 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuido Borghi
ONOT: a High-Quality ICAO-compliant Synthetic Mugshot Dataset
Apr 17, 2024
Nowadays, state-of-the-art AI-based generative models represent a viable solution to overcome privacy issues and biases in the collection of datasets containing personal information, such as faces. Following this intuition, in this paper we introduce ONOT, a synthetic dataset specifically focused on the generation of high-quality faces in adherence to the requirements of the ISO/IEC 39794-5 standards that, following the guidelines of the International Civil Aviation Organization (ICAO), defines the interchange formats of face images in electronic Machine-Readable Travel Documents (eMRTD). The strictly controlled and varied mugshot images included in ONOT are useful in research fields related to the analysis of face images in eMRTD, such as Morphing Attack Detection and Face Quality Assessment. The dataset is publicly released, in combination with the generation procedure details in order to improve the reproducibility and enable future extensions.
Adversarial Identity Injection for Semantic Face Image Synthesis
Apr 16, 2024Nowadays, deep learning models have reached incredible performance in the task of image generation. Plenty of literature works address the task of face generation and editing, with human and automatic systems that struggle to distinguish what's real from generated. Whereas most systems reached excellent visual generation quality, they still face difficulties in preserving the identity of the starting input subject. Among all the explored techniques, Semantic Image Synthesis (SIS) methods, whose goal is to generate an image conditioned on a semantic segmentation mask, are the most promising, even though preserving the perceived identity of the input subject is not their main concern. Therefore, in this paper, we investigate the problem of identity preservation in face image generation and present an SIS architecture that exploits a cross-attention mechanism to merge identity, style, and semantic features to generate faces whose identities are as similar as possible to the input ones. Experimental results reveal that the proposed method is not only suitable for preserving the identity but is also effective in the face recognition adversarial attack, i.e. hiding a second identity in the generated faces.
Dealing with Subject Similarity in Differential Morphing Attack Detection
Apr 11, 2024The advent of morphing attacks has posed significant security concerns for automated Face Recognition systems, raising the pressing need for robust and effective Morphing Attack Detection (MAD) methods able to effectively address this issue. In this paper, we focus on Differential MAD (D-MAD), where a trusted live capture, usually representing the criminal, is compared with the document image to classify it as morphed or bona fide. We show these approaches based on identity features are effective when the morphed image and the live one are sufficiently diverse; unfortunately, the effectiveness is significantly reduced when the same approaches are applied to look-alike subjects or in all those cases when the similarity between the two compared images is high (e.g. comparison between the morphed image and the accomplice). Therefore, in this paper, we propose ACIdA, a modular D-MAD system, consisting of a module for the attempt type classification, and two modules for the identity and artifacts analysis on input images. Successfully addressing this task would allow broadening the D-MAD applications including, for instance, the document enrollment stage, which currently relies entirely on human evaluation, thus limiting the possibility of releasing ID documents with manipulated images, as well as the automated gates to detect both accomplices and criminals. An extensive cross-dataset experimental evaluation conducted on the introduced scenario shows that ACIdA achieves state-of-the-art results, outperforming literature competitors, while maintaining good performance in traditional D-MAD benchmarks.
V-MAD: Video-based Morphing Attack Detection in Operational Scenarios
Apr 10, 2024In response to the rising threat of the face morphing attack, this paper introduces and explores the potential of Video-based Morphing Attack Detection (V-MAD) systems in real-world operational scenarios. While current morphing attack detection methods primarily focus on a single or a pair of images, V-MAD is based on video sequences, exploiting the video streams often acquired by face verification tools available, for instance, at airport gates. Through this study, we show for the first time the advantages that the availability of multiple probe frames can bring to the morphing attack detection task, especially in scenarios where the quality of probe images is varied and might be affected, for instance, by pose or illumination variations. Experimental results on a real operational database demonstrate that video sequences represent valuable information for increasing the robustness and performance of morphing attack detection systems.
