 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLantao Hu
A Model-based Multi-Agent Personalized Short-Video Recommender System
May 03, 2024
Recommender selects and presents top-K items to the user at each online request, and a recommendation session consists of several sequential requests. Formulating a recommendation session as a Markov decision process and solving it by reinforcement learning (RL) framework has attracted increasing attention from both academic and industry communities. In this paper, we propose a RL-based industrial short-video recommender ranking framework, which models and maximizes user watch-time in an environment of user multi-aspect preferences by a collaborative multi-agent formulization. Moreover, our proposed framework adopts a model-based learning approach to alleviate the sample selection bias which is a crucial but intractable problem in industrial recommender system. Extensive offline evaluations and live experiments confirm the effectiveness of our proposed method over alternatives. Our proposed approach has been deployed in our real large-scale short-video sharing platform, successfully serving over hundreds of millions users.
M3oE: Multi-Domain Multi-Task Mixture-of Experts Recommendation Framework
Apr 29, 2024Multi-domain recommendation and multi-task recommendation have demonstrated their effectiveness in leveraging common information from different domains and objectives for comprehensive user modeling. Nonetheless, the practical recommendation usually faces multiple domains and tasks simultaneously, which cannot be well-addressed by current methods. To this end, we introduce M3oE, an adaptive multi-domain multi-task mixture-of-experts recommendation framework. M3oE integrates multi-domain information, maps knowledge across domains and tasks, and optimizes multiple objectives. We leverage three mixture-of-experts modules to learn common, domain-aspect, and task-aspect user preferences respectively to address the complex dependencies among multiple domains and tasks in a disentangled manner. Additionally, we design a two-level fusion mechanism for precise control over feature extraction and fusion across diverse domains and tasks. The framework's adaptability is further enhanced by applying AutoML technique, which allows dynamic structure optimization. To the best of the authors' knowledge, our M3oE is the first effort to solve multi-domain multi-task recommendation self-adaptively. Extensive experiments on two benchmark datasets against diverse baselines demonstrate M3oE's superior performance. The implementation code is available to ensure reproducibility.
RecGPT: Generative Personalized Prompts for Sequential Recommendation via ChatGPT Training Paradigm
Apr 06, 2024ChatGPT has achieved remarkable success in natural language understanding. Considering that recommendation is indeed a conversation between users and the system with items as words, which has similar underlying pattern with ChatGPT, we design a new chat framework in item index level for the recommendation task. Our novelty mainly contains three parts: model, training and inference. For the model part, we adopt Generative Pre-training Transformer (GPT) as the sequential recommendation model and design a user modular to capture personalized information. For the training part, we adopt the two-stage paradigm of ChatGPT, including pre-training and fine-tuning. In the pre-training stage, we train GPT model by auto-regression. In the fine-tuning stage, we train the model with prompts, which include both the newly-generated results from the model and the user's feedback. For the inference part, we predict several user interests as user representations in an autoregressive manner. For each interest vector, we recall several items with the highest similarity and merge the items recalled by all interest vectors into the final result. We conduct experiments with both offline public datasets and online A/B test to demonstrate the effectiveness of our proposed method.
