 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNaoufel Werghi
A Comprehensive Review of Artificial Intelligence Applications in Major Retinal Conditions
Nov 22, 2023
This paper provides a systematic survey of retinal diseases that cause visual impairments or blindness, emphasizing the importance of early detection for effective treatment. It covers both clinical and automated approaches for detecting retinal disease, focusing on studies from the past decade. The survey evaluates various algorithms for identifying structural abnormalities and diagnosing retinal diseases, and it identifies future research directions based on a critical analysis of existing literature. This comprehensive study, which reviews both clinical and automated detection methods using different modalities, appears to be unique in its scope. Additionally, the survey serves as a helpful guide for researchers interested in digital retinopathy.
3D-TexSeg: Unsupervised Segmentation of 3D Texture using Mutual Transformer Learning
Nov 17, 2023Analysis of the 3D Texture is indispensable for various tasks, such as retrieval, segmentation, classification, and inspection of sculptures, knitted fabrics, and biological tissues. A 3D texture is a locally repeated surface variation independent of the surface's overall shape and can be determined using the local neighborhood and its characteristics. Existing techniques typically employ computer vision techniques that analyze a 3D mesh globally, derive features, and then utilize the obtained features for retrieval or classification. Several traditional and learning-based methods exist in the literature, however, only a few are on 3D texture, and nothing yet, to the best of our knowledge, on the unsupervised schemes. This paper presents an original framework for the unsupervised segmentation of the 3D texture on the mesh manifold. We approach this problem as binary surface segmentation, partitioning the mesh surface into textured and non-textured regions without prior annotation. We devise a mutual transformer-based system comprising a label generator and a cleaner. The two models take geometric image representations of the surface mesh facets and label them as texture or non-texture across an iterative mutual learning scheme. Extensive experiments on three publicly available datasets with diverse texture patterns demonstrate that the proposed framework outperforms standard and SOTA unsupervised techniques and competes reasonably with supervised methods.
Improving Underwater Visual Tracking With a Large Scale Dataset and Image Enhancement
Aug 31, 2023
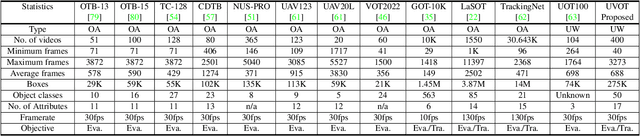


This paper presents a new dataset and general tracker enhancement method for Underwater Visual Object Tracking (UVOT). Despite its significance, underwater tracking has remained unexplored due to data inaccessibility. It poses distinct challenges; the underwater environment exhibits non-uniform lighting conditions, low visibility, lack of sharpness, low contrast, camouflage, and reflections from suspended particles. Performance of traditional tracking methods designed primarily for terrestrial or open-air scenarios drops in such conditions. We address the problem by proposing a novel underwater image enhancement algorithm designed specifically to boost tracking quality. The method has resulted in a significant performance improvement, of up to 5.0% AUC, of state-of-the-art (SOTA) visual trackers. To develop robust and accurate UVOT methods, large-scale datasets are required. To this end, we introduce a large-scale UVOT benchmark dataset consisting of 400 video segments and 275,000 manually annotated frames enabling underwater training and evaluation of deep trackers. The videos are labelled with several underwater-specific tracking attributes including watercolor variation, target distractors, camouflage, target relative size, and low visibility conditions. The UVOT400 dataset, tracking results, and the code are publicly available on: https://github.com/BasitAlawode/UWVOT400.
