 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaotong Zhang
HQA-Attack: Toward High Quality Black-Box Hard-Label Adversarial Attack on Text
Feb 02, 2024
Black-box hard-label adversarial attack on text is a practical and challenging task, as the text data space is inherently discrete and non-differentiable, and only the predicted label is accessible. Research on this problem is still in the embryonic stage and only a few methods are available. Nevertheless, existing methods rely on the complex heuristic algorithm or unreliable gradient estimation strategy, which probably fall into the local optimum and inevitably consume numerous queries, thus are difficult to craft satisfactory adversarial examples with high semantic similarity and low perturbation rate in a limited query budget. To alleviate above issues, we propose a simple yet effective framework to generate high quality textual adversarial examples under the black-box hard-label attack scenarios, named HQA-Attack. Specifically, after initializing an adversarial example randomly, HQA-attack first constantly substitutes original words back as many as possible, thus shrinking the perturbation rate. Then it leverages the synonym set of the remaining changed words to further optimize the adversarial example with the direction which can improve the semantic similarity and satisfy the adversarial condition simultaneously. In addition, during the optimizing procedure, it searches a transition synonym word for each changed word, thus avoiding traversing the whole synonym set and reducing the query number to some extent. Extensive experimental results on five text classification datasets, three natural language inference datasets and two real-world APIs have shown that the proposed HQA-Attack method outperforms other strong baselines significantly.
How Does Perception Affect Safety: New Metrics and Strategy
Dec 12, 2023Perception serves as a critical component in the functionality of autonomous agents. However, the intricate relationship between perception metrics and robotic metrics remains unclear, leading to ambiguity in the development and fine-tuning of perception algorithms. In this paper, we introduce a methodology for quantifying this relationship, taking into account factors such as detection rate, detection quality, and latency. Furthermore, we introduce two novel metrics for Human-Robot Collaboration safety predicated upon perception metrics: Critical Collision Probability (CCP) and Average Collision Probability (ACP). To validate the utility of these metrics in facilitating algorithm development and tuning, we develop an attentive processing strategy that focuses exclusively on key input features. This approach significantly reduces computational time while preserving a similar level of accuracy. Experimental results indicate that the implementation of this strategy in an object detector leads to a maximum reduction of 30.091% in inference time and 26.534% in total time per frame. Additionally, the strategy lowers the CCP and ACP in a baseline model by 11.252% and 13.501%, respectively. The source code will be made publicly available in the final proof version of the manuscript.
Boosting Decision-Based Black-Box Adversarial Attack with Gradient Priors
Oct 29, 2023
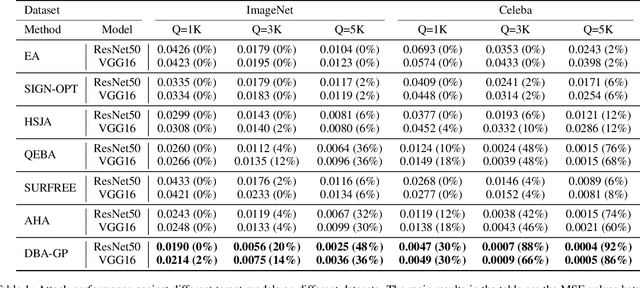
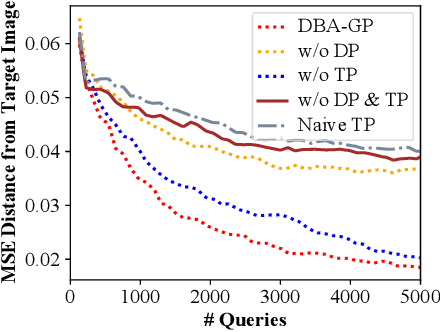
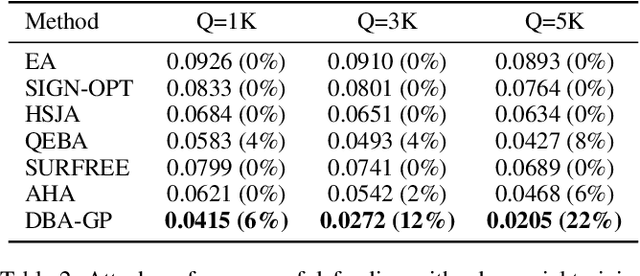
