 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHanqi Yan
Counterfactual Generation with Identifiability Guarantees
Feb 23, 2024
Counterfactual generation lies at the core of various machine learning tasks, including image translation and controllable text generation. This generation process usually requires the identification of the disentangled latent representations, such as content and style, that underlie the observed data. However, it becomes more challenging when faced with a scarcity of paired data and labeling information. Existing disentangled methods crucially rely on oversimplified assumptions, such as assuming independent content and style variables, to identify the latent variables, even though such assumptions may not hold for complex data distributions. For instance, food reviews tend to involve words like tasty, whereas movie reviews commonly contain words such as thrilling for the same positive sentiment. This problem is exacerbated when data are sampled from multiple domains since the dependence between content and style may vary significantly over domains. In this work, we tackle the domain-varying dependence between the content and the style variables inherent in the counterfactual generation task. We provide identification guarantees for such latent-variable models by leveraging the relative sparsity of the influences from different latent variables. Our theoretical insights enable the development of a doMain AdapTive counTerfactual gEneration model, called (MATTE). Our theoretically grounded framework achieves state-of-the-art performance in unsupervised style transfer tasks, where neither paired data nor style labels are utilized, across four large-scale datasets. Code is available at https://github.com/hanqi-qi/Matte.git
Addressing Order Sensitivity of In-Context Demonstration Examples in Causal Language Models
Feb 23, 2024In-context learning has become a popular paradigm in natural language processing. However, its performance can be significantly influenced by the order of in-context demonstration examples. In this paper, we found that causal language models (CausalLMs) are more sensitive to this order compared to prefix language models (PrefixLMs). We attribute this phenomenon to the auto-regressive attention masks within CausalLMs, which restrict each token from accessing information from subsequent tokens. This results in different receptive fields for samples at different positions, thereby leading to representation disparities across positions. To tackle this challenge, we introduce an unsupervised fine-tuning method, termed the Information-Augmented and Consistency-Enhanced approach. This approach utilizes contrastive learning to align representations of in-context examples across different positions and introduces a consistency loss to ensure similar representations for inputs with different permutations. This enhances the model's predictive consistency across permutations. Experimental results on four benchmarks suggest that our proposed method can reduce the sensitivity to the order of in-context examples and exhibit robust generalizability, particularly when demonstrations are sourced from a pool different from that used in the training phase, or when the number of in-context examples differs from what is used during training.
Mirror: A Multiple-perspective Self-Reflection Method for Knowledge-rich Reasoning
Feb 22, 2024While Large language models (LLMs) have the capability to iteratively reflect on their own outputs, recent studies have observed their struggles with knowledge-rich problems without access to external resources. In addition to the inefficiency of LLMs in self-assessment, we also observe that LLMs struggle to revisit their predictions despite receiving explicit negative feedback. Therefore, We propose Mirror, a Multiple-perspective self-reflection method for knowledge-rich reasoning, to avoid getting stuck at a particular reflection iteration. Mirror enables LLMs to reflect from multiple-perspective clues, achieved through a heuristic interaction between a Navigator and a Reasoner. It guides agents toward diverse yet plausibly reliable reasoning trajectory without access to ground truth by encouraging (1) diversity of directions generated by Navigator and (2) agreement among strategically induced perturbations in responses generated by the Reasoner. The experiments on five reasoning datasets demonstrate that Mirror's superiority over several contemporary self-reflection approaches. Additionally, the ablation study studies clearly indicate that our strategies alleviate the aforementioned challenges.
The Mystery and Fascination of LLMs: A Comprehensive Survey on the Interpretation and Analysis of Emergent Abilities
Nov 01, 2023Understanding emergent abilities, such as in-context learning (ICL) and chain-of-thought (CoT) prompting in large language models (LLMs), is of utmost importance. This importance stems not only from the better utilization of these capabilities across various tasks, but also from the proactive identification and mitigation of potential risks, including concerns of truthfulness, bias, and toxicity, that may arise alongside these capabilities. In this paper, we present a thorough survey on the interpretation and analysis of emergent abilities of LLMs. First, we provide a concise introduction to the background and definition of emergent abilities. Then, we give an overview of advancements from two perspectives: 1) a macro perspective, emphasizing studies on the mechanistic interpretability and delving into the mathematical foundations behind emergent abilities; and 2) a micro-perspective, concerning studies that focus on empirical interpretability by examining factors associated with these abilities. We conclude by highlighting the challenges encountered and suggesting potential avenues for future research. We believe that our work establishes the basis for further exploration into the interpretation of emergent abilities.