EFaR 2023: Efficient Face Recognition Competition
Aug 08, 2023
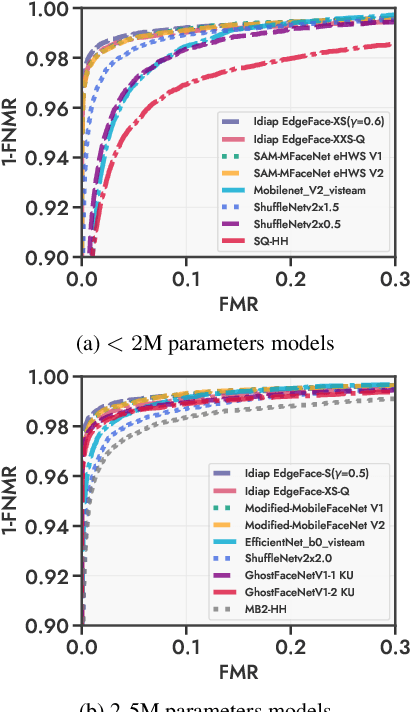
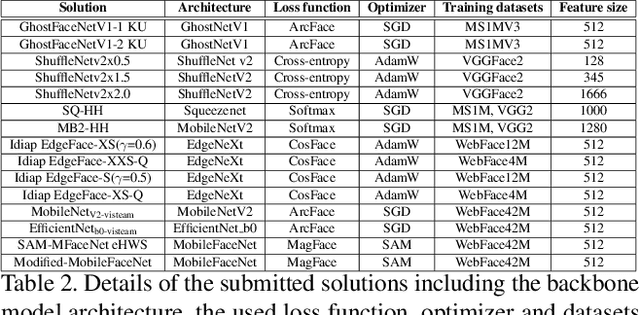
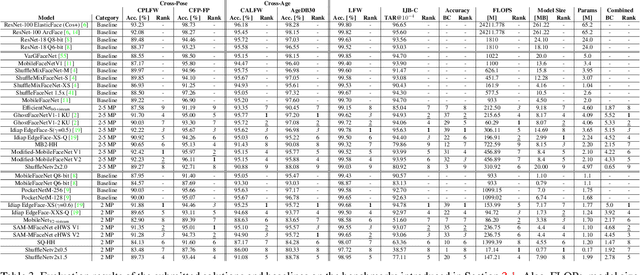
This paper presents the summary of the Efficient Face Recognition Competition (EFaR) held at the 2023 International Joint Conference on Biometrics (IJCB 2023). The competition received 17 submissions from 6 different teams. To drive further development of efficient face recognition models, the submitted solutions are ranked based on a weighted score of the achieved verification accuracies on a diverse set of benchmarks, as well as the deployability given by the number of floating-point operations and model size. The evaluation of submissions is extended to bias, cross-quality, and large-scale recognition benchmarks. Overall, the paper gives an overview of the achieved performance values of the submitted solutions as well as a diverse set of baselines. The submitted solutions use small, efficient network architectures to reduce the computational cost, some solutions apply model quantization. An outlook on possible techniques that are underrepresented in current solutions is given as well.
Convolutional Transformer for Autonomous Recognition and Grading of Tomatoes Under Various Lighting, Occlusion, and Ripeness Conditions
Jul 04, 2023



Harvesting fully ripe tomatoes with mobile robots presents significant challenges in real-world scenarios. These challenges arise from factors such as occlusion caused by leaves and branches, as well as the color similarity between tomatoes and the surrounding foliage during the fruit development stage. The natural environment further compounds these issues with varying light conditions, viewing angles, occlusion factors, and different maturity levels. To overcome these obstacles, this research introduces a novel framework that leverages a convolutional transformer architecture to autonomously recognize and grade tomatoes, irrespective of their occlusion level, lighting conditions, and ripeness. The proposed model is trained and tested using carefully annotated images curated specifically for this purpose. The dataset is prepared under various lighting conditions, viewing perspectives, and employs different mobile camera sensors, distinguishing it from existing datasets such as Laboro Tomato and Rob2Pheno Annotated Tomato. The effectiveness of the proposed framework in handling cluttered and occluded tomato instances was evaluated using two additional public datasets, Laboro Tomato and Rob2Pheno Annotated Tomato, as benchmarks. The evaluation results across these three datasets demonstrate the exceptional performance of our proposed framework, surpassing the state-of-the-art by 58.14%, 65.42%, and 66.39% in terms of mean average precision scores for KUTomaData, Laboro Tomato, and Rob2Pheno Annotated Tomato, respectively. The results underscore the superiority of the proposed model in accurately detecting and delineating tomatoes compared to baseline methods and previous approaches. Specifically, the model achieves an F1-score of 80.14%, a Dice coefficient of 73.26%, and a mean IoU of 66.41% on the KUTomaData image dataset.