Sequential Recommendation for Optimizing Both Immediate Feedback and Long-term Retention
Apr 04, 2024In the landscape of Recommender System (RS) applications, reinforcement learning (RL) has recently emerged as a powerful tool, primarily due to its proficiency in optimizing long-term rewards. Nevertheless, it suffers from instability in the learning process, stemming from the intricate interactions among bootstrapping, off-policy training, and function approximation. Moreover, in multi-reward recommendation scenarios, designing a proper reward setting that reconciles the inner dynamics of various tasks is quite intricate. In response to these challenges, we introduce DT4IER, an advanced decision transformer-based recommendation model that is engineered to not only elevate the effectiveness of recommendations but also to achieve a harmonious balance between immediate user engagement and long-term retention. The DT4IER applies an innovative multi-reward design that adeptly balances short and long-term rewards with user-specific attributes, which serve to enhance the contextual richness of the reward sequence ensuring a more informed and personalized recommendation process. To enhance its predictive capabilities, DT4IER incorporates a high-dimensional encoder, skillfully designed to identify and leverage the intricate interrelations across diverse tasks. Furthermore, we integrate a contrastive learning approach within the action embedding predictions, a strategy that significantly boosts the model's overall performance. Experiments on three real-world datasets demonstrate the effectiveness of DT4IER against state-of-the-art Sequential Recommender Systems (SRSs) and Multi-Task Learning (MTL) models in terms of both prediction accuracy and effectiveness in specific tasks. The source code is accessible online to facilitate replication
Future Impact Decomposition in Request-level Recommendations
Feb 07, 2024In recommender systems, reinforcement learning solutions have shown promising results in optimizing the interaction sequence between users and the system over the long-term performance. For practical reasons, the policy's actions are typically designed as recommending a list of items to handle users' frequent and continuous browsing requests more efficiently. In this list-wise recommendation scenario, the user state is updated upon every request in the corresponding MDP formulation. However, this request-level formulation is essentially inconsistent with the user's item-level behavior. In this study, we demonstrate that an item-level optimization approach can better utilize item characteristics and optimize the policy's performance even under the request-level MDP. We support this claim by comparing the performance of standard request-level methods with the proposed item-level actor-critic framework in both simulation and online experiments. Furthermore, we show that a reward-based future decomposition strategy can better express the item-wise future impact and improve the recommendation accuracy in the long term. To achieve a more thorough understanding of the decomposition strategy, we propose a model-based re-weighting framework with adversarial learning that further boost the performance and investigate its correlation with the reward-based strategy.
AdaRec: Adaptive Sequential Recommendation for Reinforcing Long-term User Engagement
Oct 06, 2023

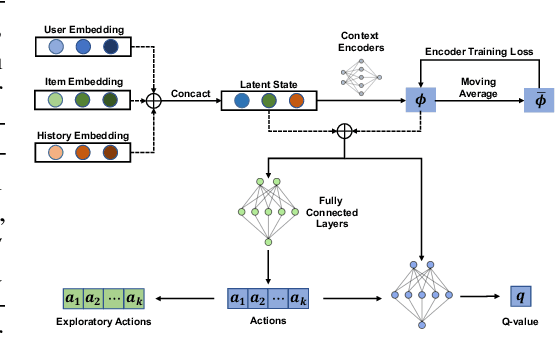
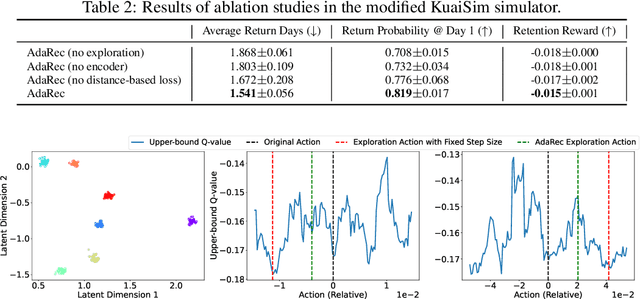
Growing attention has been paid to Reinforcement Learning (RL) algorithms when optimizing long-term user engagement in sequential recommendation tasks. One challenge in large-scale online recommendation systems is the constant and complicated changes in users' behavior patterns, such as interaction rates and retention tendencies. When formulated as a Markov Decision Process (MDP), the dynamics and reward functions of the recommendation system are continuously affected by these changes. Existing RL algorithms for recommendation systems will suffer from distribution shift and struggle to adapt in such an MDP. In this paper, we introduce a novel paradigm called Adaptive Sequential Recommendation (AdaRec) to address this issue. AdaRec proposes a new distance-based representation loss to extract latent information from users' interaction trajectories. Such information reflects how RL policy fits to current user behavior patterns, and helps the policy to identify subtle changes in the recommendation system. To make rapid adaptation to these changes, AdaRec encourages exploration with the idea of optimism under uncertainty. The exploration is further guarded by zero-order action optimization to ensure stable recommendation quality in complicated environments. We conduct extensive empirical analyses in both simulator-based and live sequential recommendation tasks, where AdaRec exhibits superior long-term performance compared to all baseline algorithms.
