 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnjith George
Second Edition FRCSyn Challenge at CVPR 2024: Face Recognition Challenge in the Era of Synthetic Data
Apr 16, 2024
Synthetic data is gaining increasing relevance for training machine learning models. This is mainly motivated due to several factors such as the lack of real data and intra-class variability, time and errors produced in manual labeling, and in some cases privacy concerns, among others. This paper presents an overview of the 2nd edition of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at CVPR 2024. FRCSyn aims to investigate the use of synthetic data in face recognition to address current technological limitations, including data privacy concerns, demographic biases, generalization to novel scenarios, and performance constraints in challenging situations such as aging, pose variations, and occlusions. Unlike the 1st edition, in which synthetic data from DCFace and GANDiffFace methods was only allowed to train face recognition systems, in this 2nd edition we propose new sub-tasks that allow participants to explore novel face generative methods. The outcomes of the 2nd FRCSyn Challenge, along with the proposed experimental protocol and benchmarking contribute significantly to the application of synthetic data to face recognition.
* arXiv admin note: text overlap with arXiv:2311.10476
SDFR: Synthetic Data for Face Recognition Competition
Apr 09, 2024Large-scale face recognition datasets are collected by crawling the Internet and without individuals' consent, raising legal, ethical, and privacy concerns. With the recent advances in generative models, recently several works proposed generating synthetic face recognition datasets to mitigate concerns in web-crawled face recognition datasets. This paper presents the summary of the Synthetic Data for Face Recognition (SDFR) Competition held in conjunction with the 18th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2024) and established to investigate the use of synthetic data for training face recognition models. The SDFR competition was split into two tasks, allowing participants to train face recognition systems using new synthetic datasets and/or existing ones. In the first task, the face recognition backbone was fixed and the dataset size was limited, while the second task provided almost complete freedom on the model backbone, the dataset, and the training pipeline. The submitted models were trained on existing and also new synthetic datasets and used clever methods to improve training with synthetic data. The submissions were evaluated and ranked on a diverse set of seven benchmarking datasets. The paper gives an overview of the submitted face recognition models and reports achieved performance compared to baseline models trained on real and synthetic datasets. Furthermore, the evaluation of submissions is extended to bias assessment across different demography groups. Lastly, an outlook on the current state of the research in training face recognition models using synthetic data is presented, and existing problems as well as potential future directions are also discussed.
Model Pairing Using Embedding Translation for Backdoor Attack Detection on Open-Set Classification Tasks
Feb 28, 2024Backdoor attacks allow an attacker to embed a specific vulnerability in a machine learning algorithm, activated when an attacker-chosen pattern is presented, causing a specific misprediction. The need to identify backdoors in biometric scenarios has led us to propose a novel technique with different trade-offs. In this paper we propose to use model pairs on open-set classification tasks for detecting backdoors. Using a simple linear operation to project embeddings from a probe model's embedding space to a reference model's embedding space, we can compare both embeddings and compute a similarity score. We show that this score, can be an indicator for the presence of a backdoor despite models being of different architectures, having been trained independently and on different datasets. Additionally, we show that backdoors can be detected even when both models are backdoored. The source code is made available for reproducibility purposes.
FRCSyn Challenge at WACV 2024:Face Recognition Challenge in the Era of Synthetic Data
Nov 17, 2023Despite the widespread adoption of face recognition technology around the world, and its remarkable performance on current benchmarks, there are still several challenges that must be covered in more detail. This paper offers an overview of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at WACV 2024. This is the first international challenge aiming to explore the use of synthetic data in face recognition to address existing limitations in the technology. Specifically, the FRCSyn Challenge targets concerns related to data privacy issues, demographic biases, generalization to unseen scenarios, and performance limitations in challenging scenarios, including significant age disparities between enrollment and testing, pose variations, and occlusions. The results achieved in the FRCSyn Challenge, together with the proposed benchmark, contribute significantly to the application of synthetic data to improve face recognition technology.