Decision-based methods have shown to be effective in black-box adversarial attacks, as they can obtain satisfactory performance and only require to access the final model prediction. Gradient estimation is a critical step in black-box adversarial attacks, as it will directly affect the query efficiency. Recent works have attempted to utilize gradient priors to facilitate score-based methods to obtain better results. However, these gradient priors still suffer from the edge gradient discrepancy issue and the successive iteration gradient direction issue, thus are difficult to simply extend to decision-based methods. In this paper, we propose a novel Decision-based Black-box Attack framework with Gradient Priors (DBA-GP), which seamlessly integrates the data-dependent gradient prior and time-dependent prior into the gradient estimation procedure. First, by leveraging the joint bilateral filter to deal with each random perturbation, DBA-GP can guarantee that the generated perturbations in edge locations are hardly smoothed, i.e., alleviating the edge gradient discrepancy, thus remaining the characteristics of the original image as much as possible. Second, by utilizing a new gradient updating strategy to automatically adjust the successive iteration gradient direction, DBA-GP can accelerate the convergence speed, thus improving the query efficiency. Extensive experiments have demonstrated that the proposed method outperforms other strong baselines significantly.
Enhanced Human-Robot Collaboration using Constrained Probabilistic Human-Motion Prediction
Oct 05, 2023Human motion prediction is an essential step for efficient and safe human-robot collaboration. Current methods either purely rely on representing the human joints in some form of neural network-based architecture or use regression models offline to fit hyper-parameters in the hope of capturing a model encompassing human motion. While these methods provide good initial results, they are missing out on leveraging well-studied human body kinematic models as well as body and scene constraints which can help boost the efficacy of these prediction frameworks while also explicitly avoiding implausible human joint configurations. We propose a novel human motion prediction framework that incorporates human joint constraints and scene constraints in a Gaussian Process Regression (GPR) model to predict human motion over a set time horizon. This formulation is combined with an online context-aware constraints model to leverage task-dependent motions. It is tested on a human arm kinematic model and implemented on a human-robot collaborative setup with a UR5 robot arm to demonstrate the real-time capability of our approach. Simulations were also performed on datasets like HA4M and ANDY. The simulation and experimental results demonstrate considerable improvements in a Gaussian Process framework when these constraints are explicitly considered.
Boosting Few-Shot Text Classification via Distribution Estimation
Mar 26, 2023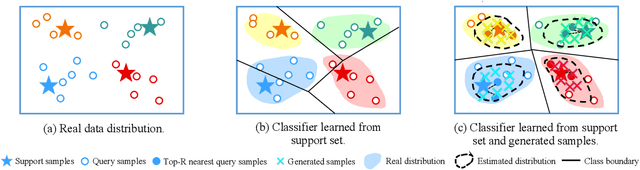
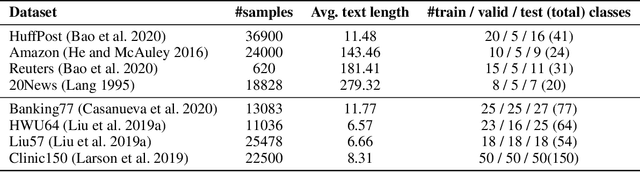


Distribution estimation has been demonstrated as one of the most effective approaches in dealing with few-shot image classification, as the low-level patterns and underlying representations can be easily transferred across different tasks in computer vision domain. However, directly applying this approach to few-shot text classification is challenging, since leveraging the statistics of known classes with sufficient samples to calibrate the distributions of novel classes may cause negative effects due to serious category difference in text domain. To alleviate this issue, we propose two simple yet effective strategies to estimate the distributions of the novel classes by utilizing unlabeled query samples, thus avoiding the potential negative transfer issue. Specifically, we first assume a class or sample follows the Gaussian distribution, and use the original support set and the nearest few query samples to estimate the corresponding mean and covariance. Then, we augment the labeled samples by sampling from the estimated distribution, which can provide sufficient supervision for training the classification model. Extensive experiments on eight few-shot text classification datasets show that the proposed method outperforms state-of-the-art baselines significantly.
