 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHongyu Hè
PerOS: Personalized Self-Adapting Operating Systems in the Cloud
Mar 26, 2024
Operating systems (OSes) are foundational to computer systems, managing hardware resources and ensuring secure environments for diverse applications. However, despite their enduring importance, the fundamental design objectives of OSes have seen minimal evolution over decades. Traditionally prioritizing aspects like speed, memory efficiency, security, and scalability, these objectives often overlook the crucial aspect of intelligence as well as personalized user experience. The lack of intelligence becomes increasingly critical amid technological revolutions, such as the remarkable advancements in machine learning (ML). Today's personal devices, evolving into intimate companions for users, pose unique challenges for traditional OSes like Linux and iOS, especially with the emergence of specialized hardware featuring heterogeneous components. Furthermore, the rise of large language models (LLMs) in ML has introduced transformative capabilities, reshaping user interactions and software development paradigms. While existing literature predominantly focuses on leveraging ML methods for system optimization or accelerating ML workloads, there is a significant gap in addressing personalized user experiences at the OS level. To tackle this challenge, this work proposes PerOS, a personalized OS ingrained with LLM capabilities. PerOS aims to provide tailored user experiences while safeguarding privacy and personal data through declarative interfaces, self-adaptive kernels, and secure data management in a scalable cloud-centric architecture; therein lies the main research question of this work: How can we develop intelligent, secure, and scalable OSes that deliver personalized experiences to thousands of users?
MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
Mar 22, 2024
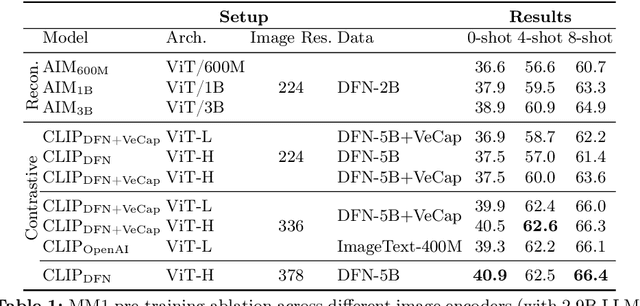
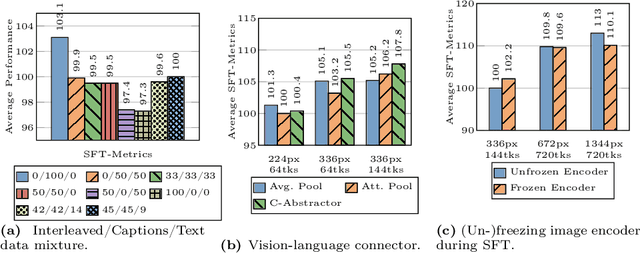
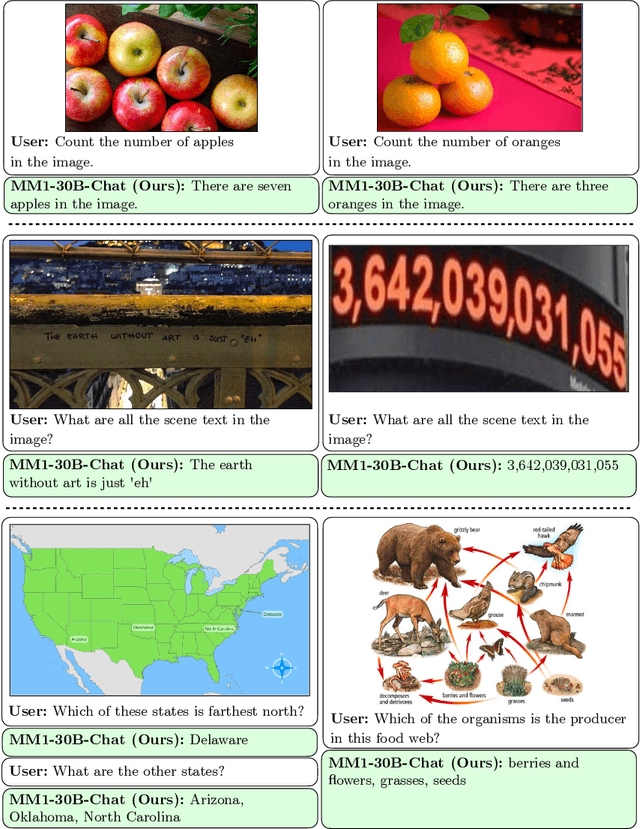
In this work, we discuss building performant Multimodal Large Language Models (MLLMs). In particular, we study the importance of various architecture components and data choices. Through careful and comprehensive ablations of the image encoder, the vision language connector, and various pre-training data choices, we identified several crucial design lessons. For example, we demonstrate that for large-scale multimodal pre-training using a careful mix of image-caption, interleaved image-text, and text-only data is crucial for achieving state-of-the-art (SOTA) few-shot results across multiple benchmarks, compared to other published pre-training results. Further, we show that the image encoder together with image resolution and the image token count has substantial impact, while the vision-language connector design is of comparatively negligible importance. By scaling up the presented recipe, we build MM1, a family of multimodal models up to 30B parameters, including both dense models and mixture-of-experts (MoE) variants, that are SOTA in pre-training metrics and achieve competitive performance after supervised fine-tuning on a range of established multimodal benchmarks. Thanks to large-scale pre-training, MM1 enjoys appealing properties such as enhanced in-context learning, and multi-image reasoning, enabling few-shot chain-of-thought prompting.