SynthDistill: Face Recognition with Knowledge Distillation from Synthetic Data
Aug 28, 2023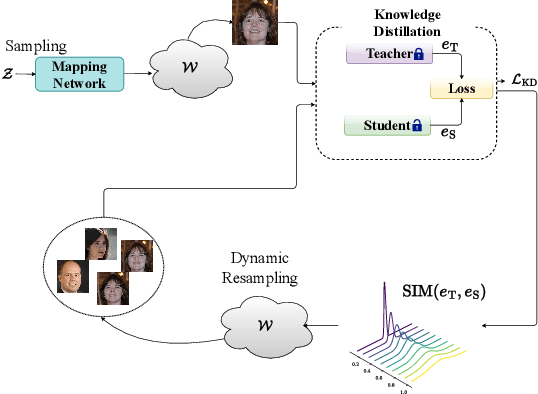
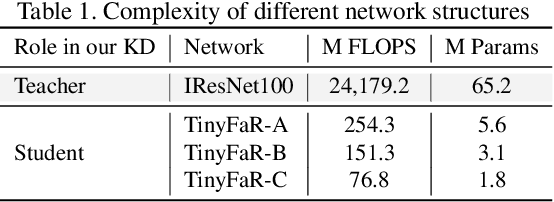
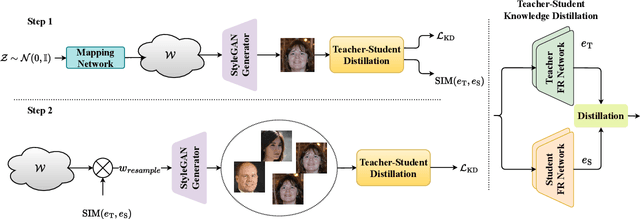
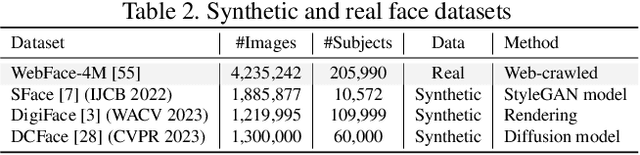
State-of-the-art face recognition networks are often computationally expensive and cannot be used for mobile applications. Training lightweight face recognition models also requires large identity-labeled datasets. Meanwhile, there are privacy and ethical concerns with collecting and using large face recognition datasets. While generating synthetic datasets for training face recognition models is an alternative option, it is challenging to generate synthetic data with sufficient intra-class variations. In addition, there is still a considerable gap between the performance of models trained on real and synthetic data. In this paper, we propose a new framework (named SynthDistill) to train lightweight face recognition models by distilling the knowledge of a pretrained teacher face recognition model using synthetic data. We use a pretrained face generator network to generate synthetic face images and use the synthesized images to learn a lightweight student network. We use synthetic face images without identity labels, mitigating the problems in the intra-class variation generation of synthetic datasets. Instead, we propose a novel dynamic sampling strategy from the intermediate latent space of the face generator network to include new variations of the challenging images while further exploring new face images in the training batch. The results on five different face recognition datasets demonstrate the superiority of our lightweight model compared to models trained on previous synthetic datasets, achieving a verification accuracy of 99.52% on the LFW dataset with a lightweight network. The results also show that our proposed framework significantly reduces the gap between training with real and synthetic data. The source code for replicating the experiments is publicly released.
EFaR 2023: Efficient Face Recognition Competition
Aug 08, 2023
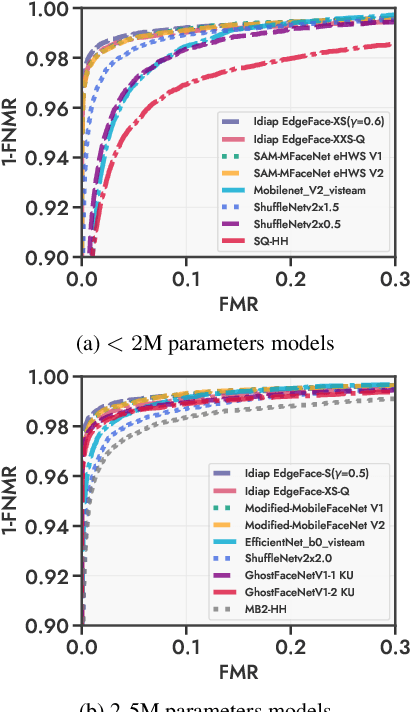
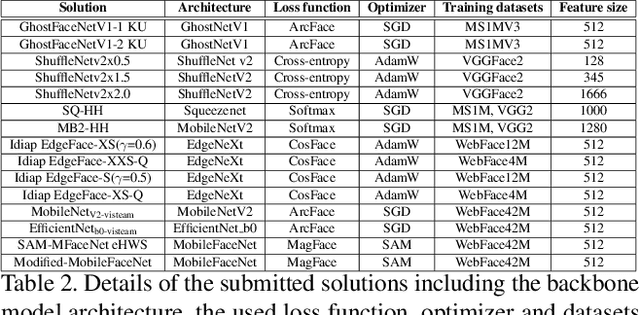
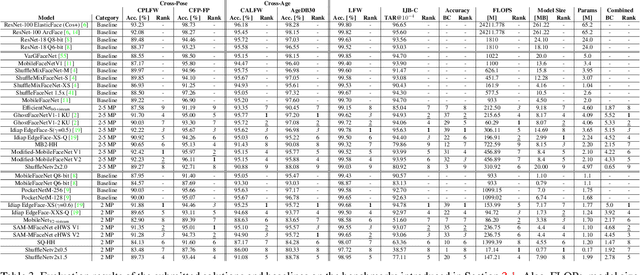
