 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenis Gudovskiy
VeCAF: VLM-empowered Collaborative Active Finetuning with Training Objective Awareness
Jan 15, 2024
Finetuning a pretrained vision model (PVM) is a common technique for learning downstream vision tasks. The conventional finetuning process with the randomly sampled data points results in diminished training efficiency. To address this drawback, we propose a novel approach, VLM-empowered Collaborative Active Finetuning (VeCAF). VeCAF optimizes a parametric data selection model by incorporating the training objective of the model being tuned. Effectively, this guides the PVM towards the performance goal with improved data and computational efficiency. As vision-language models (VLMs) have achieved significant advancements by establishing a robust connection between image and language domains, we exploit the inherent semantic richness of the text embedding space and utilize text embedding of pretrained VLM models to augment PVM image features for better data selection and finetuning. Furthermore, the flexibility of text-domain augmentation gives VeCAF a unique ability to handle out-of-distribution scenarios without external augmented data. Extensive experiments show the leading performance and high efficiency of VeCAF that is superior to baselines in both in-distribution and out-of-distribution image classification tasks. On ImageNet, VeCAF needs up to 3.3x less training batches to reach the target performance compared to full finetuning and achieves 2.8% accuracy improvement over SOTA methods with the same number of batches.
Efficient Deweather Mixture-of-Experts with Uncertainty-aware Feature-wise Linear Modulation
Dec 27, 2023The Mixture-of-Experts (MoE) approach has demonstrated outstanding scalability in multi-task learning including low-level upstream tasks such as concurrent removal of multiple adverse weather effects. However, the conventional MoE architecture with parallel Feed Forward Network (FFN) experts leads to significant parameter and computational overheads that hinder its efficient deployment. In addition, the naive MoE linear router is suboptimal in assigning task-specific features to multiple experts which limits its further scalability. In this work, we propose an efficient MoE architecture with weight sharing across the experts. Inspired by the idea of linear feature modulation (FM), our architecture implicitly instantiates multiple experts via learnable activation modulations on a single shared expert block. The proposed Feature Modulated Expert (FME) serves as a building block for the novel Mixture-of-Feature-Modulation-Experts (MoFME) architecture, which can scale up the number of experts with low overhead. We further propose an Uncertainty-aware Router (UaR) to assign task-specific features to different FM modules with well-calibrated weights. This enables MoFME to effectively learn diverse expert functions for multiple tasks. The conducted experiments on the multi-deweather task show that our MoFME outperforms the baselines in the image restoration quality by 0.1-0.2 dB and achieves SOTA-compatible performance while saving more than 72% of parameters and 39% inference time over the conventional MoE counterpart. Experiments on the downstream segmentation and classification tasks further demonstrate the generalizability of MoFME to real open-world applications.
Concurrent Misclassification and Out-of-Distribution Detection for Semantic Segmentation via Energy-Based Normalizing Flow
May 16, 2023



Recent semantic segmentation models accurately classify test-time examples that are similar to a training dataset distribution. However, their discriminative closed-set approach is not robust in practical data setups with distributional shifts and out-of-distribution (OOD) classes. As a result, the predicted probabilities can be very imprecise when used as confidence scores at test time. To address this, we propose a generative model for concurrent in-distribution misclassification (IDM) and OOD detection that relies on a normalizing flow framework. The proposed flow-based detector with an energy-based inputs (FlowEneDet) can extend previously deployed segmentation models without their time-consuming retraining. Our FlowEneDet results in a low-complexity architecture with marginal increase in the memory footprint. FlowEneDet achieves promising results on Cityscapes, Cityscapes-C, FishyScapes and SegmentMeIfYouCan benchmarks in IDM/OOD detection when applied to pretrained DeepLabV3+ and SegFormer semantic segmentation models.