Explainable Recommender with Geometric Information Bottleneck
May 09, 2023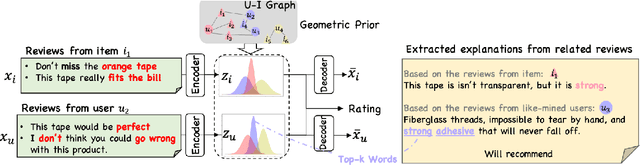
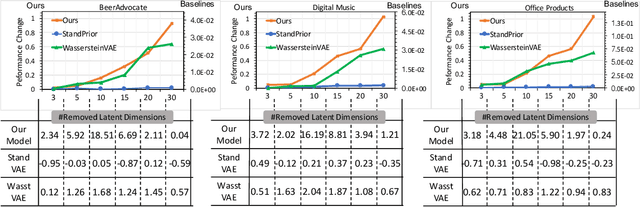

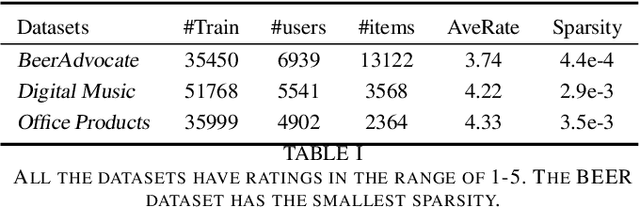
Explainable recommender systems can explain their recommendation decisions, enhancing user trust in the systems. Most explainable recommender systems either rely on human-annotated rationales to train models for explanation generation or leverage the attention mechanism to extract important text spans from reviews as explanations. The extracted rationales are often confined to an individual review and may fail to identify the implicit features beyond the review text. To avoid the expensive human annotation process and to generate explanations beyond individual reviews, we propose to incorporate a geometric prior learnt from user-item interactions into a variational network which infers latent factors from user-item reviews. The latent factors from an individual user-item pair can be used for both recommendation and explanation generation, which naturally inherit the global characteristics encoded in the prior knowledge. Experimental results on three e-commerce datasets show that our model significantly improves the interpretability of a variational recommender using the Wasserstein distance while achieving performance comparable to existing content-based recommender systems in terms of recommendation behaviours.
Distinguishability Calibration to In-Context Learning
Feb 13, 2023
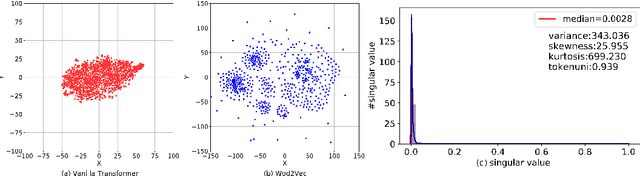
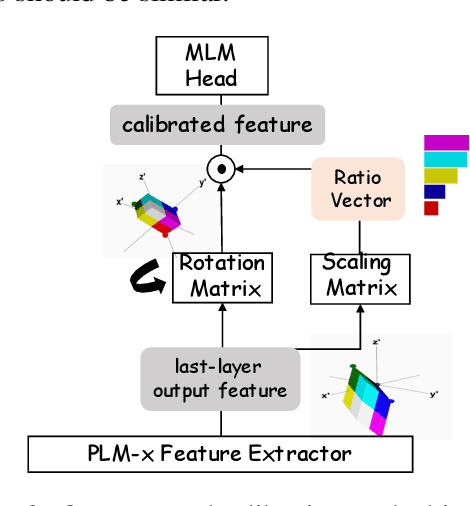
Recent years have witnessed increasing interests in prompt-based learning in which models can be trained on only a few annotated instances, making them suitable in low-resource settings. When using prompt-based learning for text classification, the goal is to use a pre-trained language model (PLM) to predict a missing token in a pre-defined template given an input text, which can be mapped to a class label. However, PLMs built on the transformer architecture tend to generate similar output embeddings, making it difficult to discriminate between different class labels. The problem is further exacerbated when dealing with classification tasks involving many fine-grained class labels. In this work, we alleviate this information diffusion issue, i.e., different tokens share a large proportion of similar information after going through stacked multiple self-attention layers in a transformer, by proposing a calibration method built on feature transformations through rotation and scaling to map a PLM-encoded embedding into a new metric space to guarantee the distinguishability of the resulting embeddings. Furthermore, we take the advantage of hyperbolic embeddings to capture the hierarchical relations among fine-grained class-associated token embedding by a coarse-to-fine metric learning strategy to enhance the distinguishability of the learned output embeddings. Extensive experiments on the three datasets under various settings demonstrate the effectiveness of our approach. Our code can be found at https://github.com/donttal/TARA.