This paper presents the summary of the Efficient Face Recognition Competition (EFaR) held at the 2023 International Joint Conference on Biometrics (IJCB 2023). The competition received 17 submissions from 6 different teams. To drive further development of efficient face recognition models, the submitted solutions are ranked based on a weighted score of the achieved verification accuracies on a diverse set of benchmarks, as well as the deployability given by the number of floating-point operations and model size. The evaluation of submissions is extended to bias, cross-quality, and large-scale recognition benchmarks. Overall, the paper gives an overview of the achieved performance values of the submitted solutions as well as a diverse set of baselines. The submitted solutions use small, efficient network architectures to reduce the computational cost, some solutions apply model quantization. An outlook on possible techniques that are underrepresented in current solutions is given as well.
Bridging the Gap: Heterogeneous Face Recognition with Conditional Adaptive Instance Modulation
Jul 13, 2023
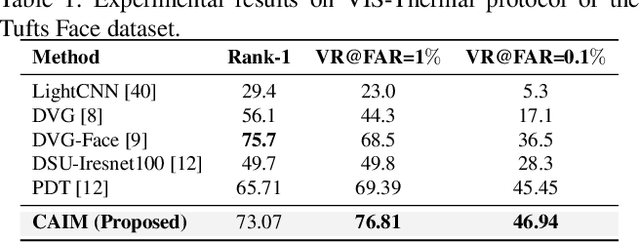
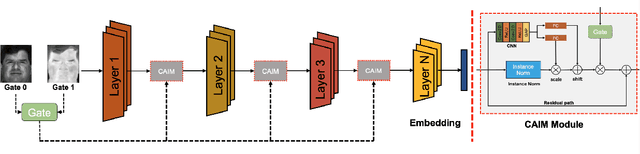
Heterogeneous Face Recognition (HFR) aims to match face images across different domains, such as thermal and visible spectra, expanding the applicability of Face Recognition (FR) systems to challenging scenarios. However, the domain gap and limited availability of large-scale datasets in the target domain make training robust and invariant HFR models from scratch difficult. In this work, we treat different modalities as distinct styles and propose a framework to adapt feature maps, bridging the domain gap. We introduce a novel Conditional Adaptive Instance Modulation (CAIM) module that can be integrated into pre-trained FR networks, transforming them into HFR networks. The CAIM block modulates intermediate feature maps, to adapt the style of the target modality effectively bridging the domain gap. Our proposed method allows for end-to-end training with a minimal number of paired samples. We extensively evaluate our approach on multiple challenging benchmarks, demonstrating superior performance compared to state-of-the-art methods. The source code and protocols for reproducing the findings will be made publicly available.
