 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimon Stepputtis
Sigma: Siamese Mamba Network for Multi-Modal Semantic Segmentation
Apr 05, 2024
Multi-modal semantic segmentation significantly enhances AI agents' perception and scene understanding, especially under adverse conditions like low-light or overexposed environments. Leveraging additional modalities (X-modality) like thermal and depth alongside traditional RGB provides complementary information, enabling more robust and reliable segmentation. In this work, we introduce Sigma, a Siamese Mamba network for multi-modal semantic segmentation, utilizing the Selective Structured State Space Model, Mamba. Unlike conventional methods that rely on CNNs, with their limited local receptive fields, or Vision Transformers (ViTs), which offer global receptive fields at the cost of quadratic complexity, our model achieves global receptive fields coverage with linear complexity. By employing a Siamese encoder and innovating a Mamba fusion mechanism, we effectively select essential information from different modalities. A decoder is then developed to enhance the channel-wise modeling ability of the model. Our method, Sigma, is rigorously evaluated on both RGB-Thermal and RGB-Depth segmentation tasks, demonstrating its superiority and marking the first successful application of State Space Models (SSMs) in multi-modal perception tasks. Code is available at https://github.com/zifuwan/Sigma.
ShapeGrasp: Zero-Shot Task-Oriented Grasping with Large Language Models through Geometric Decomposition
Mar 26, 2024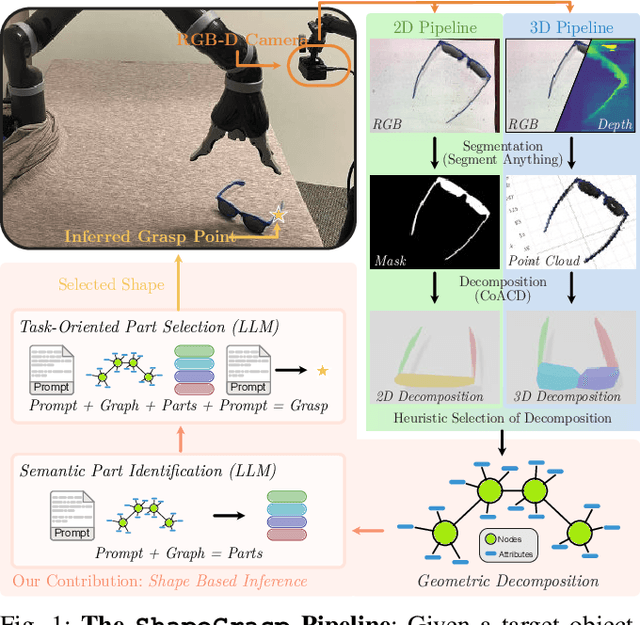

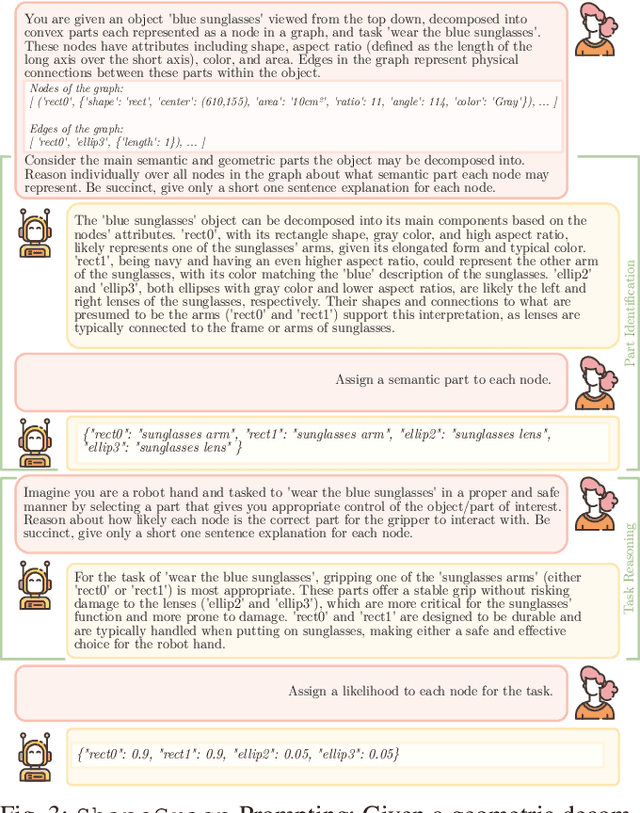

Task-oriented grasping of unfamiliar objects is a necessary skill for robots in dynamic in-home environments. Inspired by the human capability to grasp such objects through intuition about their shape and structure, we present a novel zero-shot task-oriented grasping method leveraging a geometric decomposition of the target object into simple, convex shapes that we represent in a graph structure, including geometric attributes and spatial relationships. Our approach employs minimal essential information - the object's name and the intended task - to facilitate zero-shot task-oriented grasping. We utilize the commonsense reasoning capabilities of large language models to dynamically assign semantic meaning to each decomposed part and subsequently reason over the utility of each part for the intended task. Through extensive experiments on a real-world robotics platform, we demonstrate that our grasping approach's decomposition and reasoning pipeline is capable of selecting the correct part in 92% of the cases and successfully grasping the object in 82% of the tasks we evaluate. Additional videos, experiments, code, and data are available on our project website: https://shapegrasp.github.io/.
