 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBohao Yang
Structured Information Matters: Incorporating Abstract Meaning Representation into LLMs for Improved Open-Domain Dialogue Evaluation
Apr 06, 2024
Automatic open-domain dialogue evaluation has attracted increasing attention. Trainable evaluation metrics are commonly trained with true positive and randomly selected negative responses, resulting in a tendency for them to assign a higher score to the responses that share higher content similarity with a given context. However, adversarial negative responses possess high content similarity with the contexts whilst being semantically different. Therefore, existing evaluation metrics are not robust enough to evaluate such responses, resulting in low correlations with human judgments. While recent studies have shown some efficacy in utilizing Large Language Models (LLMs) for open-domain dialogue evaluation, they still encounter challenges in effectively handling adversarial negative examples. In this paper, we propose a simple yet effective framework for open-domain dialogue evaluation, which combines domain-specific language models (SLMs) with LLMs. The SLMs can explicitly incorporate Abstract Meaning Representation (AMR) graph information of the dialogue through a gating mechanism for enhanced semantic representation learning. The evaluation result of SLMs and AMR graph information are plugged into the prompt of LLM, for the enhanced in-context learning performance. Experimental results on open-domain dialogue evaluation tasks demonstrate the superiority of our method compared to a wide range of state-of-the-art baselines, especially in discriminating adversarial negative responses. Our code is available at https://github.com/Bernard-Yang/SIMAMR.
SciMMIR: Benchmarking Scientific Multi-modal Information Retrieval
Jan 24, 2024Multi-modal information retrieval (MMIR) is a rapidly evolving field, where significant progress, particularly in image-text pairing, has been made through advanced representation learning and cross-modality alignment research. However, current benchmarks for evaluating MMIR performance in image-text pairing within the scientific domain show a notable gap, where chart and table images described in scholarly language usually do not play a significant role. To bridge this gap, we develop a specialised scientific MMIR (SciMMIR) benchmark by leveraging open-access paper collections to extract data relevant to the scientific domain. This benchmark comprises 530K meticulously curated image-text pairs, extracted from figures and tables with detailed captions in scientific documents. We further annotate the image-text pairs with two-level subset-subcategory hierarchy annotations to facilitate a more comprehensive evaluation of the baselines. We conducted zero-shot and fine-tuning evaluations on prominent multi-modal image-captioning and visual language models, such as CLIP and BLIP. Our analysis offers critical insights for MMIR in the scientific domain, including the impact of pre-training and fine-tuning settings and the influence of the visual and textual encoders. All our data and checkpoints are publicly available at https://github.com/Wusiwei0410/SciMMIR.
Effective Distillation of Table-based Reasoning Ability from LLMs
Sep 22, 2023


Large Language Models (LLMs) have demonstrated remarkable performance across a wide range of natural language processing tasks. However, their remarkable parameter size and their impressive high requirement of computing resources pose challenges for their practical deployment. Recent research has revealed that specific capabilities of LLMs, such as numerical reasoning, can be transferred to smaller models through distillation. Some studies explore the potential of leveraging LLMs to perform table-based reasoning. Nevertheless, prior to our work, there has been no investigation into the prospect of specialising table reasoning skills in smaller models specifically tailored for table-to-text generation tasks. In this paper, we propose a novel table-based reasoning distillation, with the aim of distilling distilling LLMs into tailored, smaller models specifically designed for table-based reasoning task. Experimental results have shown that a 0.22 billion parameter model (Flan-T5-base) fine-tuned using distilled data, not only achieves a significant improvement compared to traditionally fine-tuned baselines but also surpasses specific LLMs like gpt-3.5-turbo on the scientific table-to-text generation dataset (SciGen). The code and data are released in https://github.com/Bernard-Yang/TableDistill.
Improving Medical Dialogue Generation with Abstract Meaning Representations
Sep 19, 2023



Medical Dialogue Generation serves a critical role in telemedicine by facilitating the dissemination of medical expertise to patients. Existing studies focus on incorporating textual representations, which have limited their ability to represent the semantics of text, such as ignoring important medical entities. To enhance the model's understanding of the textual semantics and the medical knowledge including entities and relations, we introduce the use of Abstract Meaning Representations (AMR) to construct graphical representations that delineate the roles of language constituents and medical entities within the dialogues. In this paper, We propose a novel framework that models dialogues between patients and healthcare professionals using AMR graphs, where the neural networks incorporate textual and graphical knowledge with a dual attention mechanism. Experimental results show that our framework outperforms strong baseline models in medical dialogue generation, demonstrating the effectiveness of AMR graphs in enhancing the representations of medical knowledge and logical relationships. Furthermore, to support future research in this domain, we provide the corresponding source code at https://github.com/Bernard-Yang/MedDiaAMR.
Evaluating Open-Domain Dialogues in Latent Space with Next Sentence Prediction and Mutual Information
Jun 10, 2023