SDFR: Synthetic Data for Face Recognition Competition
Apr 09, 2024Large-scale face recognition datasets are collected by crawling the Internet and without individuals' consent, raising legal, ethical, and privacy concerns. With the recent advances in generative models, recently several works proposed generating synthetic face recognition datasets to mitigate concerns in web-crawled face recognition datasets. This paper presents the summary of the Synthetic Data for Face Recognition (SDFR) Competition held in conjunction with the 18th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2024) and established to investigate the use of synthetic data for training face recognition models. The SDFR competition was split into two tasks, allowing participants to train face recognition systems using new synthetic datasets and/or existing ones. In the first task, the face recognition backbone was fixed and the dataset size was limited, while the second task provided almost complete freedom on the model backbone, the dataset, and the training pipeline. The submitted models were trained on existing and also new synthetic datasets and used clever methods to improve training with synthetic data. The submissions were evaluated and ranked on a diverse set of seven benchmarking datasets. The paper gives an overview of the submitted face recognition models and reports achieved performance compared to baseline models trained on real and synthetic datasets. Furthermore, the evaluation of submissions is extended to bias assessment across different demography groups. Lastly, an outlook on the current state of the research in training face recognition models using synthetic data is presented, and existing problems as well as potential future directions are also discussed.
Enabling On-device Continual Learning with Binary Neural Networks
Jan 18, 2024On-device learning remains a formidable challenge, especially when dealing with resource-constrained devices that have limited computational capabilities. This challenge is primarily rooted in two key issues: first, the memory available on embedded devices is typically insufficient to accommodate the memory-intensive back-propagation algorithm, which often relies on floating-point precision. Second, the development of learning algorithms on models with extreme quantization levels, such as Binary Neural Networks (BNNs), is critical due to the drastic reduction in bit representation. In this study, we propose a solution that combines recent advancements in the field of Continual Learning (CL) and Binary Neural Networks to enable on-device training while maintaining competitive performance. Specifically, our approach leverages binary latent replay (LR) activations and a novel quantization scheme that significantly reduces the number of bits required for gradient computation. The experimental validation demonstrates a significant accuracy improvement in combination with a noticeable reduction in memory requirement, confirming the suitability of our approach in expanding the practical applications of deep learning in real-world scenarios.
FRCSyn Challenge at WACV 2024:Face Recognition Challenge in the Era of Synthetic Data
Nov 17, 2023Despite the widespread adoption of face recognition technology around the world, and its remarkable performance on current benchmarks, there are still several challenges that must be covered in more detail. This paper offers an overview of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn) organized at WACV 2024. This is the first international challenge aiming to explore the use of synthetic data in face recognition to address existing limitations in the technology. Specifically, the FRCSyn Challenge targets concerns related to data privacy issues, demographic biases, generalization to unseen scenarios, and performance limitations in challenging scenarios, including significant age disparities between enrollment and testing, pose variations, and occlusions. The results achieved in the FRCSyn Challenge, together with the proposed benchmark, contribute significantly to the application of synthetic data to improve face recognition technology.