Negative Yields Positive: Unified Dual-Path Adapter for Vision-Language Models
Mar 19, 2024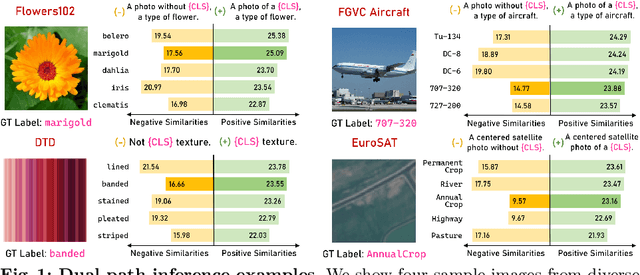

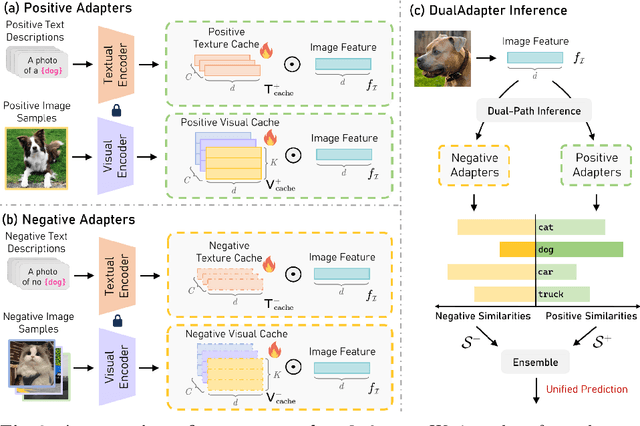
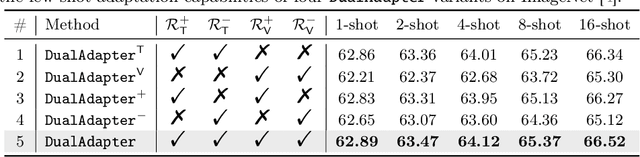
Recently, large-scale pre-trained Vision-Language Models (VLMs) have demonstrated great potential in learning open-world visual representations, and exhibit remarkable performance across a wide range of downstream tasks through efficient fine-tuning. In this work, we innovatively introduce the concept of dual learning into fine-tuning VLMs, i.e., we not only learn what an image is, but also what an image isn't. Building on this concept, we introduce a novel DualAdapter approach to enable dual-path adaptation of VLMs from both positive and negative perspectives with only limited annotated samples. In the inference stage, our DualAdapter performs unified predictions by simultaneously conducting complementary positive selection and negative exclusion across target classes, thereby enhancing the overall recognition accuracy of VLMs in downstream tasks. Our extensive experimental results across 15 datasets validate that the proposed DualAdapter outperforms existing state-of-the-art methods on both few-shot learning and domain generalization tasks while achieving competitive computational efficiency. Code is available at https://github.com/zhangce01/DualAdapter.
