 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaohan Ding
Leveraging Prompt-Based Large Language Models: Predicting Pandemic Health Decisions and Outcomes Through Social Media Language
Mar 01, 2024
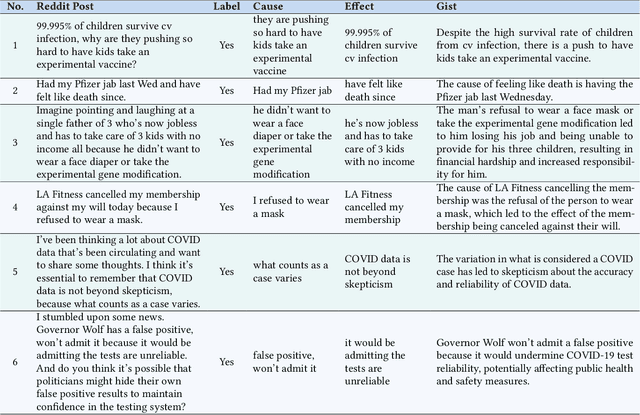
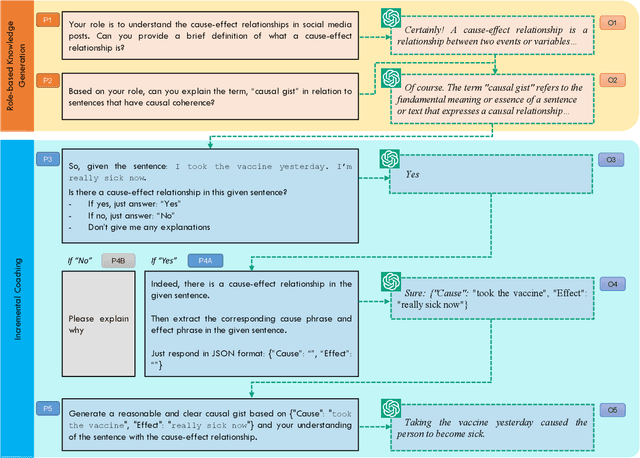
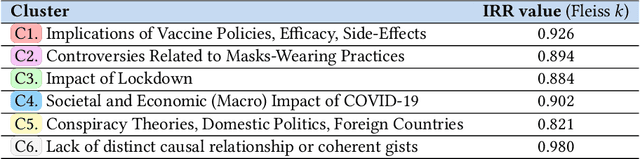
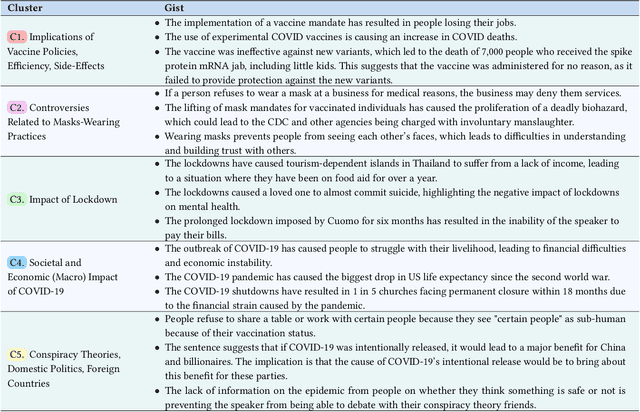
We introduce a multi-step reasoning framework using prompt-based LLMs to examine the relationship between social media language patterns and trends in national health outcomes. Grounded in fuzzy-trace theory, which emphasizes the importance of gists of causal coherence in effective health communication, we introduce Role-Based Incremental Coaching (RBIC), a prompt-based LLM framework, to identify gists at-scale. Using RBIC, we systematically extract gists from subreddit discussions opposing COVID-19 health measures (Study 1). We then track how these gists evolve across key events (Study 2) and assess their influence on online engagement (Study 3). Finally, we investigate how the volume of gists is associated with national health trends like vaccine uptake and hospitalizations (Study 4). Our work is the first to empirically link social media linguistic patterns to real-world public health trends, highlighting the potential of prompt-based LLMs in identifying critical online discussion patterns that can form the basis of public health communication strategies.