Robot Pose Nowcasting: Forecast the Future to Improve the Present
Aug 24, 2023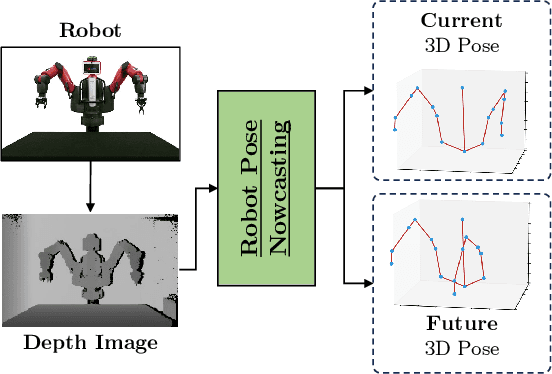
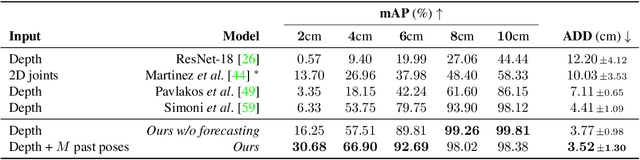
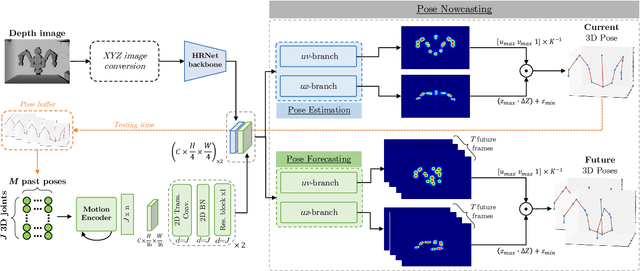
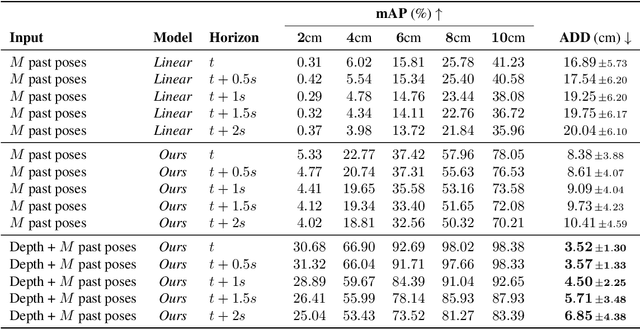
In recent years, the effective and safe collaboration between humans and machines has gained significant importance, particularly in the Industry 4.0 scenario. A critical prerequisite for realizing this collaborative paradigm is precisely understanding the robot's 3D pose within its environment. Therefore, in this paper, we introduce a novel vision-based system leveraging depth data to accurately establish the 3D locations of robotic joints. Specifically, we prove the ability of the proposed system to enhance its current pose estimation accuracy by jointly learning to forecast future poses. Indeed, we introduce the concept of Pose Nowcasting, denoting the capability of a system to exploit the learned knowledge of the future to improve the estimation of the present. The experimental evaluation is conducted on two different datasets, providing state-of-the-art and real-time performance and confirming the validity of the proposed method on both the robotic and human scenarios.
Detecting Morphing Attacks via Continual Incremental Training
Jul 27, 2023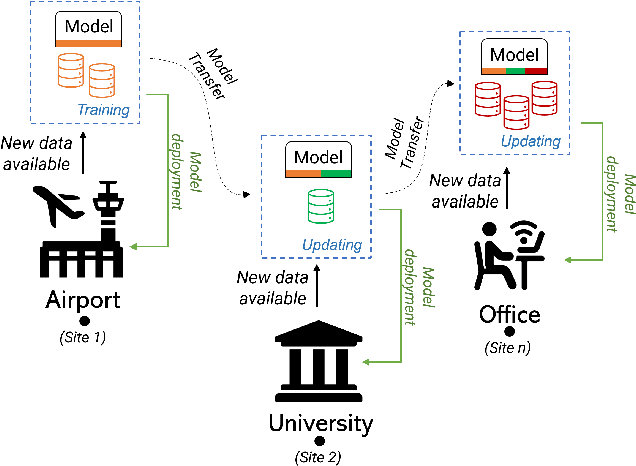
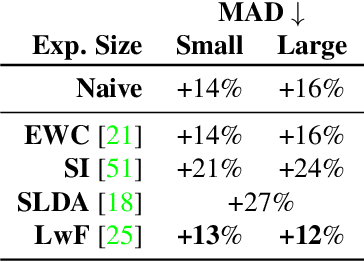


Scenarios in which restrictions in data transfer and storage limit the possibility to compose a single dataset -- also exploiting different data sources -- to perform a batch-based training procedure, make the development of robust models particularly challenging. We hypothesize that the recent Continual Learning (CL) paradigm may represent an effective solution to enable incremental training, even through multiple sites. Indeed, a basic assumption of CL is that once a model has been trained, old data can no longer be used in successive training iterations and in principle can be deleted. Therefore, in this paper, we investigate the performance of different Continual Learning methods in this scenario, simulating a learning model that is updated every time a new chunk of data, even of variable size, is available. Experimental results reveal that a particular CL method, namely Learning without Forgetting (LwF), is one of the best-performing algorithms. Then, we investigate its usage and parametrization in Morphing Attack Detection and Object Classification tasks, specifically with respect to the amount of new training data that became available.