A Simple Meta-learning Paradigm for Zero-shot Intent Classification with Mixture Attention Mechanism
Jun 05, 2022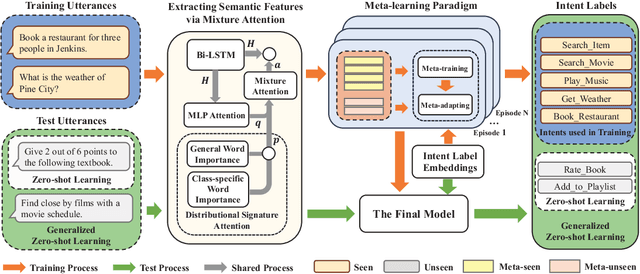


Zero-shot intent classification is a vital and challenging task in dialogue systems, which aims to deal with numerous fast-emerging unacquainted intents without annotated training data. To obtain more satisfactory performance, the crucial points lie in two aspects: extracting better utterance features and strengthening the model generalization ability. In this paper, we propose a simple yet effective meta-learning paradigm for zero-shot intent classification. To learn better semantic representations for utterances, we introduce a new mixture attention mechanism, which encodes the pertinent word occurrence patterns by leveraging the distributional signature attention and multi-layer perceptron attention simultaneously. To strengthen the transfer ability of the model from seen classes to unseen classes, we reformulate zero-shot intent classification with a meta-learning strategy, which trains the model by simulating multiple zero-shot classification tasks on seen categories, and promotes the model generalization ability with a meta-adapting procedure on mimic unseen categories. Extensive experiments on two real-world dialogue datasets in different languages show that our model outperforms other strong baselines on both standard and generalized zero-shot intent classification tasks.
Modeling User Behavior with Graph Convolution for Personalized Product Search
Feb 12, 2022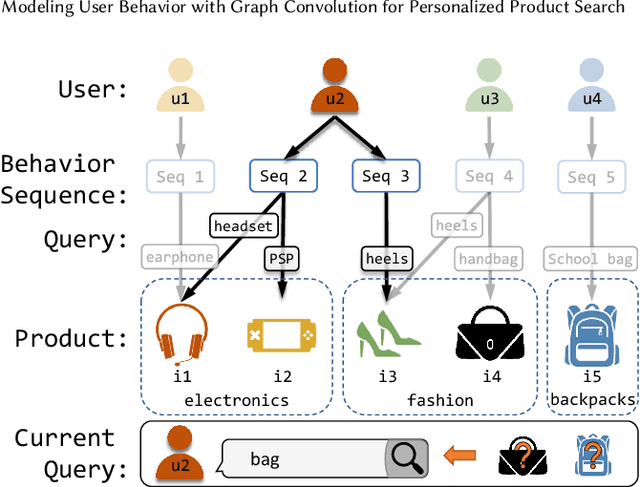
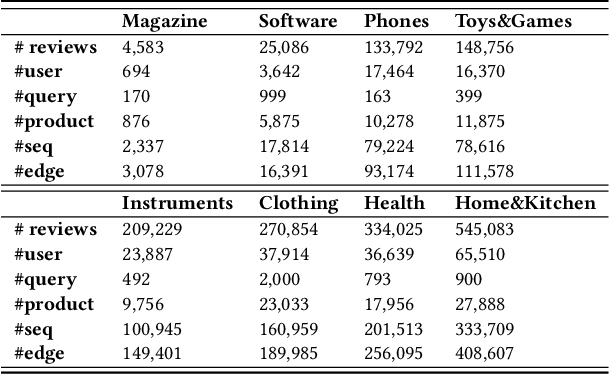
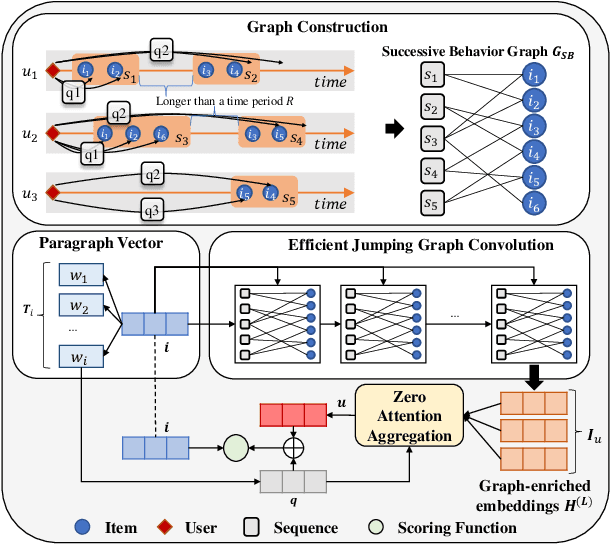
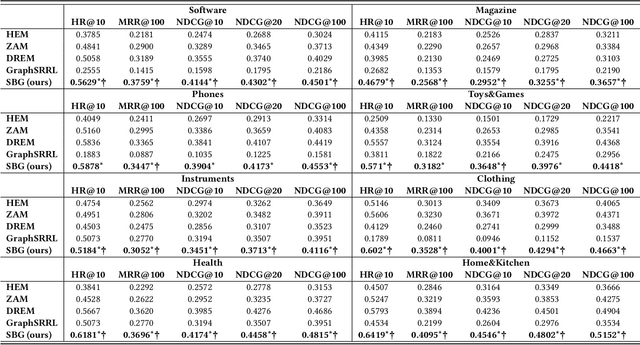
User preference modeling is a vital yet challenging problem in personalized product search. In recent years, latent space based methods have achieved state-of-the-art performance by jointly learning semantic representations of products, users, and text tokens. However, existing methods are limited in their ability to model user preferences. They typically represent users by the products they visited in a short span of time using attentive models and lack the ability to exploit relational information such as user-product interactions or item co-occurrence relations. In this work, we propose to