InteractiveVideo: User-Centric Controllable Video Generation with Synergistic Multimodal Instructions
Feb 05, 2024We introduce $\textit{InteractiveVideo}$, a user-centric framework for video generation. Different from traditional generative approaches that operate based on user-provided images or text, our framework is designed for dynamic interaction, allowing users to instruct the generative model through various intuitive mechanisms during the whole generation process, e.g. text and image prompts, painting, drag-and-drop, etc. We propose a Synergistic Multimodal Instruction mechanism, designed to seamlessly integrate users' multimodal instructions into generative models, thus facilitating a cooperative and responsive interaction between user inputs and the generative process. This approach enables iterative and fine-grained refinement of the generation result through precise and effective user instructions. With $\textit{InteractiveVideo}$, users are given the flexibility to meticulously tailor key aspects of a video. They can paint the reference image, edit semantics, and adjust video motions until their requirements are fully met. Code, models, and demo are available at https://github.com/invictus717/InteractiveVideo
Multimodal Pathway: Improve Transformers with Irrelevant Data from Other Modalities
Jan 25, 2024We propose to improve transformers of a specific modality with irrelevant data from other modalities, e.g., improve an ImageNet model with audio or point cloud datasets. We would like to highlight that the data samples of the target modality are irrelevant to the other modalities, which distinguishes our method from other works utilizing paired (e.g., CLIP) or interleaved data of different modalities. We propose a methodology named Multimodal Pathway - given a target modality and a transformer designed for it, we use an auxiliary transformer trained with data of another modality and construct pathways to connect components of the two models so that data of the target modality can be processed by both models. In this way, we utilize the universal sequence-to-sequence modeling abilities of transformers obtained from two modalities. As a concrete implementation, we use a modality-specific tokenizer and task-specific head as usual but utilize the transformer blocks of the auxiliary model via a proposed method named Cross-Modal Re-parameterization, which exploits the auxiliary weights without any inference costs. On the image, point cloud, video, and audio recognition tasks, we observe significant and consistent performance improvements with irrelevant data from other modalities. The code and models are available at https://github.com/AILab-CVC/M2PT.
VL-GPT: A Generative Pre-trained Transformer for Vision and Language Understanding and Generation
Dec 14, 2023In this work, we introduce Vision-Language Generative Pre-trained Transformer (VL-GPT), a transformer model proficient at concurrently perceiving and generating visual and linguistic data. VL-GPT achieves a unified pre-training approach for both image and text modalities by employing a straightforward auto-regressive objective, thereby enabling the model to process image and text as seamlessly as a language model processes text. To accomplish this, we initially propose a novel image tokenizer-detokenizer framework for visual data, specifically designed to transform raw images into a sequence of continuous embeddings and reconstruct them accordingly. In combination with the existing text tokenizer and detokenizer, this framework allows for the encoding of interleaved image-text data into a multimodal sequence, which can subsequently be fed into the transformer model. Consequently, VL-GPT can perform large-scale pre-training on multimodal corpora utilizing a unified auto-regressive objective (i.e., next-token prediction). Upon completion of pre-training, VL-GPT exhibits remarkable zero-shot and few-shot performance across a diverse range of vision and language understanding and generation tasks, including image captioning, visual question answering, text-to-image generation, and more. Additionally, the pre-trained model retrains in-context learning capabilities when provided with multimodal prompts. We further conduct instruction tuning on our VL-GPT, highlighting its exceptional potential for multimodal assistance. The source code and model weights shall be released.
Online Vectorized HD Map Construction using Geometry
Dec 06, 2023The construction of online vectorized High-Definition (HD) maps is critical for downstream prediction and planning. Recent efforts have built strong baselines for this task, however, shapes and relations of instances in urban road systems are still under-explored, such as parallelism, perpendicular, or rectangle-shape. In our work, we propose GeMap ($\textbf{Ge}$ometry $\textbf{Map}$), which end-to-end learns Euclidean shapes and relations of map instances beyond basic perception. Specifically, we design a geometric loss based on angle and distance clues, which is robust to rigid transformations. We also decouple self-attention to independently handle Euclidean shapes and relations. Our method achieves new state-of-the-art performance on the NuScenes and Argoverse 2 datasets. Remarkably, it reaches a 71.8% mAP on the large-scale Argoverse 2 dataset, outperforming MapTR V2 by +4.4% and surpassing the 70% mAP threshold for the first time. Code is available at https://github.com/cnzzx/GeMap
UniRepLKNet: A Universal Perception Large-Kernel ConvNet for Audio, Video, Point Cloud, Time-Series and Image Recognition
Nov 27, 2023Large-kernel convolutional neural networks (ConvNets) have recently received extensive research attention, but there are two unresolved and critical issues that demand further investigation. 1) The architectures of existing large-kernel ConvNets largely follow the design principles of conventional ConvNets or transformers, while the architectural design for large-kernel ConvNets remains under-addressed. 2) As transformers have dominated multiple modalities, it remains to be investigated whether ConvNets also have a strong universal perception ability in domains beyond vision. In this paper, we contribute from two aspects. 1) We propose four architectural guidelines for designing large-kernel ConvNets, the core of which is to exploit the essential characteristics of large kernels that distinguish them from small kernels - they can see wide without going deep. Following such guidelines, our proposed large-kernel ConvNet shows leading performance in image recognition. For example, our models achieve an ImageNet accuracy of 88.0%, ADE20K mIoU of 55.6%, and COCO box AP of 56.4%, demonstrating better performance and higher speed than a number of recently proposed powerful competitors. 2) We discover that large kernels are the key to unlocking the exceptional performance of ConvNets in domains where they were originally not proficient. With certain modality-related preprocessing approaches, the proposed model achieves state-of-the-art performance on time-series forecasting and audio recognition tasks even without modality-specific customization to the architecture. Code and all the models at https://github.com/AILab-CVC/UniRepLKNet.