Cross-Domain Object Detection with Mean-Teacher Transformer
May 03, 2022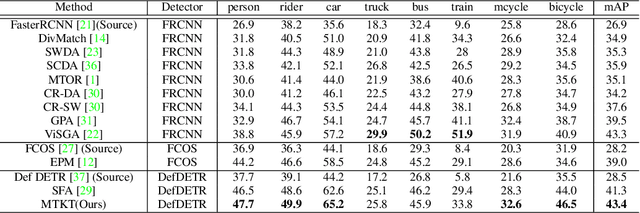
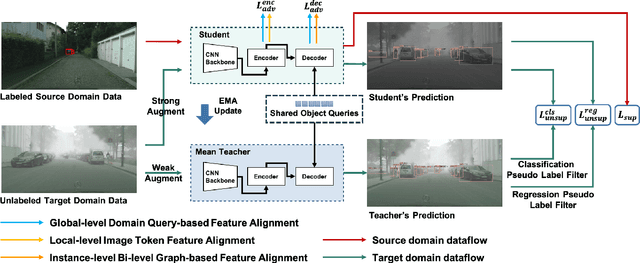
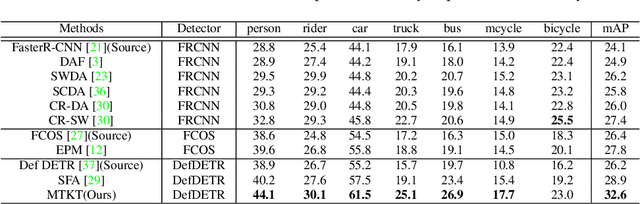
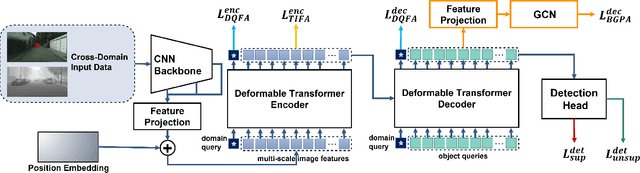
Recently, DEtection TRansformer (DETR), an end-to-end object detection pipeline, has achieved promising performance. However, it requires large-scale labeled data and suffers from domain shift, especially when no labeled data is available in the target domain. To solve this problem, we propose an end-to-end cross-domain detection transformer based on the mean teacher knowledge transfer (MTKT), which transfers knowledge between domains via pseudo labels. To improve the quality of pseudo labels in the target domain, which is a crucial factor for better domain adaptation, we design three levels of source-target feature alignment strategies based on the architecture of the Transformer, including domain query-based feature alignment (DQFA), bi-level-graph-based prototype alignment (BGPA), and token-wise image feature alignment (TIFA). These three levels of feature alignment match the global, local, and instance features between source and target, respectively. With these strategies, more accurate pseudo labels can be obtained, and knowledge can be better transferred from source to target, thus improving the cross-domain capability of the detection transformer. Extensive experiments demonstrate that our proposed method achieves state-of-the-art performance on three domain adaptation scenarios, especially the result of Sim10k to Cityscapes scenario is remarkably improved from 52.6 mAP to 57.9 mAP. Code will be released.
Contrastive Neural Processes for Self-Supervised Learning
Oct 31, 2021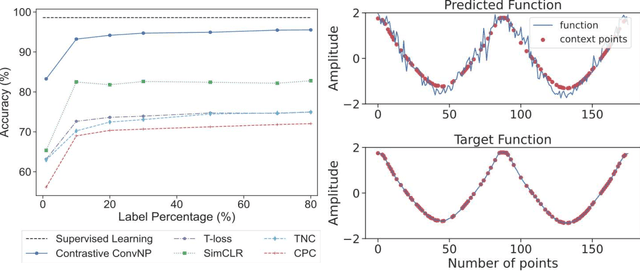
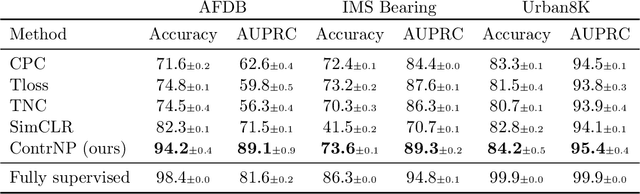
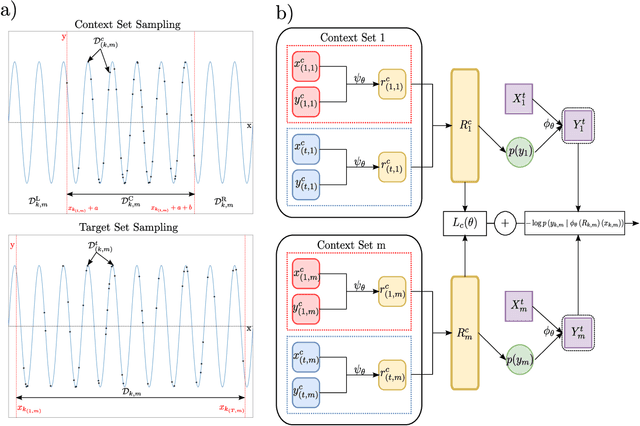
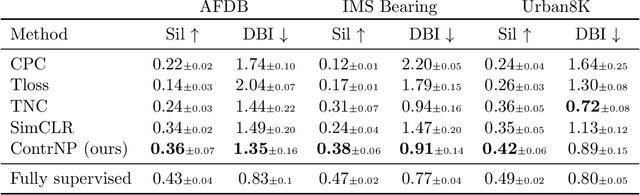
Recent contrastive methods show significant improvement in self-supervised learning in several domains. In particular, contrastive methods are most effective where data augmentation can be easily constructed e.g. in computer vision. However, they are less successful in domains without established data transformations such as time series data. In this paper, we propose a novel self-supervised learning framework that combines