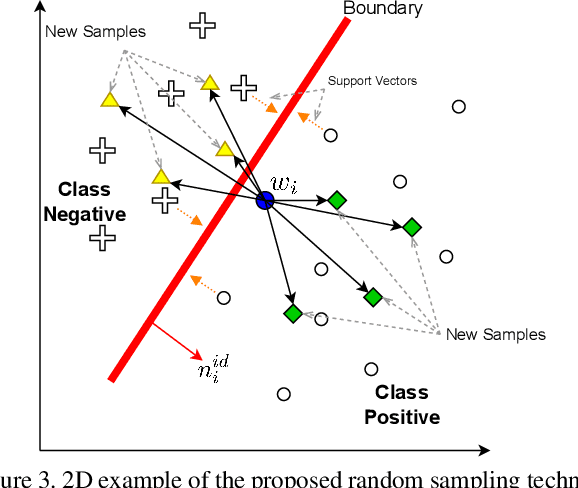
Deep generative models have recently presented impressive results in generating realistic face images of random synthetic identities. To generate multiple samples of a certain synthetic identity, previous works proposed to disentangle the latent space of GANs by incorporating additional supervision or regularization, enabling the manipulation of certain attributes. Others proposed to disentangle specific factors in unconditional pretrained GANs latent spaces to control their output, which also requires supervision by attribute classifiers. Moreover, these attributes are entangled in GAN's latent space, making it difficult to manipulate them without affecting the identity information. We propose in this work a framework, ExFaceGAN, to disentangle identity information in pretrained GANs latent spaces, enabling the generation of multiple samples of any synthetic identity. Given a reference latent code of any synthetic image and latent space of pretrained GAN, our ExFaceGAN learns an identity directional boundary that disentangles the latent space into two sub-spaces, with latent codes of samples that are either identity similar or dissimilar to a reference image. By sampling from each side of the boundary, our ExFaceGAN can generate multiple samples of synthetic identity without the need for designing a dedicated architecture or supervision from attribute classifiers. We demonstrate the generalizability and effectiveness of ExFaceGAN by integrating it into learned latent spaces of three SOTA GAN approaches. As an example of the practical benefit of our ExFaceGAN, we empirically prove that data generated by ExFaceGAN can be successfully used to train face recognition models (\url{https://github.com/fdbtrs/ExFaceGAN}).