Advancing Vision Transformers with Group-Mix Attention
Nov 26, 2023Vision Transformers (ViTs) have been shown to enhance visual recognition through modeling long-range dependencies with multi-head self-attention (MHSA), which is typically formulated as Query-Key-Value computation. However, the attention map generated from the Query and Key captures only token-to-token correlations at one single granularity. In this paper, we argue that self-attention should have a more comprehensive mechanism to capture correlations among tokens and groups (i.e., multiple adjacent tokens) for higher representational capacity. Thereby, we propose Group-Mix Attention (GMA) as an advanced replacement for traditional self-attention, which can simultaneously capture token-to-token, token-to-group, and group-to-group correlations with various group sizes. To this end, GMA splits the Query, Key, and Value into segments uniformly and performs different group aggregations to generate group proxies. The attention map is computed based on the mixtures of tokens and group proxies and used to re-combine the tokens and groups in Value. Based on GMA, we introduce a powerful backbone, namely GroupMixFormer, which achieves state-of-the-art performance in image classification, object detection, and semantic segmentation with fewer parameters than existing models. For instance, GroupMixFormer-L (with 70.3M parameters and 384^2 input) attains 86.2% Top-1 accuracy on ImageNet-1K without external data, while GroupMixFormer-B (with 45.8M parameters) attains 51.2% mIoU on ADE20K.
RefConv: Re-parameterized Refocusing Convolution for Powerful ConvNets
Oct 16, 2023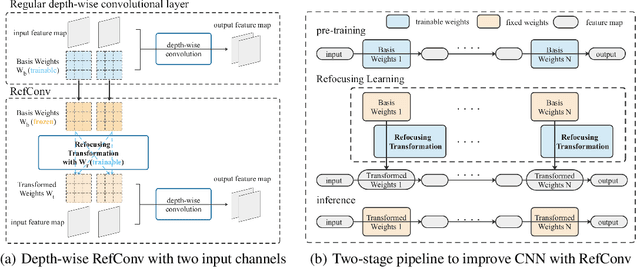
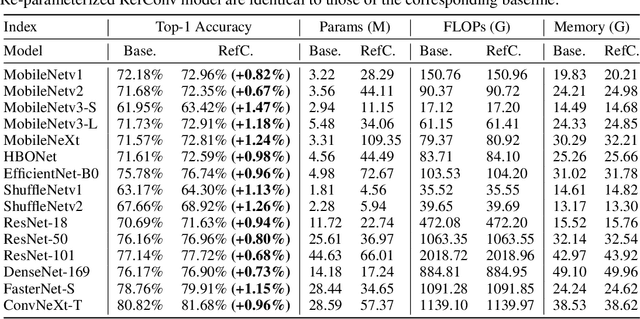
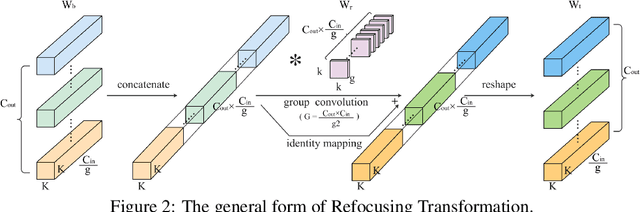
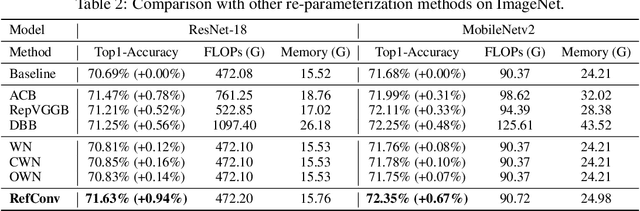