Unsupervised Mutual Transformer Learning for Multi-Gigapixel Whole Slide Image Classification
May 03, 2023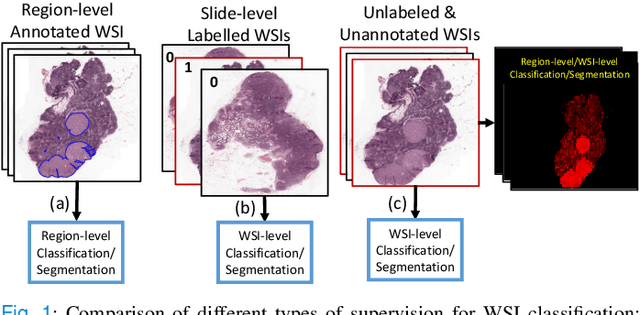
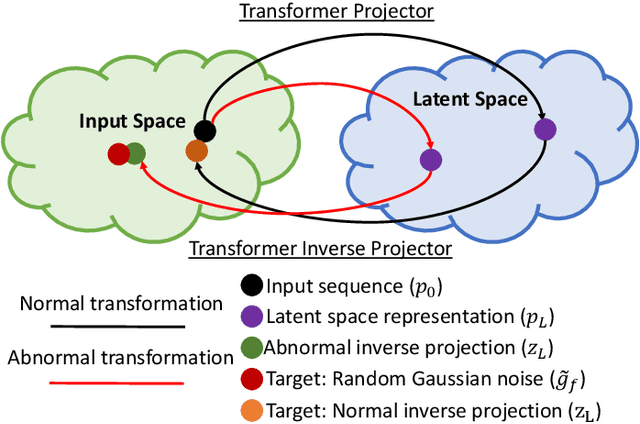
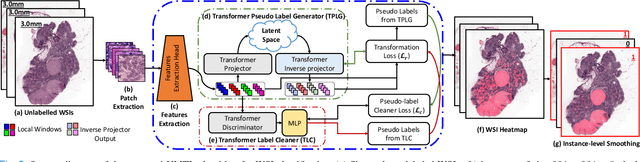
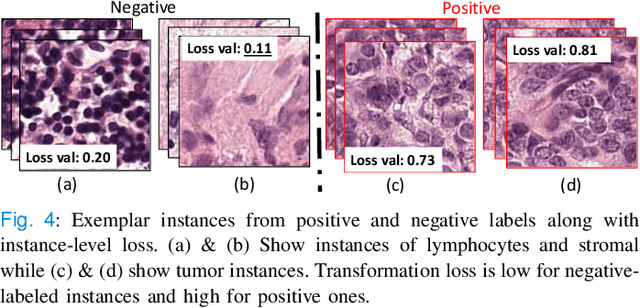
Classification of gigapixel Whole Slide Images (WSIs) is an important prediction task in the emerging area of computational pathology. There has been a surge of research in deep learning models for WSI classification with clinical applications such as cancer detection or prediction of molecular mutations from WSIs. Most methods require expensive and labor-intensive manual annotations by expert pathologists. Weakly supervised Multiple Instance Learning (MIL) methods have recently demonstrated excellent performance; however, they still require large slide-level labeled training datasets that need a careful inspection of each slide by an expert pathologist. In this work, we propose a fully unsupervised WSI classification algorithm based on mutual transformer learning. Instances from gigapixel WSI (i.e., image patches) are transformed into a latent space and then inverse-transformed to the original space. Using the transformation loss, pseudo-labels are generated and cleaned using a transformer label-cleaner. The proposed transformer-based pseudo-label generation and cleaning modules mutually train each other iteratively in an unsupervised manner. A discriminative learning mechanism is introduced to improve normal versus cancerous instance labeling. In addition to unsupervised classification, we demonstrate the effectiveness of the proposed framework for weak supervision for cancer subtype classification as downstream analysis. Extensive experiments on four publicly available datasets show excellent performance compared to the state-of-the-art methods. We intend to make the source code of our algorithm publicly available soon.
Speaker Identification from emotional and noisy speech data using learned voice segregation and Speech VGG
Oct 23, 2022



Speech signals are subjected to more acoustic interference and emotional factors than other signals. Noisy emotion-riddled speech data is a challenge for real-time speech processing applications. It is essential to find an effective way to segregate the dominant signal from other external influences. An ideal system should have the capacity to accurately recognize required auditory events from a complex scene taken in an unfavorable situation. This paper proposes a novel approach to speaker identification in unfavorable conditions such as emotion and interference using a pre-trained Deep Neural Network mask and speech VGG. The proposed model obtained superior performance over the recent literature in English and Arabic emotional speech data and reported an average speaker identification rate of 85.2\%, 87.0\%, and 86.6\% using the Ryerson audio-visual dataset (RAVDESS), speech under simulated and actual stress (SUSAS) dataset and Emirati-accented Speech dataset (ESD) respectively.
