 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXingqun Qi
Weakly-Supervised Emotion Transition Learning for Diverse 3D Co-speech Gesture Generation
Nov 29, 2023
Generating vivid and emotional 3D co-speech gestures is crucial for virtual avatar animation in human-machine interaction applications. While the existing methods enable generating the gestures to follow a single emotion label, they overlook that long gesture sequence modeling with emotion transition is more practical in real scenes. In addition, the lack of large-scale available datasets with emotional transition speech and corresponding 3D human gestures also limits the addressing of this task. To fulfill this goal, we first incorporate the ChatGPT-4 and an audio inpainting approach to construct the high-fidelity emotion transition human speeches. Considering obtaining the realistic 3D pose annotations corresponding to the dynamically inpainted emotion transition audio is extremely difficult, we propose a novel weakly supervised training strategy to encourage authority gesture transitions. Specifically, to enhance the coordination of transition gestures w.r.t different emotional ones, we model the temporal association representation between two different emotional gesture sequences as style guidance and infuse it into the transition generation. We further devise an emotion mixture mechanism that provides weak supervision based on a learnable mixed emotion label for transition gestures. Last, we present a keyframe sampler to supply effective initial posture cues in long sequences, enabling us to generate diverse gestures. Extensive experiments demonstrate that our method outperforms the state-of-the-art models constructed by adapting single emotion-conditioned counterparts on our newly defined emotion transition task and datasets.
Audio-Visual Segmentation by Exploring Cross-Modal Mutual Semantics
Aug 01, 2023

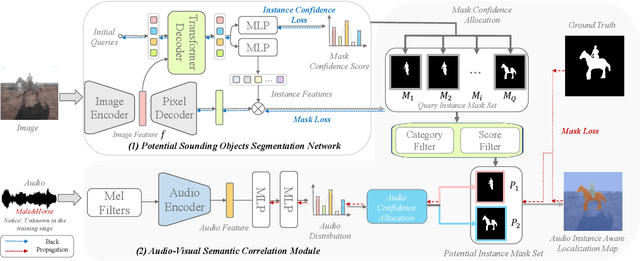

The audio-visual segmentation (AVS) task aims to segment sounding objects from a given video. Existing works mainly focus on fusing audio and visual features of a given video to achieve sounding object masks. However, we observed that prior arts are prone to segment a certain salient object in a video regardless of the audio information. This is because sounding objects are often the most salient ones in the AVS dataset. Thus, current AVS methods might fail to localize genuine sounding objects due to the dataset bias. In this work, we present an audio-visual instance-aware segmentation approach to overcome the dataset bias. In a nutshell, our method first localizes potential sounding objects in a video by an object segmentation network, and then associates the sounding object candidates with the given audio. We notice that an object could be a sounding object in one video but a silent one in another video. This would bring ambiguity in training our object segmentation network as only sounding objects have corresponding segmentation masks. We thus propose a silent object-aware segmentation objective to alleviate the ambiguity. Moreover, since the category information of audio is unknown, especially for multiple sounding sources, we propose to explore the audio-visual semantic correlation and then associate audio with potential objects. Specifically, we attend predicted audio category scores to potential instance masks and these scores will highlight corresponding sounding instances while suppressing inaudible ones. When we enforce the attended instance masks to resemble the ground-truth mask, we are able to establish audio-visual semantics correlation. Experimental results on the AVS benchmarks demonstrate that our method can effectively segment sounding objects without being biased to salient objects.
EmotionGesture: Audio-Driven Diverse Emotional Co-Speech 3D Gesture Generation
May 30, 2023



Generating vivid and diverse 3D co-speech gestures is crucial for various applications in animating virtual avatars. While most existing methods can generate gestures from audio directly, they usually overlook that emotion is one of the key factors of authentic co-speech gesture generation. In this work, we propose EmotionGesture, a novel framework for synthesizing vivid and diverse emotional co-speech 3D gestures from audio. Considering emotion is often entangled with the rhythmic beat in speech audio, we first develop an Emotion-Beat Mining module (EBM) to extract the emotion and audio beat features as well as model their correlation via a transcript-based visual-rhythm alignment. Then, we propose an initial pose based Spatial-Temporal Prompter (STP) to generate future gestures from the given initial poses. STP effectively models the spatial-temporal correlations between the initial poses and the future gestures, thus producing the spatial-temporal coherent pose prompt. Once we obtain pose prompts, emotion, and audio beat features, we will generate 3D co-speech gestures through a transformer architecture. However, considering the poses of existing datasets often contain jittering effects, this would lead to generating unstable gestures. To address this issue, we propose an effective objective function, dubbed Motion-Smooth Loss. Specifically, we model motion offset to compensate for jittering ground-truth by forcing gestures to be smooth. Last, we present an emotion-conditioned VAE to sample emotion features, enabling us to generate diverse emotional results. Extensive experiments demonstrate that our framework outperforms the state-of-the-art, achieving vivid and diverse emotional co-speech 3D gestures.
Diverse 3D Hand Gesture Prediction from Body Dynamics by Bilateral Hand Disentanglement
Mar 21, 2023



