 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYiwen Wang
Multimodal Semantic-Aware Automatic Colorization with Diffusion Prior
Apr 25, 2024




Colorizing grayscale images offers an engaging visual experience. Existing automatic colorization methods often fail to generate satisfactory results due to incorrect semantic colors and unsaturated colors. In this work, we propose an automatic colorization pipeline to overcome these challenges. We leverage the extraordinary generative ability of the diffusion prior to synthesize color with plausible semantics. To overcome the artifacts introduced by the diffusion prior, we apply the luminance conditional guidance. Moreover, we adopt multimodal high-level semantic priors to help the model understand the image content and deliver saturated colors. Besides, a luminance-aware decoder is designed to restore details and enhance overall visual quality. The proposed pipeline synthesizes saturated colors while maintaining plausible semantics. Experiments indicate that our proposed method considers both diversity and fidelity, surpassing previous methods in terms of perceptual realism and gain most human preference.
Learn to Sing by Listening: Building Controllable Virtual Singer by Unsupervised Learning from Voice Recordings
May 09, 2023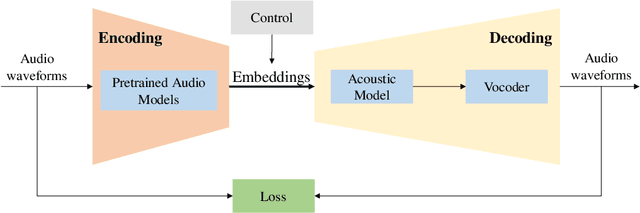

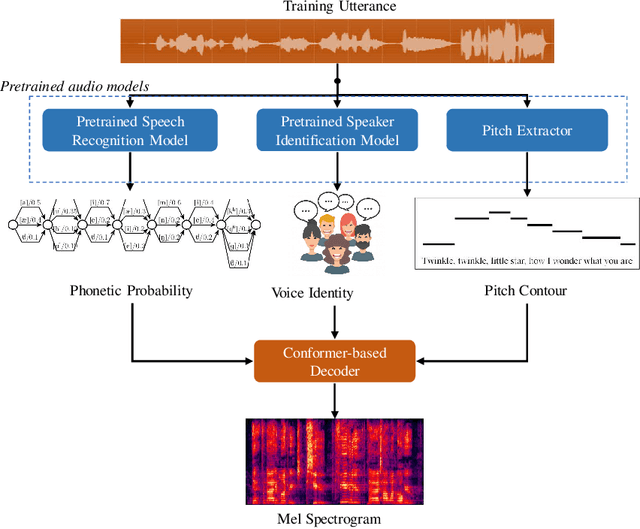
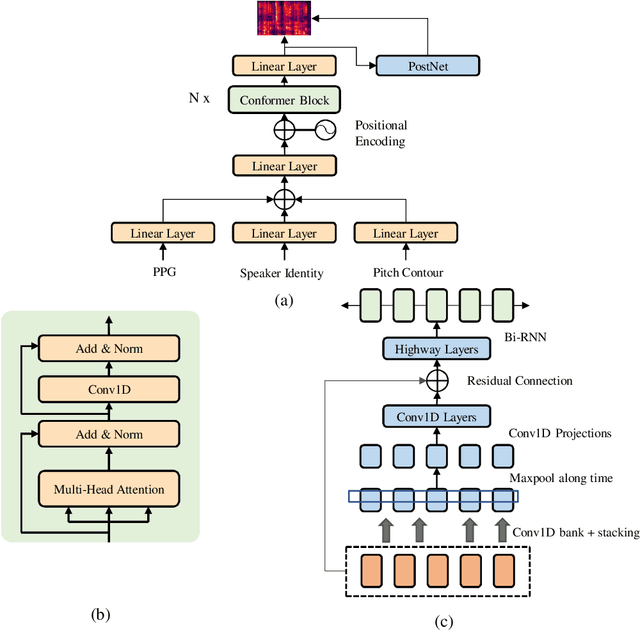
The virtual world is being established in which digital humans are created indistinguishable from real humans. Producing their audio-related capabilities is crucial since voice conveys extensive personal characteristics. We aim to create a controllable audio-form virtual singer; however, supervised modeling and controlling all different factors of the singing voice, such as timbre, tempo, pitch, and lyrics, is extremely difficult since accurately labeling all such information needs enormous labor work. In this paper, we propose a framework that could digitize a person's voice by simply "listening" to the clean voice recordings of any content in a fully unsupervised manner and predict singing voices even only using speaking recordings. A variational auto-encoder (VAE) based framework is developed, which leverages a set of pre-trained models to encode the audio as various hidden embeddings representing different factors of the singing voice, and further decodes the embeddings into raw audio. By manipulating the hidden embeddings for different factors, the resulting singing voices can be controlled, and new virtual singers can also be further generated by interpolating between timbres. Evaluations of different types of experiments demonstrate the proposed method's effectiveness. The proposed method is the critical technique for producing the AI choir, which empowered the human-AI symbiotic orchestra in Hong Kong in July 2022.