EdgeFace: Efficient Face Recognition Model for Edge Devices
Jul 04, 2023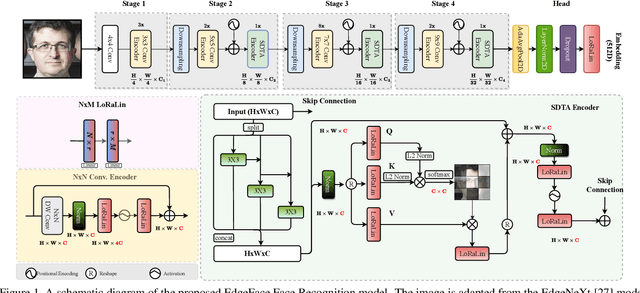
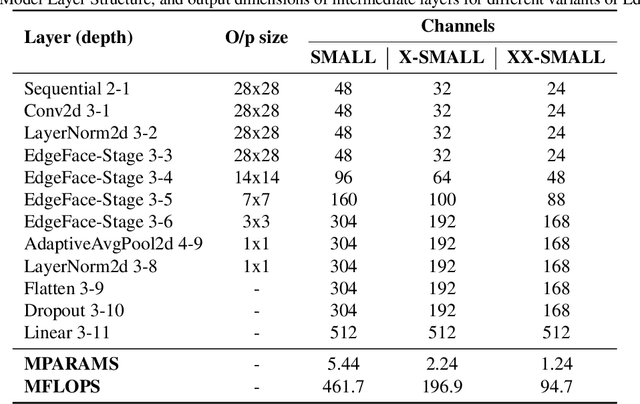

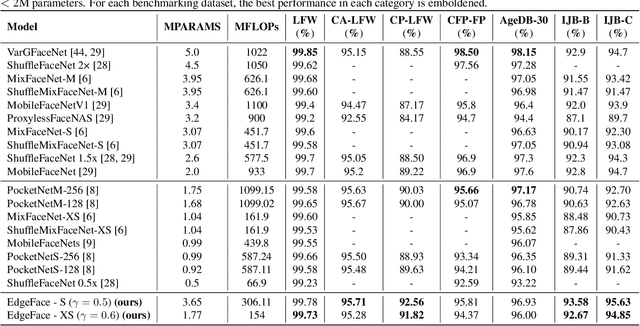
In this paper, we present EdgeFace, a lightweight and efficient face recognition network inspired by the hybrid architecture of EdgeNeXt. By effectively combining the strengths of both CNN and Transformer models, and a low rank linear layer, EdgeFace achieves excellent face recognition performance optimized for edge devices. The proposed EdgeFace network not only maintains low computational costs and compact storage, but also achieves high face recognition accuracy, making it suitable for deployment on edge devices. Extensive experiments on challenging benchmark face datasets demonstrate the effectiveness and efficiency of EdgeFace in comparison to state-of-the-art lightweight models and deep face recognition models. Our EdgeFace model with 1.77M parameters achieves state of the art results on LFW (99.73%), IJB-B (92.67%), and IJB-C (94.85%), outperforming other efficient models with larger computational complexities. The code to replicate the experiments will be made available publicly.
Prepended Domain Transformer: Heterogeneous Face Recognition without Bells and Whistles
Oct 12, 2022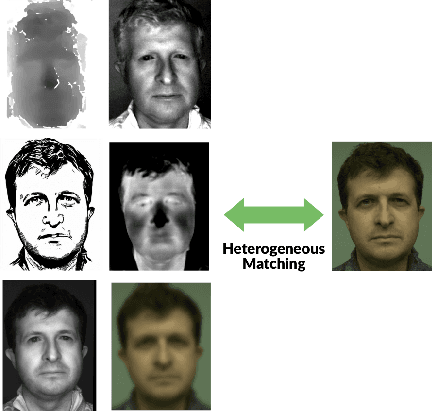
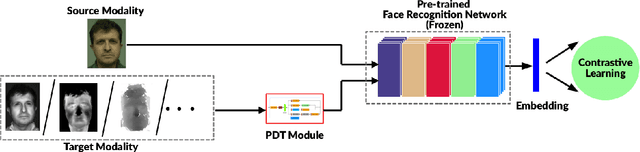
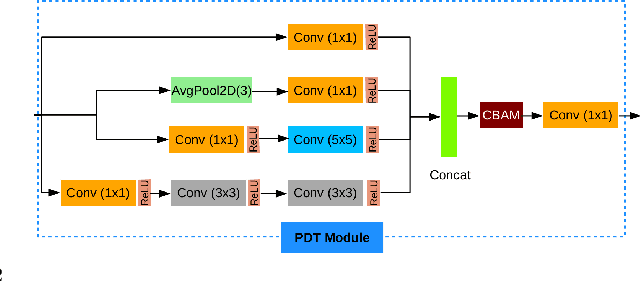

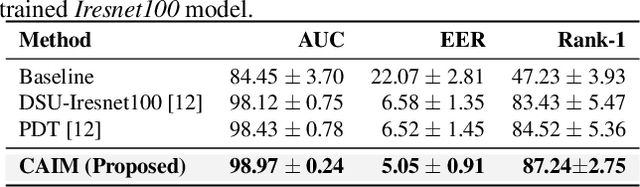
Heterogeneous Face Recognition (HFR) refers to matching face images captured in different domains, such as thermal to visible images (VIS), sketches to visible images, near-infrared to visible, and so on. This is particularly useful in matching visible spectrum images to images captured from other modalities. Though highly useful, HFR is challenging because of the domain gap between the source and target domain. Often, large-scale paired heterogeneous face image datasets are absent, preventing training models specifically for the heterogeneous task. In this work, we propose a surprisingly simple, yet, very effective method for matching face images across different sensing modalities. The core idea of the proposed approach is to add a novel neural network block called Prepended Domain Transformer (PDT) in front of a pre-trained face recognition (FR) model to address the domain gap. Retraining this new block with few paired samples in a contrastive learning setup was enough to achieve state-of-the-art performance in many HFR benchmarks. The PDT blocks can be retrained for several source-target combinations using the proposed general framework. The proposed approach is architecture agnostic, meaning they can be added to any pre-trained FR models. Further, the approach is modular and the new block can be trained with a minimal set of paired samples, making it much easier for practical deployment. The source code and protocols will be made available publicly.