Tracking Brand-Associated Polarity-Bearing Topics in User Reviews
Jan 03, 2023
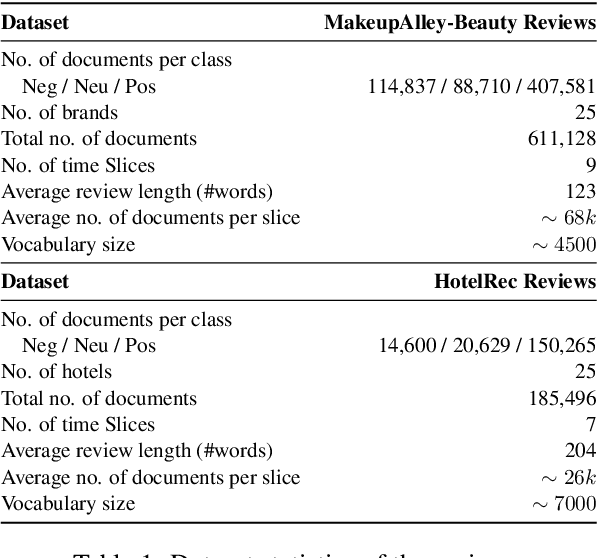
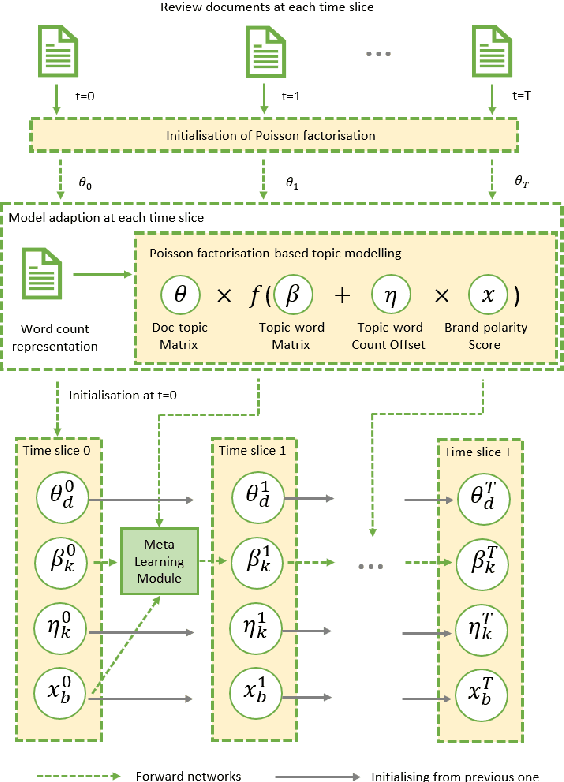
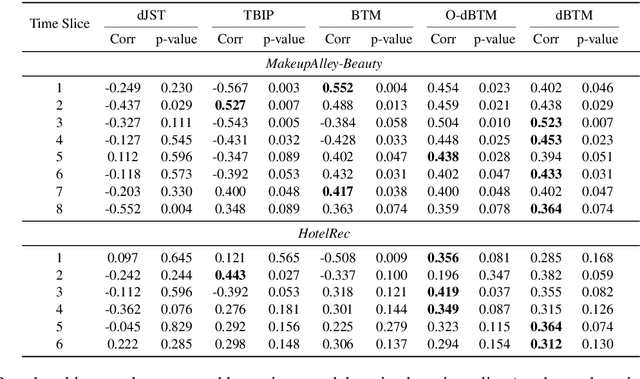
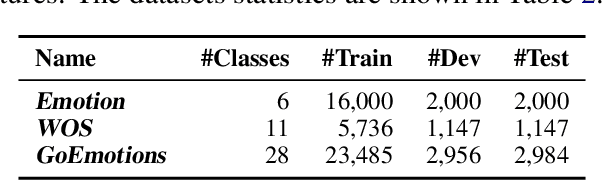
Monitoring online customer reviews is important for business organisations to measure customer satisfaction and better manage their reputations. In this paper, we propose a novel dynamic Brand-Topic Model (dBTM) which is able to automatically detect and track brand-associated sentiment scores and polarity-bearing topics from product reviews organised in temporally-ordered time intervals. dBTM models the evolution of the latent brand polarity scores and the topic-word distributions over time by Gaussian state space models. It also incorporates a meta learning strategy to control the update of the topic-word distribution in each time interval in order to ensure smooth topic transitions and better brand score predictions. It has been evaluated on a dataset constructed from MakeupAlley reviews and a hotel review dataset. Experimental results show that dBTM outperforms a number of competitive baselines in brand ranking, achieving a good balance of topic coherence and uniqueness, and extracting well-separated polarity-bearing topics across time intervals.
Addressing Token Uniformity in Transformers via Singular Value Transformation