HiKER-SGG: Hierarchical Knowledge Enhanced Robust Scene Graph Generation
Mar 18, 2024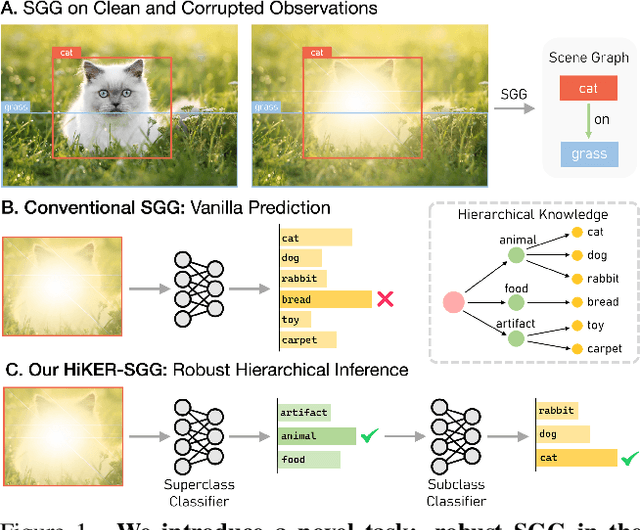
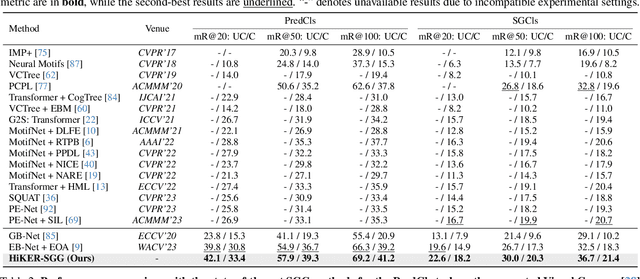
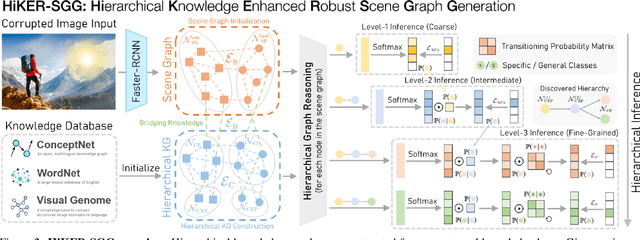
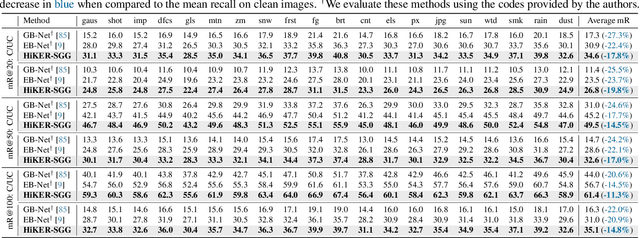
Being able to understand visual scenes is a precursor for many downstream tasks, including autonomous driving, robotics, and other vision-based approaches. A common approach enabling the ability to reason over visual data is Scene Graph Generation (SGG); however, many existing approaches assume undisturbed vision, i.e., the absence of real-world corruptions such as fog, snow, smoke, as well as non-uniform perturbations like sun glare or water drops. In this work, we propose a novel SGG benchmark containing procedurally generated weather corruptions and other transformations over the Visual Genome dataset. Further, we introduce a corresponding approach, Hierarchical Knowledge Enhanced Robust Scene Graph Generation (HiKER-SGG), providing a strong baseline for scene graph generation under such challenging setting. At its core, HiKER-SGG utilizes a hierarchical knowledge graph in order to refine its predictions from coarse initial estimates to detailed predictions. In our extensive experiments, we show that HiKER-SGG does not only demonstrate superior performance on corrupted images in a zero-shot manner, but also outperforms current state-of-the-art methods on uncorrupted SGG tasks. Code is available at https://github.com/zhangce01/HiKER-SGG.
Benchmarking and Enhancing Disentanglement in Concept-Residual Models
Nov 30, 2023Concept bottleneck models (CBMs) are interpretable models that first predict a set of semantically meaningful features, i.e., concepts, from observations that are subsequently used to condition a downstream task. However, the model's performance strongly depends on the engineered features and can severely suffer from incomplete sets of concepts. Prior works have proposed a side channel -- a residual -- that allows for unconstrained information flow to the downstream task, thus improving model performance but simultaneously introducing information leakage, which is undesirable for interpretability. This work proposes three novel approaches to mitigate information leakage by disentangling concepts and residuals, investigating the critical balance between model performance and interpretability. Through extensive empirical analysis on the CUB, OAI, and CIFAR 100 datasets, we assess the performance of each disentanglement method and provide insights into when they work best. Further, we show how each method impacts the ability to intervene over the concepts and their subsequent impact on task performance.
Understanding Your Agent: Leveraging Large Language Models for Behavior Explanation
Nov 29, 2023Intelligent agents such as robots are increasingly deployed in real-world, safety-critical settings. It is vital that these agents are able to explain the reasoning behind their decisions to human counterparts; however, their behavior is often produced by uninterpretable models such as deep neural networks. We propose an approach to generate natural language explanations for an agent's behavior based only on observations of states and actions, thus making our method independent from the underlying model's representation. For such models, we first learn a behavior representation and subsequently use it to produce plausible explanations with minimal hallucination while affording user interaction with a pre-trained large language model. We evaluate our method in a multi-agent search-and-rescue environment and demonstrate the effectiveness of our explanations for agents executing various behaviors. Through user studies and empirical experiments, we show that our approach generates explanations as helpful as those produced by a human domain expert while enabling beneficial interactions such as clarification and counterfactual queries.