Predicting natural and diverse 3D hand gestures from the upper body dynamics is a practical yet challenging task in virtual avatar creation. Previous works usually overlook the asymmetric motions between two hands and generate two hands in a holistic manner, leading to unnatural results. In this work, we introduce a novel bilateral hand disentanglement based two-stage 3D hand generation method to achieve natural and diverse 3D hand prediction from body dynamics. In the first stage, we intend to generate natural hand gestures by two hand-disentanglement branches. Considering the asymmetric gestures and motions of two hands, we introduce a Spatial-Residual Memory (SRM) module to model spatial interaction between the body and each hand by residual learning. To enhance the coordination of two hand motions wrt. body dynamics holistically, we then present a Temporal-Motion Memory (TMM) module. TMM can effectively model the temporal association between body dynamics and two hand motions. The second stage is built upon the insight that 3D hand predictions should be non-deterministic given the sequential body postures. Thus, we further diversify our 3D hand predictions based on the initial output from the stage one. Concretely, we propose a Prototypical-Memory Sampling Strategy (PSS) to generate the non-deterministic hand gestures by gradient-based Markov Chain Monte Carlo (MCMC) sampling. Extensive experiments demonstrate that our method outperforms the state-of-the-art models on the B2H dataset and our newly collected TED Hands dataset. The dataset and code are available at https://github.com/XingqunQi-lab/Diverse-3D-Hand-Gesture-Prediction.
LightVessel: Exploring Lightweight Coronary Artery Vessel Segmentation via Similarity Knowledge Distillation
Nov 02, 2022



In recent years, deep convolution neural networks (DCNNs) have achieved great prospects in coronary artery vessel segmentation. However, it is difficult to deploy complicated models in clinical scenarios since high-performance approaches have excessive parameters and high computation costs. To tackle this problem, we propose \textbf{LightVessel}, a Similarity Knowledge Distillation Framework, for lightweight coronary artery vessel segmentation. Primarily, we propose a Feature-wise Similarity Distillation (FSD) module for semantic-shift modeling. Specifically, we calculate the feature similarity between the symmetric layers from the encoder and decoder. Then the similarity is transferred as knowledge from a cumbersome teacher network to a non-trained lightweight student network. Meanwhile, for encouraging the student model to learn more pixel-wise semantic information, we introduce the Adversarial Similarity Distillation (ASD) module. Concretely, the ASD module aims to construct the spatial adversarial correlation between the annotation and prediction from the teacher and student models, respectively. Through the ASD module, the student model obtains fined-grained subtle edge segmented results of the coronary artery vessel. Extensive experiments conducted on Clinical Coronary Artery Vessel Dataset demonstrate that LightVessel outperforms various knowledge distillation counterparts.
Robust and Efficient Segmentation of Cross-domain Medical Images
Jul 26, 2022



Efficient medical image segmentation aims to provide accurate pixel-wise prediction for the medical images with the lightweight implementation framework. However, lightweight frameworks generally fail to achieve high performance, and suffer from the poor generalizable ability on cross-domain tasks.In this paper, we propose a generalizable knowledge distillation method for robust and efficient segmentation of cross-domain medical images. Primarily, we propose the Model-Specific Alignment Networks (MSAN) to provide the domain-invariant representations which are regularized by a Pre-trained Semantic AutoEncoder (P-SAE). Meanwhile, a customized Alignment Consistency Training (ACT) strategy is designed to promote the MSAN training. With the domain-invariant representative vectors in MSAN, we propose two generalizable knowledge distillation schemes, Dual Contrastive Graph Distillation (DCGD) and Domain-Invariant Cross Distillation (DICD). Specifically, in DCGD, two types of implicit contrastive graphs are designed to represent the intra-coupling and inter-coupling semantic correlations from the perspective of data distribution. In DICD, the domain-invariant semantic vectors from the two models (i.e., teacher and student) are leveraged to cross-reconstruct features by the header exchange of MSAN, which achieves generalizable improvement for both the encoder and decoder in the student model. Furthermore, a metric named Fr\'echet Semantic Distance (FSD) is tailored to verify the effectiveness of the regularized domain-invariant features. Extensive experiments conducted on the Liver and Retinal Vessel Segmentation datasets demonstrate the priority of our method, in terms of performance and generalization on lightweight frameworks.
ShowFace: Coordinated Face Inpainting with Memory-Disentangled Refinement Networks
Apr 16, 2022