Aug 24, 2022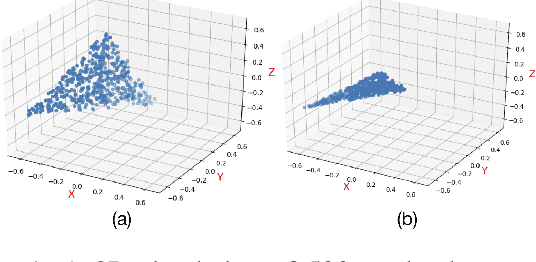
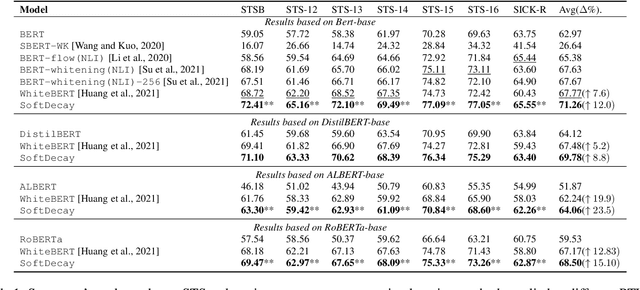
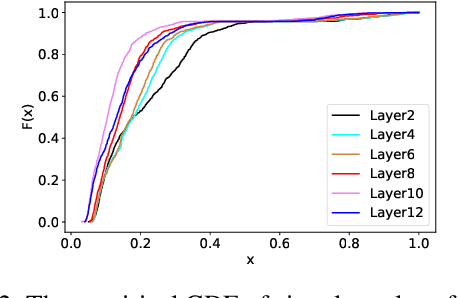
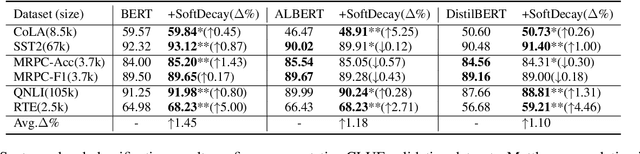
Token uniformity is commonly observed in transformer-based models, in which different tokens share a large proportion of similar information after going through stacked multiple self-attention layers in a transformer. In this paper, we propose to use the distribution of singular values of outputs of each transformer layer to characterise the phenomenon of token uniformity and empirically illustrate that a less skewed singular value distribution can alleviate the `token uniformity' problem. Base on our observations, we define several desirable properties of singular value distributions and propose a novel transformation function for updating the singular values. We show that apart from alleviating token uniformity, the transformation function should preserve the local neighbourhood structure in the original embedding space. Our proposed singular value transformation function is applied to a range of transformer-based language models such as BERT, ALBERT, RoBERTa and DistilBERT, and improved performance is observed in semantic textual similarity evaluation and a range of GLUE tasks. Our source code is available at https://github.com/hanqi-qi/tokenUni.git.
