 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLéonard Hussenot
RecurrentGemma: Moving Past Transformers for Efficient Open Language Models
Apr 11, 2024
We introduce RecurrentGemma, an open language model which uses Google's novel Griffin architecture. Griffin combines linear recurrences with local attention to achieve excellent performance on language. It has a fixed-sized state, which reduces memory use and enables efficient inference on long sequences. We provide a pre-trained model with 2B non-embedding parameters, and an instruction tuned variant. Both models achieve comparable performance to Gemma-2B despite being trained on fewer tokens.
Gemma: Open Models Based on Gemini Research and Technology
Mar 13, 2024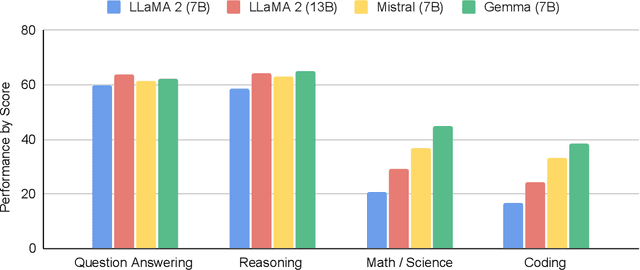

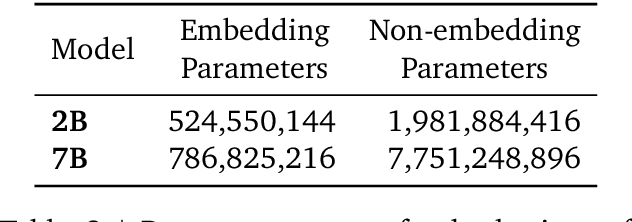
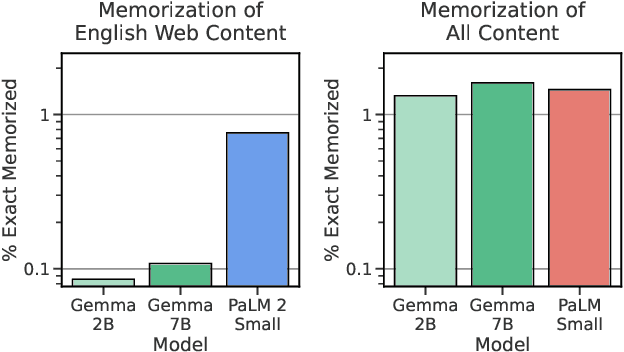
This work introduces Gemma, a family of lightweight, state-of-the art open models built from the research and technology used to create Gemini models. Gemma models demonstrate strong performance across academic benchmarks for language understanding, reasoning, and safety. We release two sizes of models (2 billion and 7 billion parameters), and provide both pretrained and fine-tuned checkpoints. Gemma outperforms similarly sized open models on 11 out of 18 text-based tasks, and we present comprehensive evaluations of safety and responsibility aspects of the models, alongside a detailed description of model development. We believe the responsible release of LLMs is critical for improving the safety of frontier models, and for enabling the next wave of LLM innovations.
MusicRL: Aligning Music Generation to Human Preferences
Feb 06, 2024We propose MusicRL, the first music generation system finetuned from human feedback. Appreciation of text-to-music models is particularly subjective since the concept of musicality as well as the specific intention behind a caption are user-dependent (e.g. a caption such as "upbeat work-out music" can map to a retro guitar solo or a techno pop beat). Not only this makes supervised training of such models challenging, but it also calls for integrating continuous human feedback in their post-deployment finetuning. MusicRL is a pretrained autoregressive MusicLM (Agostinelli et al., 2023) model of discrete audio tokens finetuned with reinforcement learning to maximise sequence-level rewards. We design reward functions related specifically to text-adherence and audio quality with the help from selected raters, and use those to finetune MusicLM into MusicRL-R. We deploy MusicLM to users and collect a substantial dataset comprising 300,000 pairwise preferences. Using Reinforcement Learning from Human Feedback (RLHF), we train MusicRL-U, the first text-to-music model that incorporates human feedback at scale. Human evaluations show that both MusicRL-R and MusicRL-U are preferred to the baseline. Ultimately, MusicRL-RU combines the two approaches and results in the best model according to human raters. Ablation studies shed light on the musical attributes influencing human preferences, indicating that text adherence and quality only account for a part of it. This underscores the prevalence of subjectivity in musical appreciation and calls for further involvement of human listeners in the finetuning of music generation models.
