 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSanyuan Zhao
InteractiveVideo: User-Centric Controllable Video Generation with Synergistic Multimodal Instructions
Feb 05, 2024
We introduce $\textit{InteractiveVideo}$, a user-centric framework for video generation. Different from traditional generative approaches that operate based on user-provided images or text, our framework is designed for dynamic interaction, allowing users to instruct the generative model through various intuitive mechanisms during the whole generation process, e.g. text and image prompts, painting, drag-and-drop, etc. We propose a Synergistic Multimodal Instruction mechanism, designed to seamlessly integrate users' multimodal instructions into generative models, thus facilitating a cooperative and responsive interaction between user inputs and the generative process. This approach enables iterative and fine-grained refinement of the generation result through precise and effective user instructions. With $\textit{InteractiveVideo}$, users are given the flexibility to meticulously tailor key aspects of a video. They can paint the reference image, edit semantics, and adjust video motions until their requirements are fully met. Code, models, and demo are available at https://github.com/invictus717/InteractiveVideo
TextFormer: A Query-based End-to-End Text Spotter with Mixed Supervision
Jun 06, 2023



End-to-end text spotting is a vital computer vision task that aims to integrate scene text detection and recognition into a unified framework. Typical methods heavily rely on Region-of-Interest (RoI) operations to extract local features and complex post-processing steps to produce final predictions. To address these limitations, we propose TextFormer, a query-based end-to-end text spotter with Transformer architecture. Specifically, using query embedding per text instance, TextFormer builds upon an image encoder and a text decoder to learn a joint semantic understanding for multi-task modeling. It allows for mutual training and optimization of classification, segmentation, and recognition branches, resulting in deeper feature sharing without sacrificing flexibility or simplicity. Additionally, we design an Adaptive Global aGgregation (AGG) module to transfer global features into sequential features for reading arbitrarily-shaped texts, which overcomes the sub-optimization problem of RoI operations. Furthermore, potential corpus information is utilized from weak annotations to full labels through mixed supervision, further improving text detection and end-to-end text spotting results. Extensive experiments on various bilingual (i.e., English and Chinese) benchmarks demonstrate the superiority of our method. Especially on TDA-ReCTS dataset, TextFormer surpasses the state-of-the-art method in terms of 1-NED by 13.2%.
Generalized Few-Shot 3D Object Detection of LiDAR Point Cloud for Autonomous Driving
Feb 08, 2023



Recent years have witnessed huge successes in 3D object detection to recognize common objects for autonomous driving (e.g., vehicles and pedestrians). However, most methods rely heavily on a large amount of well-labeled training data. This limits their capability of detecting rare fine-grained objects (e.g., police cars and ambulances), which is important for special cases, such as emergency rescue, and so on. To achieve simultaneous detection for both common and rare objects, we propose a novel task, called generalized few-shot 3D object detection, where we have a large amount of training data for common (base) objects, but only a few data for rare (novel) classes. Specifically, we analyze in-depth differences between images and point clouds, and then present a practical principle for the few-shot setting in the 3D LiDAR dataset. To solve this task, we propose a simple and effective detection framework, including (1) an incremental fine-tuning method to extend existing 3D detection models to recognize both common and rare objects, and (2) a sample adaptive balance loss to alleviate the issue of long-tailed data distribution in autonomous driving scenarios. On the nuScenes dataset, we conduct sufficient experiments to demonstrate that our approach can successfully detect the rare (novel) classes that contain only a few training data, while also maintaining the detection accuracy of common objects.
Bilateral Cross-Modality Graph Matching Attention for Feature Fusion in Visual Question Answering
Dec 14, 2021