TT-Net: Dual-path transformer based sound field translation in the spherical harmonic domain
Oct 30, 2022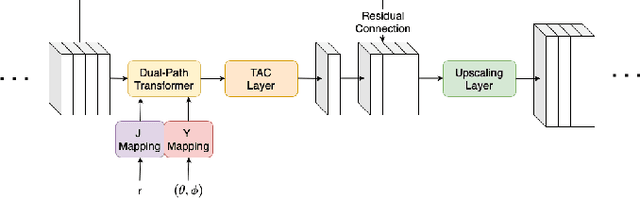
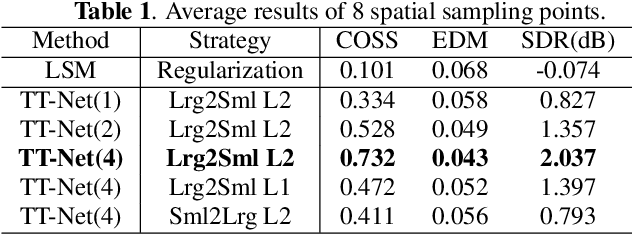
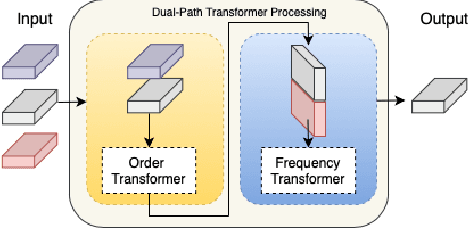
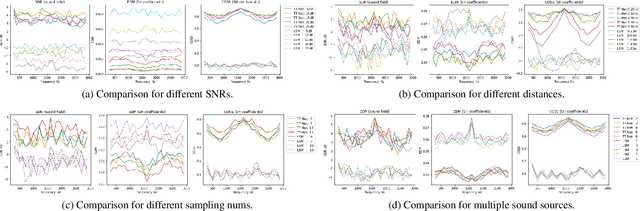
In the current method for the sound field translation tasks based on spherical harmonic (SH) analysis, the solution based on the additive theorem usually faces the problem of singular values caused by large matrix condition numbers. The influence of different distances and frequencies of the spherical radial function on the stability of the translation matrix will affect the accuracy of the SH coefficients at the selected point. Due to the problems mentioned above, we propose a neural network scheme based on the dual-path transformer. More specifically, the dual-path network is constructed by the self-attention module along the two dimensions of the frequency and order axes. The transform-average-concatenate layer and upscaling layer are introduced in the network, which provides solutions for multiple sampling points and upscaling. Numerical simulation results indicate that both the working frequency range and the distance range of the translation are extended. More accurate higher-order SH coefficients are obtained with the proposed dual-path network.
Machine unlearning via GAN
Nov 22, 2021


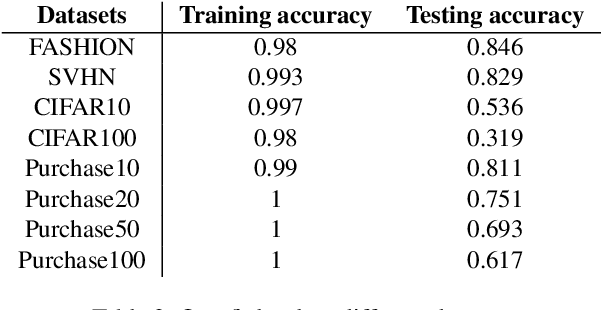
Machine learning models, especially deep models, may unintentionally remember information about their training data. Malicious attackers can thus pilfer some property about training data by attacking the model via membership inference attack or model inversion attack. Some regulations, such as the EU's GDPR, have enacted "The Right to Be Forgotten" to protect users' data privacy, enhancing individuals' sovereignty over their data. Therefore, removing training data information from a trained model has become a critical issue. In this paper, we present a GAN-based algorithm to delete data in deep models, which significantly improves deleting speed compared to retraining from scratch, especially in complicated scenarios. We have experimented on five commonly used datasets, and the experimental results show the efficiency of our method.