Face inpainting aims to complete the corrupted regions of the face images, which requires coordination between the completed areas and the non-corrupted areas. Recently, memory-oriented methods illustrate great prospects in the generation related tasks by introducing an external memory module to improve image coordination. However, such methods still have limitations in restoring the consistency and continuity for specificfacial semantic parts. In this paper, we propose the coarse-to-fine Memory-Disentangled Refinement Networks (MDRNets) for coordinated face inpainting, in which two collaborative modules are integrated, Disentangled Memory Module (DMM) and Mask-Region Enhanced Module (MREM). Specifically, the DMM establishes a group of disentangled memory blocks to store the semantic-decoupled face representations, which could provide the most relevant information to refine the semantic-level coordination. The MREM involves a masked correlation mining mechanism to enhance the feature relationships into the corrupted regions, which could also make up for the correlation loss caused by memory disentanglement. Furthermore, to better improve the inter-coordination between the corrupted and non-corrupted regions and enhance the intra-coordination in corrupted regions, we design InCo2 Loss, a pair of similarity based losses to constrain the feature consistency. Eventually, extensive experiments conducted on CelebA-HQ and FFHQ datasets demonstrate the superiority of our MDRNets compared with previous State-Of-The-Art methods.
MOST-Net: A Memory Oriented Style Transfer Network for Face Sketch Synthesis
Feb 08, 2022



Face sketch synthesis has been widely used in multi-media entertainment and law enforcement. Despite the recent developments in deep neural networks, accurate and realistic face sketch synthesis is still a challenging task due to the diversity and complexity of human faces. Current image-to-image translation-based face sketch synthesis frequently encounters over-fitting problems when it comes to small-scale datasets. To tackle this problem, we present an end-to-end Memory Oriented Style Transfer Network (MOST-Net) for face sketch synthesis which can produce high-fidelity sketches with limited data. Specifically, an external self-supervised dynamic memory module is introduced to capture the domain alignment knowledge in the long term. In this way, our proposed model could obtain the domain-transfer ability by establishing the durable relationship between faces and corresponding sketches on the feature level. Furthermore, we design a novel Memory Refinement Loss (MR Loss) for feature alignment in the memory module, which enhances the accuracy of memory slots in an unsupervised manner. Extensive experiments on the CUFS and the CUFSF datasets show that our MOST-Net achieves state-of-the-art performance, especially in terms of the Structural Similarity Index(SSIM).
Biphasic Face Photo-Sketch Synthesis via Semantic-Driven Generative Adversarial Network with Graph Representation Learning
Jan 05, 2022



In recent years, significant progress has been achieved in biphasic face photo-sketch synthesis with the development of Generative Adversarial Network (GAN). Biphasic face photo-sketch synthesis could be applied in wide-ranging fields such as digital entertainment and law enforcement. However, generating realistic photos and distinct sketches suffers from great challenges due to the low quality of sketches and complex photo variations in the real scenes. To this end, we propose a novel Semantic-Driven Generative Adversarial Network to address the above issues, cooperating with the Graph Representation Learning. Specifically, we inject class-wise semantic layouts into the generator to provide style-based spatial supervision for synthesized face photos and sketches. In addition, to improve the fidelity of the generated results, we leverage the semantic layouts to construct two types of Representational Graphs which indicate the intra-class semantic features and inter-class structural features of the synthesized images. Furthermore, we design two types of constraints based on the proposed Representational Graphs which facilitate the preservation of the details in generated face photos and sketches. Moreover, to further enhance the perceptual quality of synthesized images, we propose a novel biphasic training strategy which is dedicated to refine the generated results through Iterative Cycle Training. Extensive experiments are conducted on CUFS and CUFSF datasets to demonstrate the prominent ability of our proposed method which achieves the state-of-the-art performance.
Self-supervised Correlation Mining Network for Person Image Generation
Nov 29, 2021



Person image generation aims to perform non-rigid deformation on source images, which generally requires unaligned data pairs for training. Recently, self-supervised methods express great prospects in this task by merging the disentangled representations for self-reconstruction. However, such methods fail to exploit the spatial correlation between the disentangled features. In this paper, we propose a Self-supervised Correlation Mining Network (SCM-Net) to rearrange the source images in the feature space, in which two collaborative modules are integrated, Decomposed Style Encoder (DSE) and Correlation Mining Module (CMM). Specifically, the DSE first creates unaligned pairs at the feature level. Then, the CMM establishes the spatial correlation field for feature rearrangement. Eventually, a translation module transforms the rearranged features to realistic results. Meanwhile, for improving the fidelity of cross-scale pose transformation, we propose a graph based Body Structure Retaining Loss (BSR Loss) to preserve reasonable body structures on half body to full body generation. Extensive experiments conducted on DeepFashion dataset demonstrate the superiority of our method compared with other supervised and unsupervised approaches. Furthermore, satisfactory results on face generation show the versatility of our method in other deformation tasks.