A Large Language Model Enhanced Conversational Recommender System
Aug 11, 2023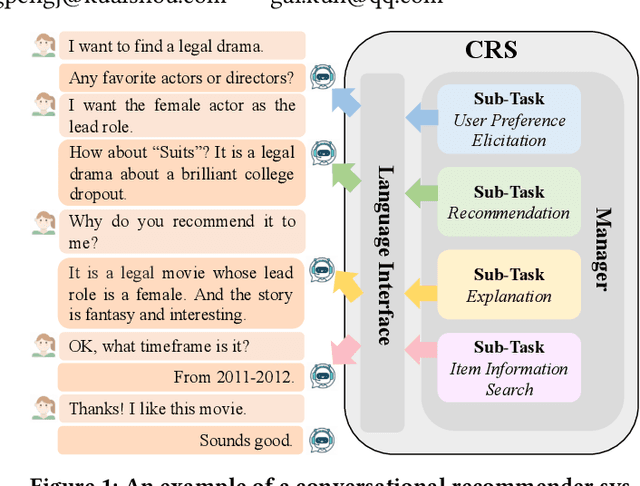
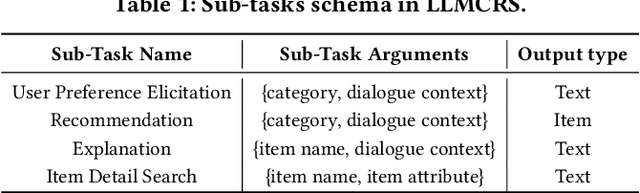
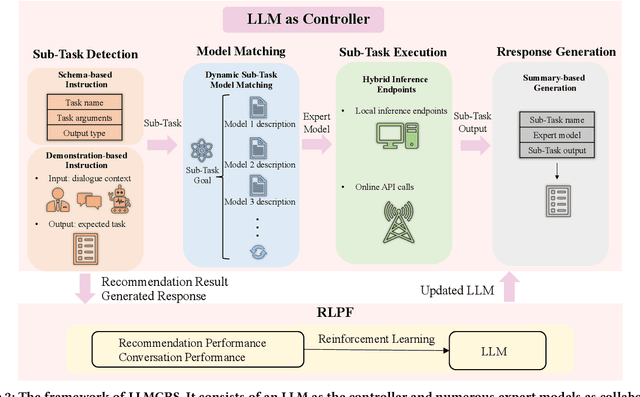

Conversational recommender systems (CRSs) aim to recommend high-quality items to users through a dialogue interface. It usually contains multiple sub-tasks, such as user preference elicitation, recommendation, explanation, and item information search. To develop effective CRSs, there are some challenges: 1) how to properly manage sub-tasks; 2) how to effectively solve different sub-tasks; and 3) how to correctly generate responses that interact with users. Recently, Large Language Models (LLMs) have exhibited an unprecedented ability to reason and generate, presenting a new opportunity to develop more powerful CRSs. In this work, we propose a new LLM-based CRS, referred to as LLMCRS, to address the above challenges. For sub-task management, we leverage the reasoning ability of LLM to effectively manage sub-task. For sub-task solving, we collaborate LLM with expert models of different sub-tasks to achieve the enhanced performance. For response generation, we utilize the generation ability of LLM as a language interface to better interact with users. Specifically, LLMCRS divides the workflow into four stages: sub-task detection, model matching, sub-task execution, and response generation. LLMCRS also designs schema-based instruction, demonstration-based instruction, dynamic sub-task and model matching, and summary-based generation to instruct LLM to generate desired results in the workflow. Finally, to adapt LLM to conversational recommendations, we also propose to fine-tune LLM with reinforcement learning from CRSs performance feedback, referred to as RLPF. Experimental results on benchmark datasets show that LLMCRS with RLPF outperforms the existing methods.