contrastive learning with neural processes. It relies on recent advances in neural processes to perform time series forecasting. This allows to generate augmented versions of data by employing a set of various sampling functions and, hence, avoid manually designed augmentations. We extend conventional neural processes and propose a new contrastive loss to learn times series representations in a self-supervised setup. Therefore, unlike previous self-supervised methods, our augmentation pipeline is task-agnostic, enabling our method to perform well across various applications. In particular, a ResNet with a linear classifier trained using our approach is able to outperform state-of-the-art techniques across industrial, medical and audio datasets improving accuracy over 10% in ECG periodic data. We further demonstrate that our self-supervised representations are more efficient in the latent space, improving multiple clustering indexes and that fine-tuning our method on 10% of labels achieves results competitive to fully-supervised learning.
CFLOW-AD: Real-Time Unsupervised Anomaly Detection with Localization via Conditional Normalizing Flows
Jul 27, 2021



Unsupervised anomaly detection with localization has many practical applications when labeling is infeasible and, moreover, when anomaly examples are completely missing in the train data. While recently proposed models for such data setup achieve high accuracy metrics, their complexity is a limiting factor for real-time processing. In this paper, we propose a real-time model and analytically derive its relationship to prior methods. Our CFLOW-AD model is based on a conditional normalizing flow framework adopted for anomaly detection with localization. In particular, CFLOW-AD consists of a discriminatively pretrained encoder followed by a multi-scale generative decoders where the latter explicitly estimate likelihood of the encoded features. Our approach results in a computationally and memory-efficient model: CFLOW-AD is faster and smaller by a factor of 10x than prior state-of-the-art with the same input setting. Our experiments on the MVTec dataset show that CFLOW-AD outperforms previous methods by 0.36% AUROC in detection task, by 1.12% AUROC and 2.5% AUPRO in localization task, respectively. We open-source our code with fully reproducible experiments.