On the challenges to learn from Natural Data Streams
Jan 09, 2023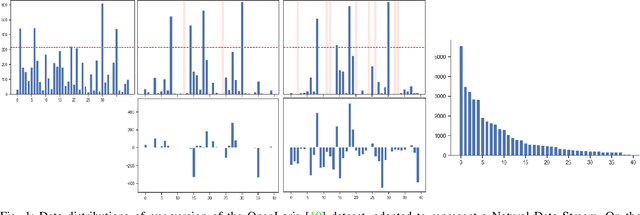
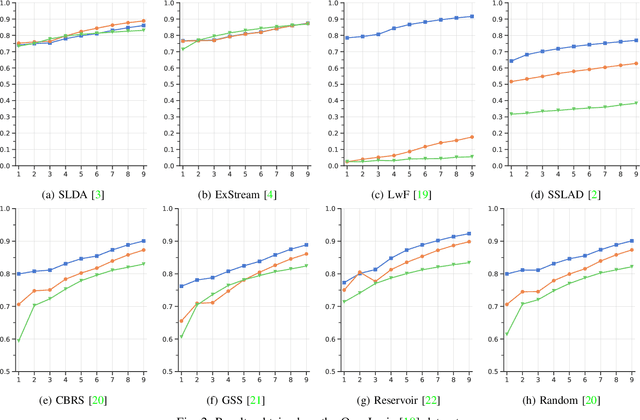
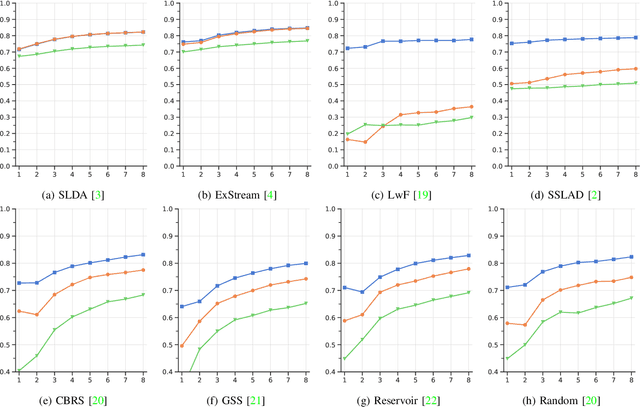
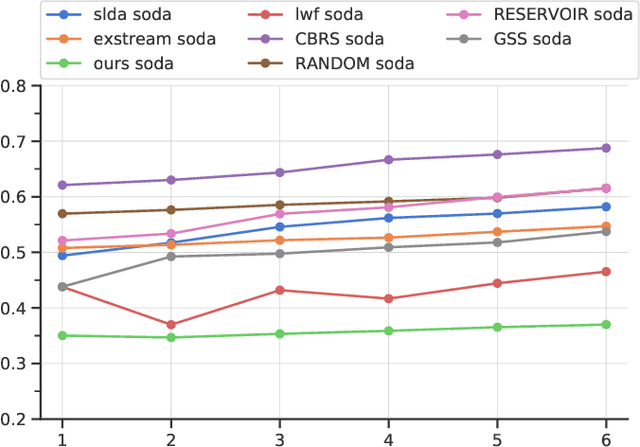
In real-world contexts, sometimes data are available in form of Natural Data Streams, i.e. data characterized by a streaming nature, unbalanced distribution, data drift over a long time frame and strong correlation of samples in short time ranges. Moreover, a clear separation between the traditional training and deployment phases is usually lacking. This data organization and fruition represents an interesting and challenging scenario for both traditional Machine and Deep Learning algorithms and incremental learning agents, i.e. agents that have the ability to incrementally improve their knowledge through the past experience. In this paper, we investigate the classification performance of a variety of algorithms that belong to various research field, i.e. Continual, Streaming and Online Learning, that receives as training input Natural Data Streams. The experimental validation is carried out on three different datasets, expressly organized to replicate this challenging setting.