Hierarchical Interpretation of Neural Text Classification
Feb 20, 2022
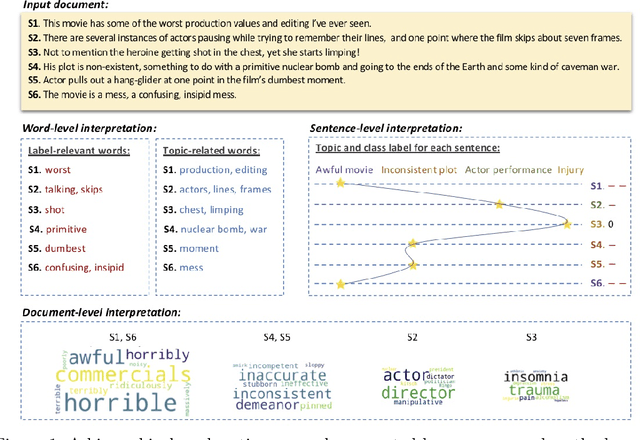
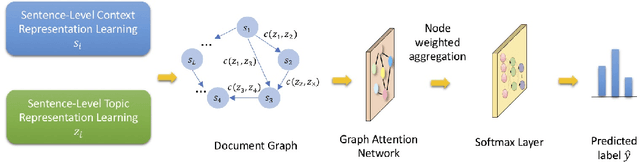
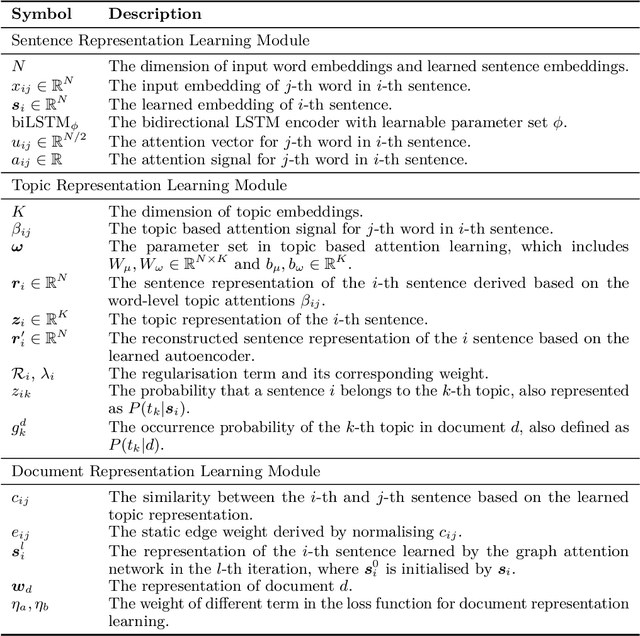
Recent years have witnessed increasing interests in developing interpretable models in Natural Language Processing (NLP). Most existing models aim at identifying input features such as words or phrases important for model predictions. Neural models developed in NLP however often compose word semantics in a hierarchical manner. Interpretation by words or phrases only thus cannot faithfully explain model decisions. This paper proposes a novel Hierarchical INTerpretable neural text classifier, called Hint, which can automatically generate explanations of model predictions in the form of label-associated topics in a hierarchical manner. Model interpretation is no longer at the word level, but built on topics as the basic semantic unit. Experimental results on both review datasets and news datasets show that our proposed approach achieves text classification results on par with existing state-of-the-art text classifiers, and generates interpretations more faithful to model predictions and better understood by humans than other interpretable neural text classifiers.