The long-standing one-to-many issue of the open-domain dialogues poses significant challenges for automatic evaluation methods, i.e., there may be multiple suitable responses which differ in semantics for a given conversational context. To tackle this challenge, we propose a novel learning-based automatic evaluation metric (CMN), which can robustly evaluate open-domain dialogues by augmenting Conditional Variational Autoencoders (CVAEs) with a Next Sentence Prediction (NSP) objective and employing Mutual Information (MI) to model the semantic similarity of text in the latent space. Experimental results on two open-domain dialogue datasets demonstrate the superiority of our method compared with a wide range of baselines, especially in handling responses which are distant to the golden reference responses in semantics.
HERB: Measuring Hierarchical Regional Bias in Pre-trained Language Models
Nov 05, 2022



Fairness has become a trending topic in natural language processing (NLP), which addresses biases targeting certain social groups such as genders and religions. However, regional bias in language models (LMs), a long-standing global discrimination problem, still remains unexplored. This paper bridges the gap by analysing the regional bias learned by the pre-trained language models that are broadly used in NLP tasks. In addition to verifying the existence of regional bias in LMs, we find that the biases on regional groups can be strongly influenced by the geographical clustering of the groups. We accordingly propose a HiErarchical Regional Bias evaluation method (HERB) utilising the information from the sub-region clusters to quantify the bias in pre-trained LMs. Experiments show that our hierarchical metric can effectively evaluate the regional bias with respect to comprehensive topics and measure the potential regional bias that can be propagated to downstream tasks. Our codes are available at https://github.com/Bernard-Yang/HERB.
PUF-Phenotype: A Robust and Noise-Resilient Approach to Aid Intra-Group-based Authentication with DRAM-PUFs Using Machine Learning
Jul 11, 2022

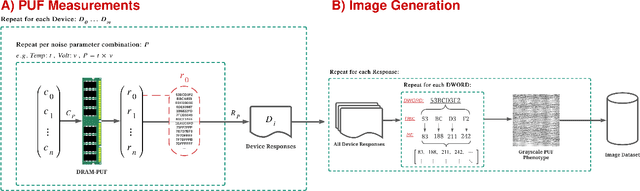
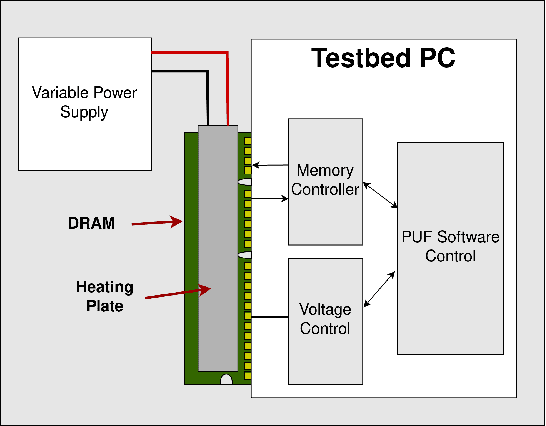
As the demand for highly secure and dependable lightweight systems increases in the modern world, Physically Unclonable Functions (PUFs) continue to promise a lightweight alternative to high-cost encryption techniques and secure key storage. While the security features promised by PUFs are highly attractive for secure system designers, they have been shown to be vulnerable to various sophisticated attacks - most notably Machine Learning (ML) based modelling attacks (ML-MA) which attempt to digitally clone the PUF behaviour and thus undermine their security. More recent ML-MA have even exploited publicly known helper data required for PUF error correction in order to predict PUF responses without requiring knowledge of response data. In response to this, research is beginning to emerge regarding the authentication of PUF devices with the assistance of ML as opposed to traditional PUF techniques of storage and comparison of pre-known Challenge-Response pairs (CRPs). In this article, we propose a classification system using ML based on a novel `PUF-Phenotype' concept to accurately identify the origin and determine the validity of noisy memory derived (DRAM) PUF responses as an alternative to helper data-reliant denoising techniques. To our best knowledge, we are the first to perform classification over multiple devices per model to enable a group-based PUF authentication scheme. We achieve up to 98\% classification accuracy using a modified deep convolutional neural network (CNN) for feature extraction in conjunction with several well-established classifiers. We also experimentally verified the performance of our model on a Raspberry Pi device to determine the suitability of deploying our proposed model in a resource-constrained environment.