We propose Re-parameterized Refocusing Convolution (RefConv) as a replacement for regular convolutional layers, which is a plug-and-play module to improve the performance without any inference costs. Specifically, given a pre-trained model, RefConv applies a trainable Refocusing Transformation to the basis kernels inherited from the pre-trained model to establish connections among the parameters. For example, a depth-wise RefConv can relate the parameters of a specific channel of convolution kernel to the parameters of the other kernel, i.e., make them refocus on the other parts of the model they have never attended to, rather than focus on the input features only. From another perspective, RefConv augments the priors of existing model structures by utilizing the representations encoded in the pre-trained parameters as the priors and refocusing on them to learn novel representations, thus further enhancing the representational capacity of the pre-trained model. Experimental results validated that RefConv can improve multiple CNN-based models by a clear margin on image classification (up to 1.47% higher top-1 accuracy on ImageNet), object detection and semantic segmentation without introducing any extra inference costs or altering the original model structure. Further studies demonstrated that RefConv can reduce the redundancy of channels and smooth the loss landscape, which explains its effectiveness.
Towards Unified and Effective Domain Generalization
Oct 16, 2023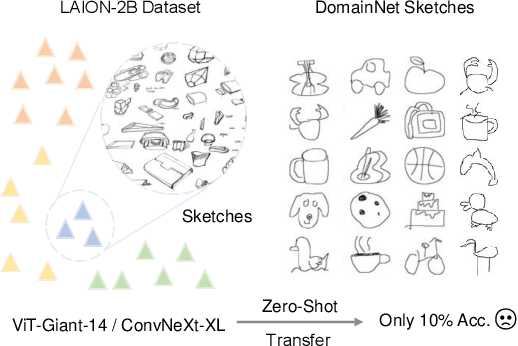
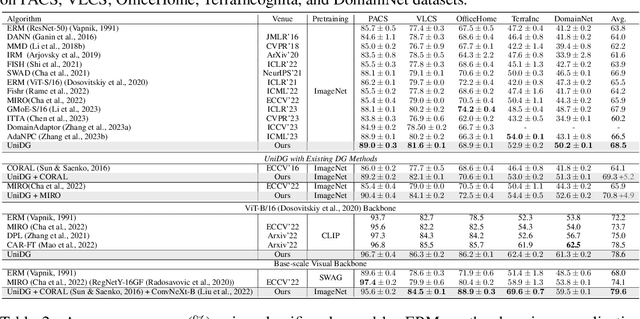
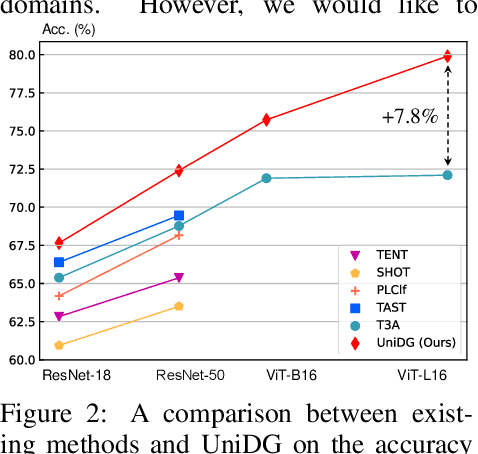
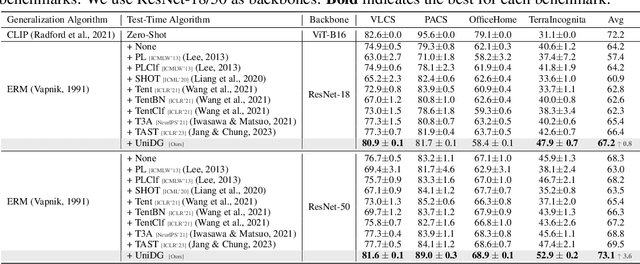
We propose $\textbf{UniDG}$, a novel and $\textbf{Uni}$fied framework for $\textbf{D}$omain $\textbf{G}$eneralization that is capable of significantly enhancing the out-of-distribution generalization performance of foundation models regardless of their architectures. The core idea of UniDG is to finetune models during the inference stage, which saves the cost of iterative training. Specifically, we encourage models to learn the distribution of test data in an unsupervised manner and impose a penalty regarding the updating step of model parameters. The penalty term can effectively reduce the catastrophic forgetting issue as