AutoDO: Robust AutoAugment for Biased Data with Label Noise via Scalable Probabilistic Implicit Differentiation
Mar 11, 2021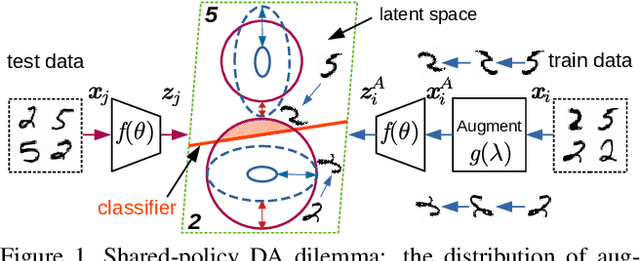


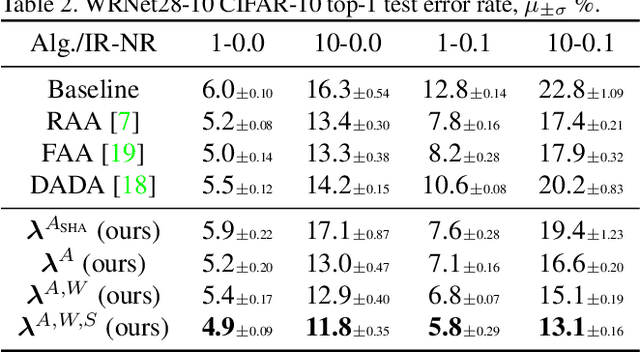
AutoAugment has sparked an interest in automated augmentation methods for deep learning models. These methods estimate image transformation policies for train data that improve generalization to test data. While recent papers evolved in the direction of decreasing policy search complexity, we show that those methods are not robust when applied to biased and noisy data. To overcome these limitations, we reformulate AutoAugment as a generalized automated dataset optimization (AutoDO) task that minimizes the distribution shift between test data and distorted train dataset. In our AutoDO model, we explicitly estimate a set of per-point hyperparameters to flexibly change distribution of train data. In particular, we include hyperparameters for augmentation, loss weights, and soft-labels that are jointly estimated using implicit differentiation. We develop a theoretical probabilistic interpretation of this framework using Fisher information and show that its complexity scales linearly with the dataset size. Our experiments on SVHN, CIFAR-10/100, and ImageNet classification show up to 9.3% improvement for biased datasets with label noise compared to prior methods and, importantly, up to 36.6% gain for underrepresented SVHN classes.
Deep Active Learning for Biased Datasets via Fisher Kernel Self-Supervision
Mar 01, 2020



Active learning (AL) aims to minimize labeling efforts for data-demanding deep neural networks (DNNs) by selecting the most representative data points for annotation. However, currently used methods are ill-equipped to deal with biased data. The main motivation of this paper is to consider a realistic setting for pool-based semi-supervised AL, where the unlabeled collection of train data is biased. We theoretically derive an optimal acquisition function for AL in this setting. It can be formulated as distribution shift minimization between unlabeled train data and weakly-labeled validation dataset. To implement such acquisition function, we propose a low-complexity method for feature density matching using self-supervised Fisher kernel (FK) as well as several novel pseudo-label estimators. Our FK-based method outperforms state-of-the-art methods on MNIST, SVHN, and ImageNet classification while requiring only 1/10th of processing. The conducted experiments show at least 40% drop in labeling efforts for the biased class-imbalanced data compared to existing methods.
Smart Home Appliances: Chat with Your Fridge
Dec 19, 2019



Current home appliances are capable to execute a limited number of voice commands such as turning devices on or off, adjusting music volume or light conditions. Recent progress in machine reasoning gives an opportunity to develop new types of conversational user interfaces for home appliances. In this paper, we apply state-of-the-art visual reasoning model and demonstrate that it is feasible to ask a smart fridge about its contents and various properties of the food with close-to-natural conversation experience. Our visual reasoning model answers user questions about existence, count, category and freshness of each product by analyzing photos made by the image sensor inside the smart fridge. Users may chat with their fridge using off-the-shelf phone messenger while being away from home, for example, when shopping in the supermarket. We generate a visually realistic synthetic dataset to train machine learning reasoning model that achieves 95% answer accuracy on test data. We present the results of initial user tests and discuss how we modify distribution of generated questions for model training based on human-in-the-loop guidance. We open source code for the whole system including dataset generation, reasoning model and demonstration scripts.
Explain to Fix: A Framework to Interpret and Correct DNN Object Detector Predictions
Nov 19, 2018


Explaining predictions of deep neural networks (DNNs) is an important and nontrivial task. In this paper, we propose a practical approach to interpret decisions made by a DNN object detector that has fidelity comparable to state-of-the-art methods and sufficient computational efficiency to process large datasets. Our method relies on recent theory and approximates Shapley feature importance values. We qualitatively and quantitatively show that the proposed explanation method can be used to find image features which cause failures in DNN object detection. The developed software tool combined into the "Explain to Fix" (E2X) framework has a factor of 10 higher computational efficiency than prior methods and can be used for cluster processing using graphics processing units (GPUs). Lastly, we propose a potential extension of the E2X framework where the discovered missing features can be added into training dataset to overcome failures after model retraining.