A Comprehensive Evaluation on Multi-channel Biometric Face Presentation Attack Detection
Feb 21, 2022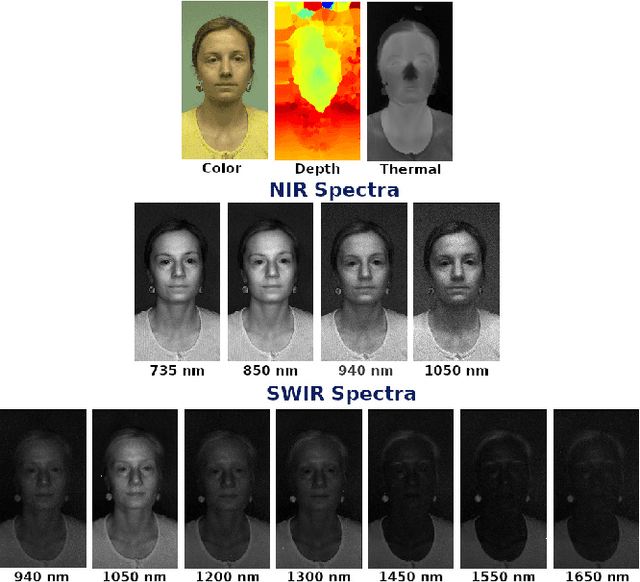

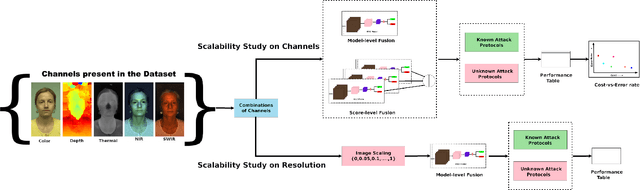
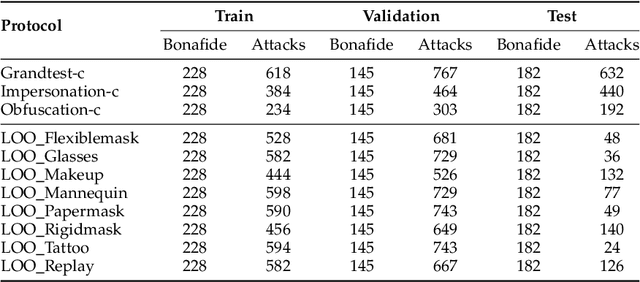
The vulnerability against presentation attacks is a crucial problem undermining the wide-deployment of face recognition systems. Though presentation attack detection (PAD) systems try to address this problem, the lack of generalization and robustness continues to be a major concern. Several works have shown that using multi-channel PAD systems could alleviate this vulnerability and result in more robust systems. However, there is a wide selection of channels available for a PAD system such as RGB, Near Infrared, Shortwave Infrared, Depth, and Thermal sensors. Having a lot of sensors increases the cost of the system, and therefore an understanding of the performance of different sensors against a wide variety of attacks is necessary while selecting the modalities. In this work, we perform a comprehensive study to understand the effectiveness of various imaging modalities for PAD. The studies are performed on a multi-channel PAD dataset, collected with 14 different sensing modalities considering a wide range of 2D, 3D, and partial attacks. We used the multi-channel convolutional network-based architecture, which uses pixel-wise binary supervision. The model has been evaluated with different combinations of channels, and different image qualities on a variety of challenging known and unknown attack protocols. The results reveal interesting trends and can act as pointers for sensor selection for safety-critical presentation attack detection systems. The source codes and protocols to reproduce the results are made available publicly making it possible to extend this work to other architectures.