A Unified View of Long-Sequence Models towards Modeling Million-Scale Dependencies
Feb 16, 2023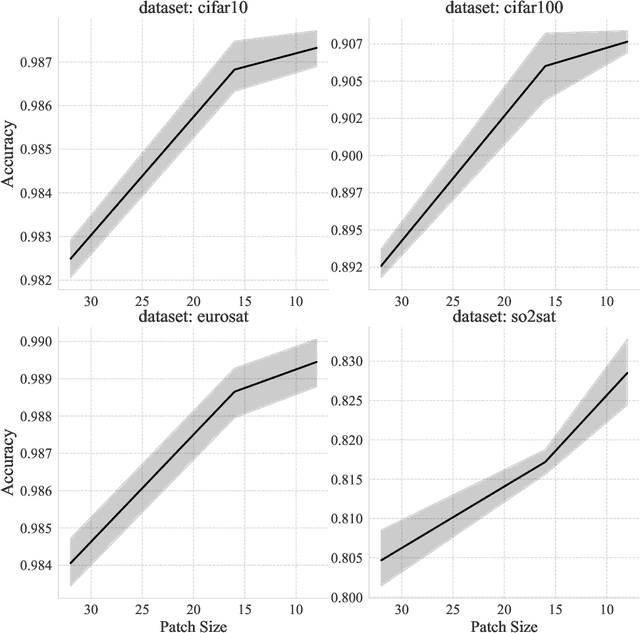

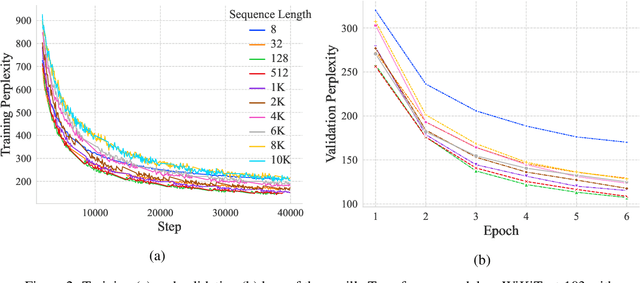
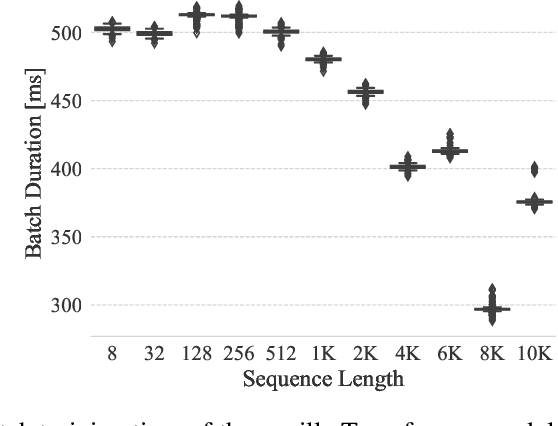
Ever since their conception, Transformers have taken over traditional sequence models in many tasks, such as NLP, image classification, and video/audio processing, for their fast training and superior performance. Much of the merit is attributable to positional encoding and multi-head attention. However, Transformers fall short in learning long-range dependencies mainly due to the quadratic complexity scaled with context length, in terms of both time and space. Consequently, over the past five years, a myriad of methods has been proposed to make Transformers more efficient. In this work, we first take a step back, study and compare existing solutions to long-sequence modeling in terms of their pure mathematical formulation. Specifically, we summarize them using a unified template, given their shared nature of token mixing. Through benchmarks, we then demonstrate that long context length does yield better performance, albeit application-dependent, and traditional Transformer models fall short in taking advantage of long-range dependencies. Next, inspired by emerging sparse models of huge capacity, we propose a machine learning system for handling million-scale dependencies. As a proof of concept, we evaluate the performance of one essential component of this system, namely, the distributed multi-head attention. We show that our algorithm can scale up attention computation by almost $40\times$ using four GeForce RTX 4090 GPUs, compared to vanilla multi-head attention mechanism. We believe this study is an instrumental step towards modeling million-scale dependencies.