WARM: On the Benefits of Weight Averaged Reward Models
Jan 22, 2024Aligning large language models (LLMs) with human preferences through reinforcement learning (RLHF) can lead to reward hacking, where LLMs exploit failures in the reward model (RM) to achieve seemingly high rewards without meeting the underlying objectives. We identify two primary challenges when designing RMs to mitigate reward hacking: distribution shifts during the RL process and inconsistencies in human preferences. As a solution, we propose Weight Averaged Reward Models (WARM), first fine-tuning multiple RMs, then averaging them in the weight space. This strategy follows the observation that fine-tuned weights remain linearly mode connected when sharing the same pre-training. By averaging weights, WARM improves efficiency compared to the traditional ensembling of predictions, while improving reliability under distribution shifts and robustness to preference inconsistencies. Our experiments on summarization tasks, using best-of-N and RL methods, shows that WARM improves the overall quality and alignment of LLM predictions; for example, a policy RL fine-tuned with WARM has a 79.4% win rate against a policy RL fine-tuned with a single RM.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Factually Consistent Summarization via Reinforcement Learning with Textual Entailment Feedback
May 31, 2023
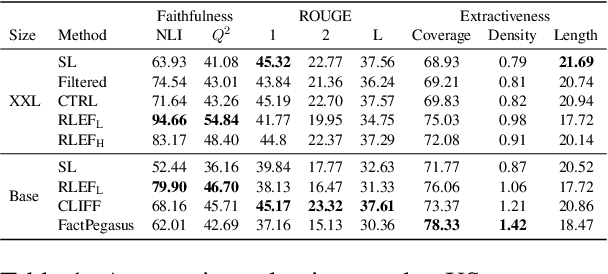
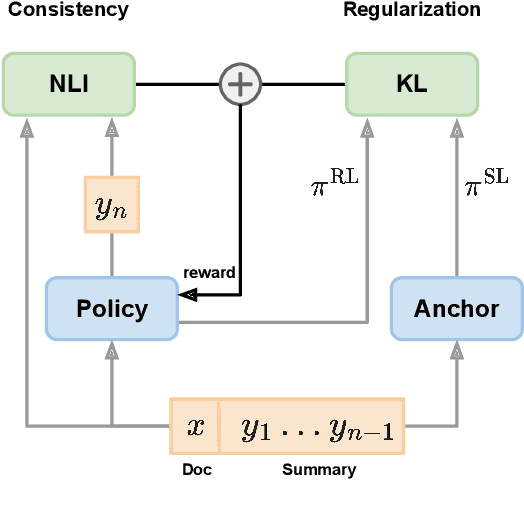
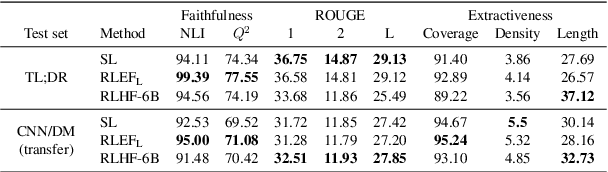
Despite the seeming success of contemporary grounded text generation systems, they often tend to generate factually inconsistent text with respect to their input. This phenomenon is emphasized in tasks like summarization, in which the generated summaries should be corroborated by their source article. In this work, we leverage recent progress on textual entailment models to directly address this problem for abstractive summarization systems. We use reinforcement learning with reference-free, textual entailment rewards to optimize for factual consistency and explore the ensuing trade-offs, as improved consistency may come at the cost of less informative or more extractive summaries. Our results, according to both automatic metrics and human evaluation, show that our method considerably improves the faithfulness, salience, and conciseness of the generated summaries.