address the limitations of prior arts by exploring local and global user behavior patterns on a user successive behavior graph, which is constructed by utilizing short-term actions of all users. To capture implicit user preference signals and collaborative patterns, we use an efficient jumping graph convolution to explore high-order relations to enrich product representations for user preference modeling. Our approach can be seamlessly integrated with existing latent space based methods and be potentially applied in any product retrieval method that uses purchase history to model user preferences. Extensive experiments on eight Amazon benchmarks demonstrate the effectiveness and potential of our approach. The source code is available at \url{https://github.com/floatSDSDS/SBG}.
An Explicit-Joint and Supervised-Contrastive Learning Framework for Few-Shot Intent Classification and Slot Filling
Oct 26, 2021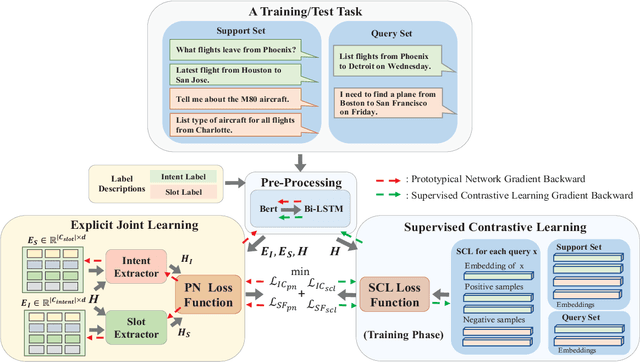
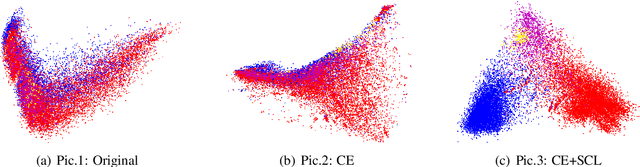
Intent classification (IC) and slot filling (SF) are critical building blocks in task-oriented dialogue systems. These two tasks are closely-related and can flourish each other. Since only a few utterances can be utilized for identifying fast-emerging new intents and slots, data scarcity issue often occurs when implementing IC and SF. However, few IC/SF models perform well when the number of training samples per class is quite small. In this paper, we propose a novel explicit-joint and supervised-contrastive learning framework for few-shot intent classification and slot filling. Its highlights are as follows. (i) The model extracts intent and slot representations via bidirectional interactions, and extends prototypical network to achieve explicit-joint learning, which guarantees that IC and SF tasks can mutually reinforce each other. (ii) The model integrates with supervised contrastive learning, which ensures that samples from same class are pulled together and samples from different classes are pushed apart. In addition, the model follows a not common but practical way to construct the episode, which gets rid of the traditional setting with fixed way and shot, and allows for unbalanced datasets. Extensive experiments on three public datasets show that our model can achieve promising performance.