Answering semantically-complicated questions according to an image is challenging in Visual Question Answering (VQA) task. Although the image can be well represented by deep learning, the question is always simply embedded and cannot well indicate its meaning. Besides, the visual and textual features have a gap for different modalities, it is difficult to align and utilize the cross-modality information. In this paper, we focus on these two problems and propose a Graph Matching Attention (GMA) network. Firstly, it not only builds graph for the image, but also constructs graph for the question in terms of both syntactic and embedding information. Next, we explore the intra-modality relationships by a dual-stage graph encoder and then present a bilateral cross-modality graph matching attention to infer the relationships between the image and the question. The updated cross-modality features are then sent into the answer prediction module for final answer prediction. Experiments demonstrate that our network achieves state-of-the-art performance on the GQA dataset and the VQA 2.0 dataset. The ablation studies verify the effectiveness of each modules in our GMA network.
Self-Learning with Rectification Strategy for Human Parsing
Apr 17, 2020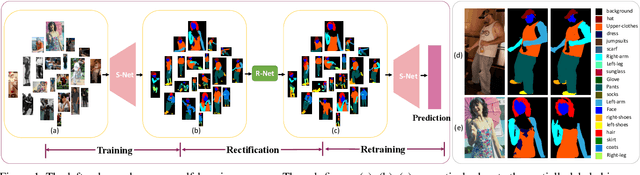
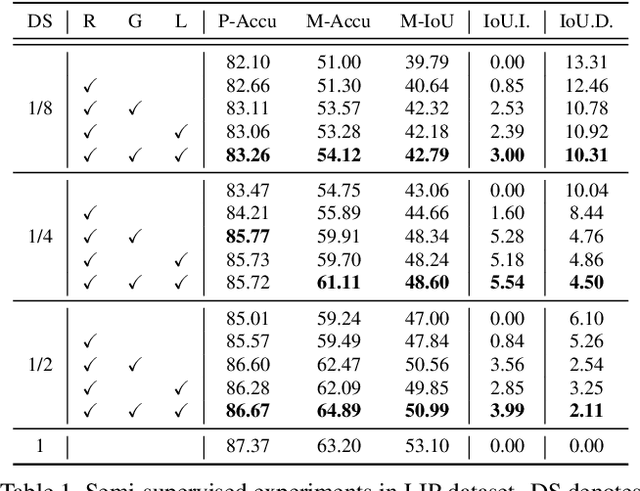
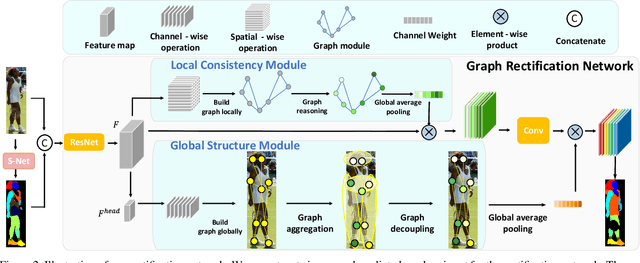

In this paper, we solve the sample shortage problem in the human parsing task. We begin with the self-learning strategy, which generates pseudo-labels for unlabeled data to retrain the model. However, directly using noisy pseudo-labels will cause error amplification and accumulation. Considering the topology structure of human body, we propose a trainable graph reasoning method that establishes internal structural connections between graph nodes to correct two typical errors in the pseudo-labels, i.e., the global structural error and the local consistency error. For the global error, we first transform category-wise features into a high-level graph model with coarse-grained structural information, and then decouple the high-level graph to reconstruct the category features. The reconstructed features have a stronger ability to represent the topology structure of the human body. Enlarging the receptive field of features can effectively reducing the local error. We first project feature pixels into a local graph model to capture pixel-wise relations in a hierarchical graph manner, then reverse the relation information back to the pixels. With the global structural and local consistency modules, these errors are rectified and confident pseudo-labels are generated for retraining. Extensive experiments on the LIP and the ATR datasets demonstrate the effectiveness of our global and local rectification modules. Our method outperforms other state-of-the-art methods in supervised human parsing tasks.
Improved Face Detection and Alignment using Cascade Deep Convolutional Network
Jul 28, 2017



Real-world face detection and alignment demand an advanced discriminative model to address challenges by pose, lighting and expression. Illuminated by the deep learning algorithm, some convolutional neural networks based face detection and alignment methods have been proposed. Recent studies have utilized the relation between face detection and alignment to make models computationally efficiency, however they ignore the connection between each cascade CNNs. In this paper, we propose an structure to propose higher quality training data for End-to-End cascade network training, which give computers more space to automatic adjust weight parameter and accelerate convergence. Experiments demonstrate considerable improvement over existing detection and alignment models.