vec2text with Round-Trip Translations
Sep 14, 2022

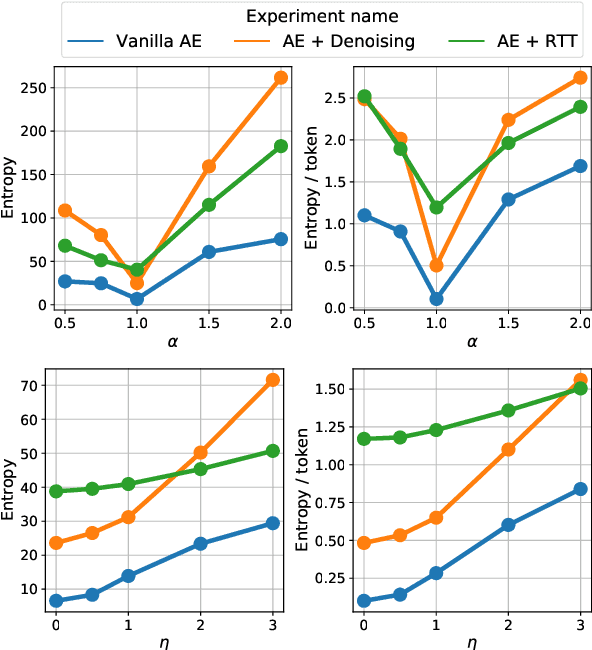

We investigate models that can generate arbitrary natural language text (e.g. all English sentences) from a bounded, convex and well-behaved control space. We call them universal vec2text models. Such models would allow making semantic decisions in the vector space (e.g. via reinforcement learning) while the natural language generation is handled by the vec2text model. We propose four desired properties: universality, diversity, fluency, and semantic structure, that such vec2text models should possess and we provide quantitative and qualitative methods to assess them. We implement a vec2text model by adding a bottleneck to a 250M parameters Transformer model and training it with an auto-encoding objective on 400M sentences (10B tokens) extracted from a massive web corpus. We propose a simple data augmentation technique based on round-trip translations and show in extensive experiments that the resulting vec2text model surprisingly leads to vector spaces that fulfill our four desired properties and that this model strongly outperforms both standard and denoising auto-encoders.
Learning Energy Networks with Generalized Fenchel-Young Losses
May 19, 2022
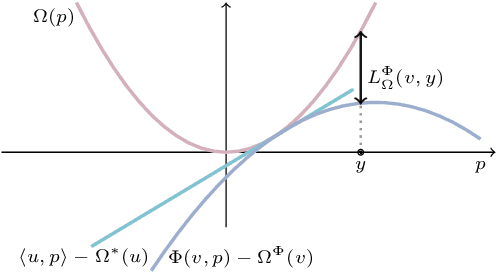
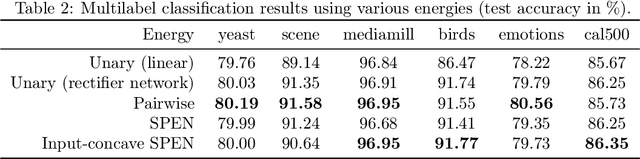
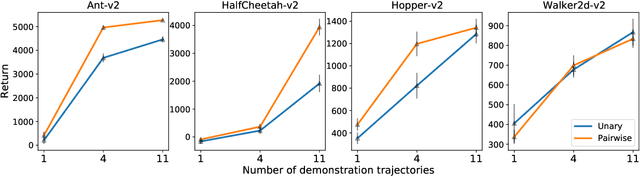
Energy-based models, a.k.a. energy networks, perform inference by optimizing an energy function, typically parametrized by a neural network. This allows one to capture potentially complex relationships between inputs and outputs. To learn the parameters of the energy function, the solution to that optimization problem is typically fed into a loss function. The key challenge for training energy networks lies in computing loss gradients, as this typically requires argmin/argmax differentiation. In this paper, building upon a generalized notion of conjugate function, which replaces the usual bilinear pairing with a general energy function, we propose generalized Fenchel-Young losses, a natural loss construction for learning energy networks. Our losses enjoy many desirable properties and their gradients can be computed efficiently without argmin/argmax differentiation. We also prove the calibration of their excess risk in the case of linear-concave energies. We demonstrate our losses on multilabel classification and imitation learning tasks.