Subject Enveloped Deep Sample Fuzzy Ensemble Learning Algorithm of Parkinson's Speech Data
Nov 17, 2021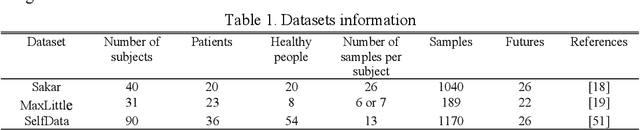
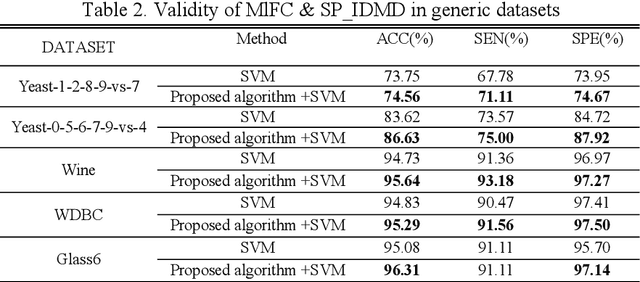

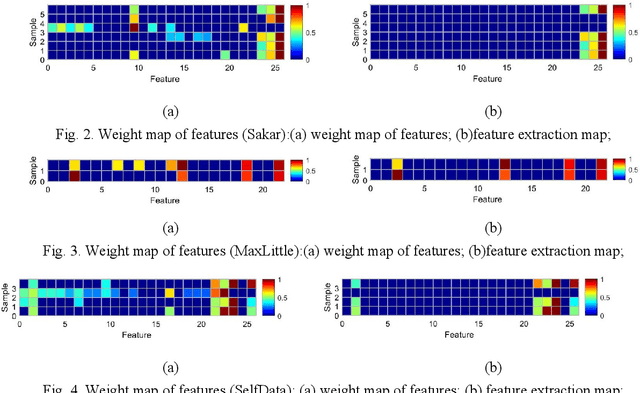
Parkinson disease (PD)'s speech recognition is an effective way for its diagnosis, which has become a hot and difficult research area in recent years. As we know, there are large corpuses (segments) within one subject. However, too large segments will increase the complexity of the classification model. Besides, the clinicians interested in finding diagnostic speech markers that reflect the pathology of the whole subject. Since the optimal relevant features of each speech sample segment are different, it is difficult to find the uniform diagnostic speech markers. Therefore, it is necessary to reconstruct the existing large segments within one subject into few segments even one segment within one subject, which can facilitate the extraction of relevant speech features to characterize diagnostic markers for the whole subject. To address this problem, an enveloped deep speech sample learning algorithm for Parkinson's subjects based on multilayer fuzzy c-mean (MlFCM) clustering and interlayer consistency preservation is proposed in this paper. The algorithm can be used to achieve intra-subject sample reconstruction for Parkinson's disease (PD) to obtain a small number of high-quality prototype sample segments. At the end of the paper, several representative PD speech datasets are selected and compared with the state-of-the-art related methods, respectively. The experimental results show that the proposed algorithm is effective signifcantly.
Lightweight machine unlearning in neural network
Nov 10, 2021



In recent years, machine learning neural network has penetrated deeply into people's life. As the price of convenience, people's private information also has the risk of disclosure. The "right to be forgotten" was introduced in a timely manner, stipulating that individuals have the right to withdraw their consent from personal information processing activities based on their consent. To solve this problem, machine unlearning is proposed, which allows the model to erase all memory of private information. Previous studies, including retraining and incremental learning to update models, often take up extra storage space or are difficult to apply to neural networks. Our method only needs to make a small perturbation of the weight of the target model and make it iterate in the direction of the model trained with the remaining data subset until the contribution of the unlearning data to the model is completely eliminated. In this paper, experiments on five datasets prove the effectiveness of our method for machine unlearning, and our method is 15 times faster than retraining.