Position Bias Mitigation: A Knowledge-Aware Graph Model for Emotion Cause Extraction
Jun 08, 2021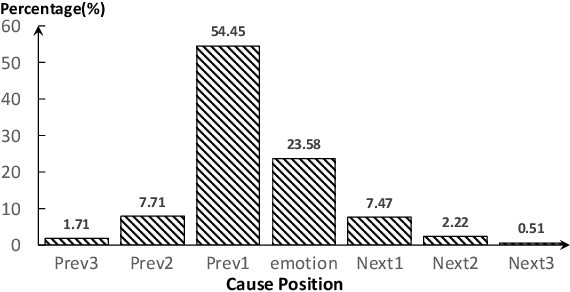
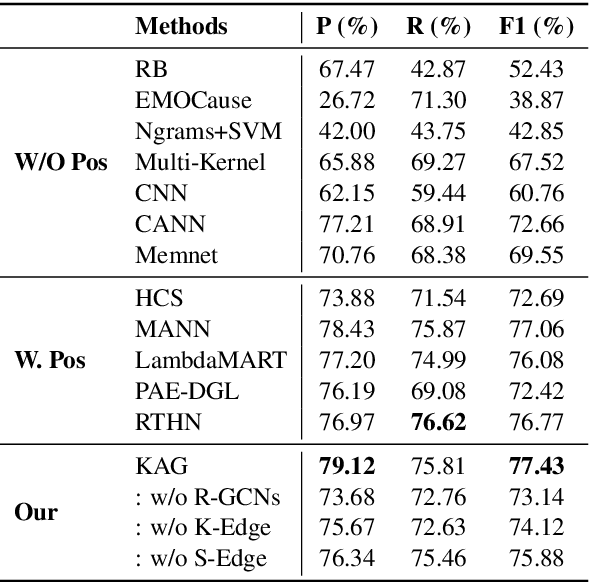
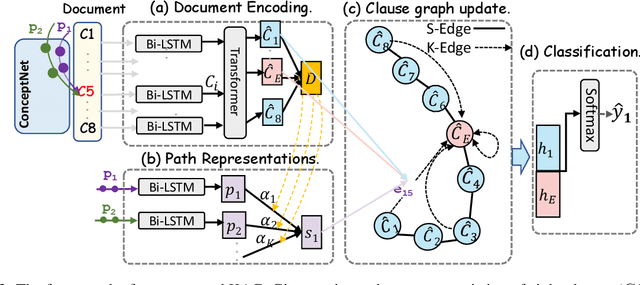
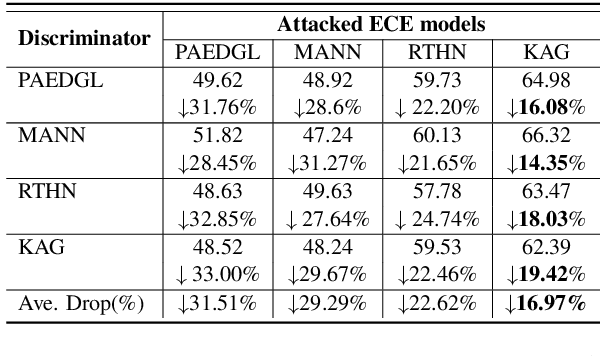
The Emotion Cause Extraction (ECE)} task aims to identify clauses which contain emotion-evoking information for a particular emotion expressed in text. We observe that a widely-used ECE dataset exhibits a bias that the majority of annotated cause clauses are either directly before their associated emotion clauses or are the emotion clauses themselves. Existing models for ECE tend to explore such relative position information and suffer from the dataset bias. To investigate the degree of reliance of existing ECE models on clause relative positions, we propose a novel strategy to generate adversarial examples in which the relative position information is no longer the indicative feature of cause clauses. We test the performance of existing models on such adversarial examples and observe a significant performance drop. To address the dataset bias, we propose a novel graph-based method to explicitly model the emotion triggering paths by leveraging the commonsense knowledge to enhance the semantic dependencies between a candidate clause and an emotion clause. Experimental results show that our proposed approach performs on par with the existing state-of-the-art methods on the original ECE dataset, and is more robust against adversarial attacks compared to existing models.