RLDS: an Ecosystem to Generate, Share and Use Datasets in Reinforcement Learning
Nov 04, 2021


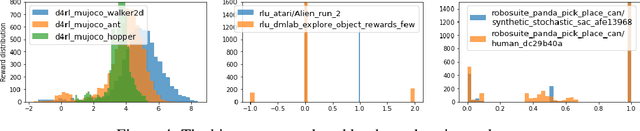
We introduce RLDS (Reinforcement Learning Datasets), an ecosystem for recording, replaying, manipulating, annotating and sharing data in the context of Sequential Decision Making (SDM) including Reinforcement Learning (RL), Learning from Demonstrations, Offline RL or Imitation Learning. RLDS enables not only reproducibility of existing research and easy generation of new datasets, but also accelerates novel research. By providing a standard and lossless format of datasets it enables to quickly test new algorithms on a wider range of tasks. The RLDS ecosystem makes it easy to share datasets without any loss of information and to be agnostic to the underlying original format when applying various data processing pipelines to large collections of datasets. Besides, RLDS provides tools for collecting data generated by either synthetic agents or humans, as well as for inspecting and manipulating the collected data. Ultimately, integration with TFDS facilitates the sharing of RL datasets with the research community.
Continuous Control with Action Quantization from Demonstrations
Oct 19, 2021
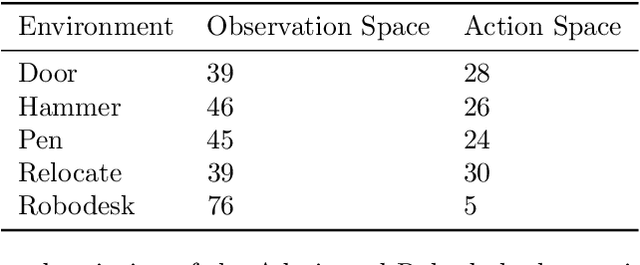

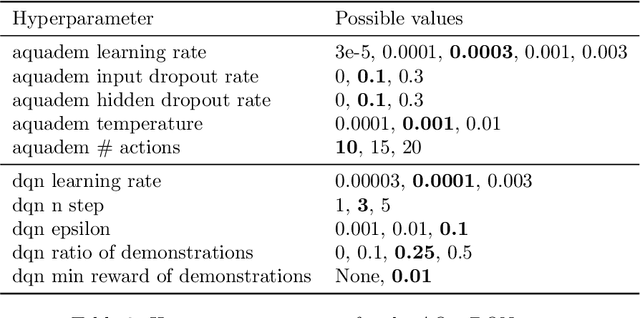
In Reinforcement Learning (RL), discrete actions, as opposed to continuous actions, result in less complex exploration problems and the immediate computation of the maximum of the action-value function which is central to dynamic programming-based methods. In this paper, we propose a novel method: Action Quantization from Demonstrations (AQuaDem) to learn a discretization of continuous action spaces by leveraging the priors of demonstrations. This dramatically reduces the exploration problem, since the actions faced by the agent not only are in a finite number but also are plausible in light of the demonstrator's behavior. By discretizing the action space we can apply any discrete action deep RL algorithm to the continuous control problem. We evaluate the proposed method on three different setups: RL with demonstrations, RL with play data --demonstrations of a human playing in an environment but not solving any specific task-- and Imitation Learning. For all three setups, we only consider human data, which is more challenging than synthetic data. We found that AQuaDem consistently outperforms state-of-the-art continuous control methods, both in terms of performance and sample efficiency. We provide visualizations and videos in the paper's website: https://google-research.github.io/aquadem.