Person Monitoring by Full Body Tracking in Uniform Crowd Environment
Sep 02, 2022

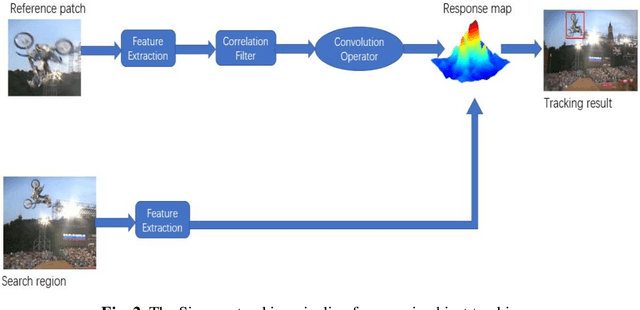
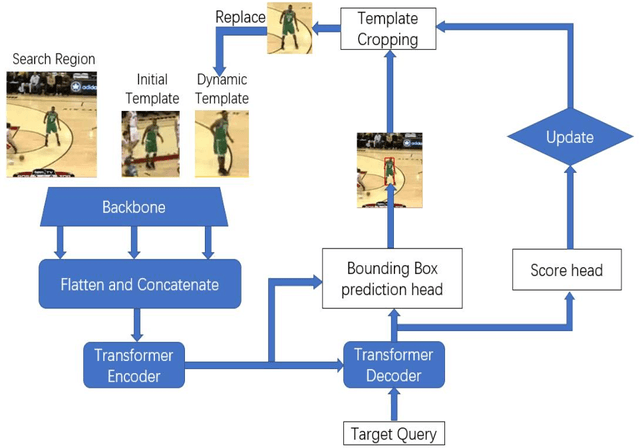
Full body trackers are utilized for surveillance and security purposes, such as person-tracking robots. In the Middle East, uniform crowd environments are the norm which challenges state-of-the-art trackers. Despite tremendous improvements in tracker technology documented in the past literature, these trackers have not been trained using a dataset that captures these environments. In this work, we develop an annotated dataset with one specific target per video in a uniform crowd environment. The dataset was generated in four different scenarios where mainly the target was moving alongside the crowd, sometimes occluding with them, and other times the camera's view of the target is blocked by the crowd for a short period. After the annotations, it was used in evaluating and fine-tuning a state-of-the-art tracker. Our results have shown that the fine-tuned tracker performed better on the evaluation dataset based on two quantitative evaluation metrics, compared to the initial pre-trained tracker.
Graph CNN for Moving Object Detection in Complex Environments from Unseen Videos
Jul 13, 2022



Moving Object Detection (MOD) is a fundamental step for many computer vision applications. MOD becomes very challenging when a video sequence captured from a static or moving camera suffers from the challenges: camouflage, shadow, dynamic backgrounds, and lighting variations, to name a few. Deep learning methods have been successfully applied to address MOD with competitive performance. However, in order to handle the overfitting problem, deep learning methods require a large amount of labeled data which is a laborious task as exhaustive annotations are always not available. Moreover, some MOD deep learning methods show performance degradation in the presence of unseen video sequences because the testing and training splits of the same sequences are involved during the network learning process. In this work, we pose the problem of MOD as a node classification problem using Graph Convolutional Neural Networks (GCNNs). Our algorithm, dubbed as GraphMOD-Net, encompasses instance segmentation, background initialization, feature extraction, and graph construction. GraphMOD-Net is tested on unseen videos and outperforms state-of-the-art methods in unsupervised, semi-supervised, and supervised learning in several challenges of the Change Detection 2014 (CDNet2014) and UCSD background subtraction datasets.
Robot Person Following in Uniform Crowd Environment
May 21, 2022



Person-tracking robots have many applications, such as in security, elderly care, and socializing robots. Such a task is particularly challenging when the person is moving in a Uniform crowd. Also, despite significant progress of trackers reported in the literature, state-of-the-art trackers have hardly addressed person following in such scenarios. In this work, we focus on improving the perceptivity of a robot for a person following task by developing a robust and real-time applicable object tracker. We present a new robot person tracking system with a new RGB-D tracker, Deep Tracking with RGB-D (DTRD) that is resilient to tricky challenges introduced by the uniform crowd environment. Our tracker utilizes transformer encoder-decoder architecture with RGB and depth information to discriminate the target person from similar distractors. A substantial amount of comprehensive experiments and results demonstrate that our tracker has higher performance in two quantitative evaluation metrics and confirms its superiority over other SOTA trackers.