Controlled Evaluation of Grammatical Knowledge in Mandarin Chinese Language Models
Sep 22, 2021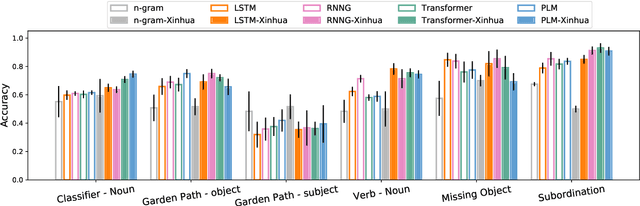
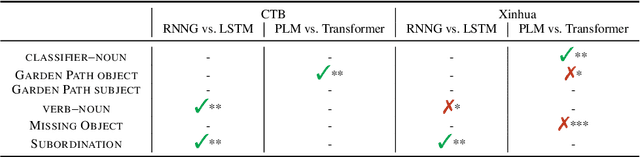
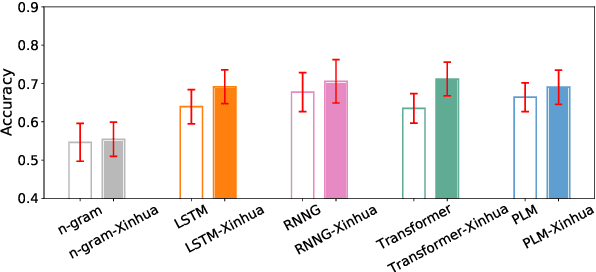
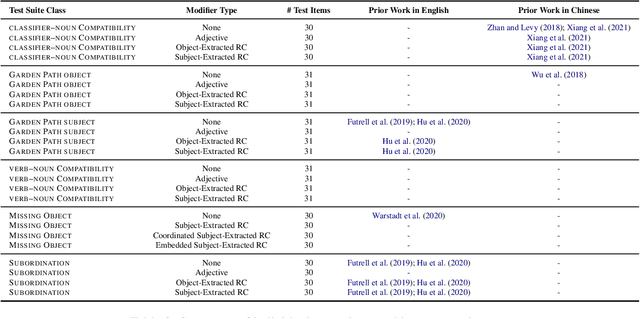
Prior work has shown that structural supervision helps English language models learn generalizations about syntactic phenomena such as subject-verb agreement. However, it remains unclear if such an inductive bias would also improve language models' ability to learn grammatical dependencies in typologically different languages. Here we investigate this question in Mandarin Chinese, which has a logographic, largely syllable-based writing system; different word order; and sparser morphology than English. We train LSTMs, Recurrent Neural Network Grammars, Transformer language models, and Transformer-parameterized generative parsing models on two Mandarin Chinese datasets of different sizes. We evaluate the models' ability to learn different aspects of Mandarin grammar that assess syntactic and semantic relationships. We find suggestive evidence that structural supervision helps with representing syntactic state across intervening content and improves performance in low-data settings, suggesting that the benefits of hierarchical inductive biases in acquiring dependency relationships may extend beyond English.
Tracking Fast Neural Adaptation by Globally Adaptive Point Process Estimation for Brain-Machine Interface
Jul 27, 2021



Brain-machine interfaces (BMIs) help the disabled restore body functions by translating neural activity into digital commands to control external devices. Neural adaptation, where the brain signals change in response to external stimuli or movements, plays an important role in BMIs. When subjects purely use neural activity to brain-control a prosthesis, some neurons will actively explore a new tuning property to accomplish the movement task. The prediction of this neural tuning property can help subjects adapt more efficiently to brain control and maintain good decoding performance. Existing prediction methods track the slow change of the tuning property in the manual control, which is not suitable for the fast neural adaptation in brain control. In order to identify the active neurons in brain control and track their tuning property changes, we propose a globally adaptive point process method (GaPP) to estimate the neural modulation state from spike trains, decompose the states into the hyper preferred direction and reconstruct the kinematics in a dual-model framework. We implement the method on real data from rats performing a two-lever discrimination task under manual control and brain control. The results show our method successfully predicts the neural modulation state and identifies the neurons that become active in brain control. Compared to existing methods, ours tracks the fast changes of the hyper preferred direction from manual control to brain control more accurately and efficiently and reconstructs the kinematics better and faster.