we would like to maximally preserve the valuable knowledge in the original model. Empirically, across 12 visual backbones, including CNN-, MLP-, and Transformer-based models, ranging from 1.89M to 303M parameters, UniDG shows an average accuracy improvement of +5.4% on DomainBed. These performance results demonstrate the superiority and versatility of UniDG. The code is publicly available at https://github.com/invictus717/UniDG
Evolving Semantic Prototype Improves Generative Zero-Shot Learning
Jun 12, 2023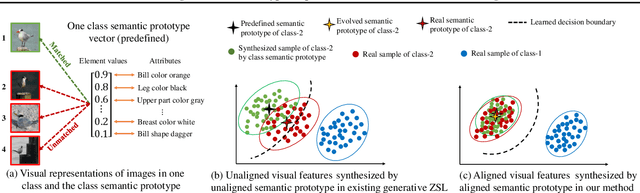
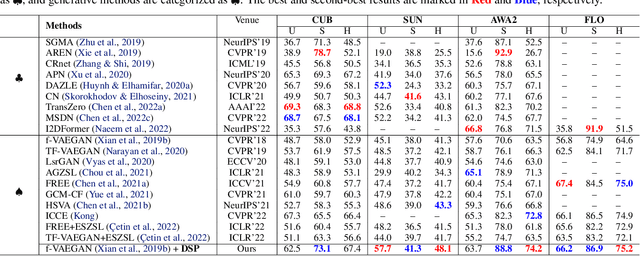
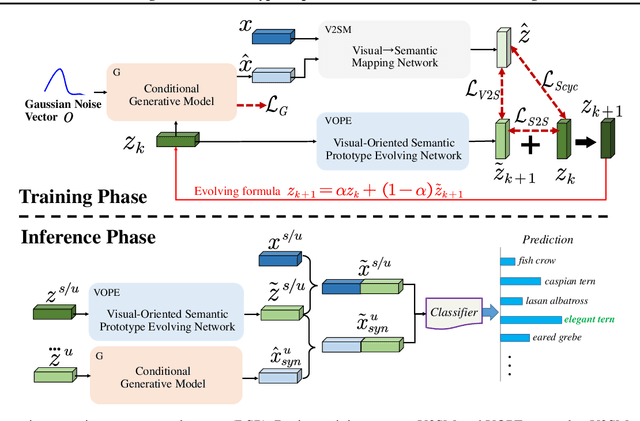
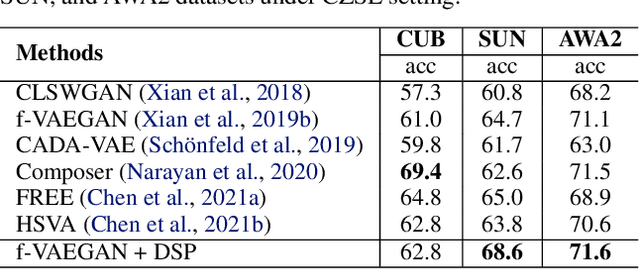
In zero-shot learning (ZSL), generative methods synthesize class-related sample features based on predefined semantic prototypes. They advance the ZSL performance by synthesizing unseen class sample features for better training the classifier. We observe that each class's predefined semantic prototype (also referred to as semantic embedding or condition) does not accurately match its real semantic prototype. So the synthesized visual sample features do not faithfully represent the real sample features, limiting the classifier training and existing ZSL performance. In this paper, we formulate this mismatch phenomenon as the visual-semantic domain shift problem. We propose a dynamic semantic prototype evolving (DSP) method to align the empirically predefined semantic prototypes and the real prototypes for class-related feature synthesis. The alignment is learned by refining sample features and semantic prototypes in a unified framework and making the synthesized visual sample features approach real sample features. After alignment, synthesized sample features from unseen classes are closer to the real sample features and benefit DSP to improve existing generative ZSL methods by 8.5\%, 8.0\%, and 9.7\% on the standard CUB, SUN AWA2 datasets, the significant performance improvement indicates that evolving semantic prototype explores a virgin field in ZSL.