Long-Horizon Dialogue Understanding for Role Identification in the Game of Avalon with Large Language Models
Nov 09, 2023Deception and persuasion play a critical role in long-horizon dialogues between multiple parties, especially when the interests, goals, and motivations of the participants are not aligned. Such complex tasks pose challenges for current Large Language Models (LLM) as deception and persuasion can easily mislead them, especially in long-horizon multi-party dialogues. To this end, we explore the game of Avalon: The Resistance, a social deduction game in which players must determine each other's hidden identities to complete their team's objective. We introduce an online testbed and a dataset containing 20 carefully collected and labeled games among human players that exhibit long-horizon deception in a cooperative-competitive setting. We discuss the capabilities of LLMs to utilize deceptive long-horizon conversations between six human players to determine each player's goal and motivation. Particularly, we discuss the multimodal integration of the chat between the players and the game's state that grounds the conversation, providing further insights into the true player identities. We find that even current state-of-the-art LLMs do not reach human performance, making our dataset a compelling benchmark to investigate the decision-making and language-processing capabilities of LLMs. Our dataset and online testbed can be found at our project website: https://sstepput.github.io/Avalon-NLU/
Theory of Mind for Multi-Agent Collaboration via Large Language Models
Oct 22, 2023While Large Language Models (LLMs) have demonstrated impressive accomplishments in both reasoning and planning, their abilities in multi-agent collaborations remains largely unexplored. This study evaluates LLM-based agents in a multi-agent cooperative text game with Theory of Mind (ToM) inference tasks, comparing their performance with Multi-Agent Reinforcement Learning (MARL) and planning-based baselines. We observed evidence of emergent collaborative behaviors and high-order Theory of Mind capabilities among LLM-based agents. Our results reveal limitations in LLM-based agents' planning optimization due to systematic failures in managing long-horizon contexts and hallucination about the task state. We explore the use of explicit belief state representations to mitigate these issues, finding that it enhances task performance and the accuracy of ToM inferences for LLM-based agents.
Explaining Agent Behavior with Large Language Models
Sep 19, 2023Intelligent agents such as robots are increasingly deployed in real-world, safety-critical settings. It is vital that these agents are able to explain the reasoning behind their decisions to human counterparts, however, their behavior is often produced by uninterpretable models such as deep neural networks. We propose an approach to generate natural language explanations for an agent's behavior based only on observations of states and actions, agnostic to the underlying model representation. We show how a compact representation of the agent's behavior can be learned and used to produce plausible explanations with minimal hallucination while affording user interaction with a pre-trained large language model. Through user studies and empirical experiments, we show that our approach generates explanations as helpful as those generated by a human domain expert while enabling beneficial interactions such as clarification and counterfactual queries.
Knowledge-Guided Short-Context Action Anticipation in Human-Centric Videos
Sep 12, 2023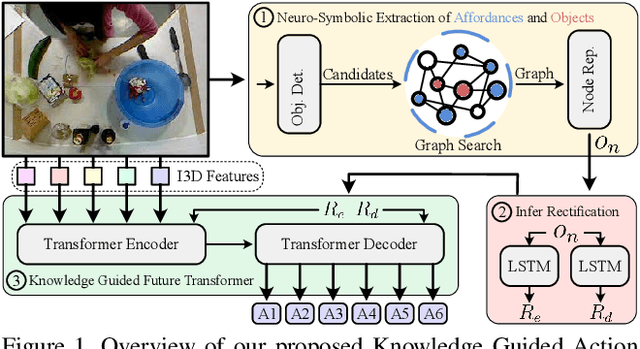
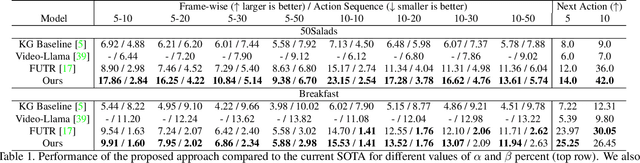


This work focuses on anticipating long-term human actions, particularly using short video segments, which can speed up editing workflows through improved suggestions while fostering creativity by suggesting narratives. To this end, we imbue a transformer network with a symbolic knowledge graph for action anticipation in video segments by boosting certain aspects of the transformer's attention mechanism at run-time. Demonstrated on two benchmark datasets, Breakfast and 50Salads, our approach outperforms current state-of-the-art methods for long-term action anticipation using short video context by up to 9%.