Attributed Graph Learning with 2-D Graph Convolution
Sep 27, 2019
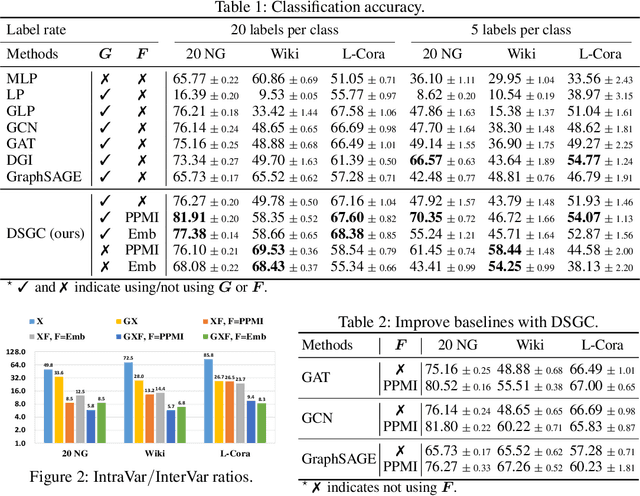

Graph convolutional neural networks have demonstrated promising performance in attributed graph learning, thanks to the use of graph convolution that effectively combines graph structures and node features for learning node representations. However, one intrinsic limitation of the commonly adopted 1-D graph convolution is that it only exploits graph connectivity for feature smoothing, which may lead to inferior performance on sparse and noisy real-world attributed networks. To address this problem, we propose to explore relational information among node attributes to complement node relations for representation learning. In particular, we propose to use 2-D graph convolution to jointly model the two kinds of relations and develop a computationally efficient dimensionwise separable 2-D graph convolution (DSGC). Theoretically, we show that DSGC can reduce intra-class variance of node features on both the node dimension and the attribute dimension to facilitate learning. Empirically, we demonstrate that by incorporating attribute relations, DSGC achieves significant performance gain over state-of-the-art methods on node classification and clustering on several real-world attributed networks.
Clustering Uncertain Data via Representative Possible Worlds with Consistency Learning
Sep 27, 2019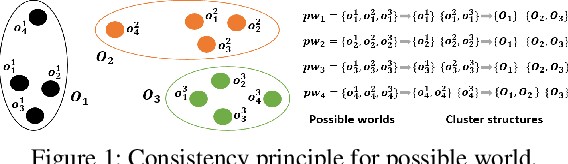
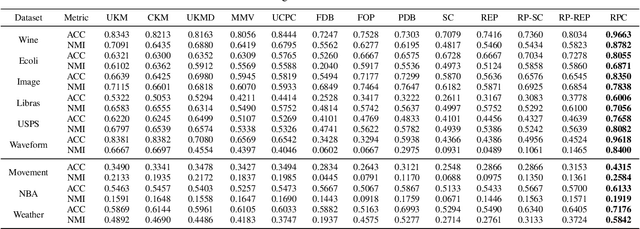
Clustering uncertain data is an essential task in data mining for the internet of things. Possible world based algorithms seem promising for clustering uncertain data. However, there are two issues in existing possible world based algorithms: (1) They rely on all the possible worlds and treat them equally, but some marginal possible worlds may cause negative effects. (2) They do not well utilize the consistency among possible worlds, since they conduct clustering or construct the affinity matrix on each possible world independently. In this paper, we propose a representative possible world based consistent clustering (RPC) algorithm for uncertain data. First, by introducing representative loss and using Jensen-Shannon divergence as the distribution measure, we design a heuristic strategy for the selection of representative possible worlds, thus avoiding the negative effects caused by marginal possible worlds. Second, we integrate a consistency learning procedure into spectral clustering to deal with the representative possible worlds synergistically, thus utilizing the consistency to achieve better performance. Experimental results show that our proposed algorithm performs better than the state-of-the-art algorithms.