 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMartin Wicke
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023
This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
The CSIRO Crown-of-Thorn Starfish Detection Dataset
Nov 29, 2021
Crown-of-Thorn Starfish (COTS) outbreaks are a major cause of coral loss on the Great Barrier Reef (GBR) and substantial surveillance and control programs are underway in an attempt to manage COTS populations to ecologically sustainable levels. We release a large-scale, annotated underwater image dataset from a COTS outbreak area on the GBR, to encourage research on Machine Learning and AI-driven technologies to improve the detection, monitoring, and management of COTS populations at reef scale. The dataset is released and hosted in a Kaggle competition that challenges the international Machine Learning community with the task of COTS detection from these underwater images.
Unsupervised Learning of Depth and Ego-Motion from Monocular Video Using 3D Geometric Constraints
Jun 09, 2018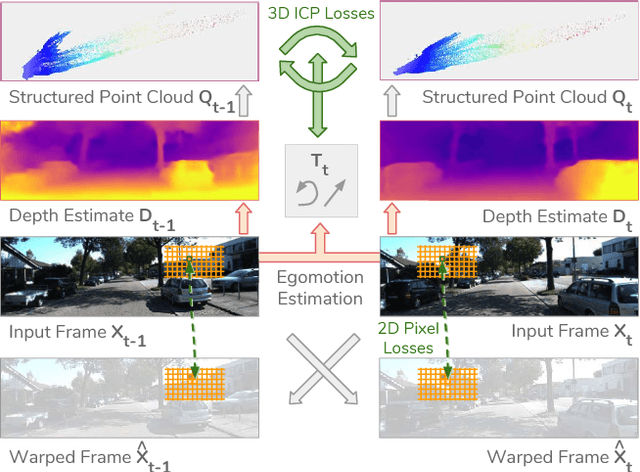
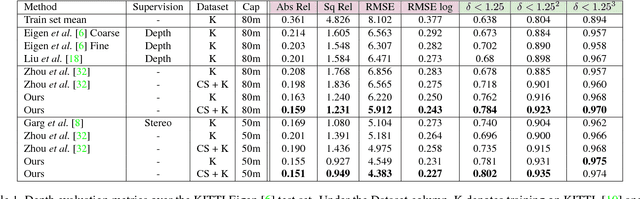
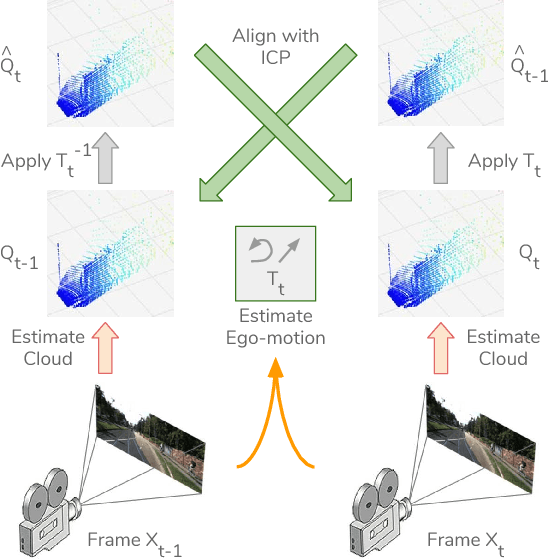
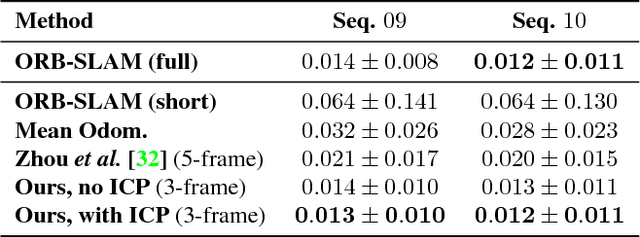
We present a novel approach for unsupervised learning of depth and ego-motion from monocular video. Unsupervised learning removes the need for separate supervisory signals (depth or ego-motion ground truth, or multi-view video). Prior work in unsupervised depth learning uses pixel-wise or gradient-based losses, which only consider pixels in small local neighborhoods. Our main contribution is to explicitly consider the inferred 3D geometry of the scene, enforcing consistency of the estimated 3D point clouds and ego-motion across consecutive frames. This is a challenging task and is solved by a novel (approximate) backpropagation algorithm for aligning 3D structures. We combine this novel 3D-based loss with 2D losses based on photometric quality of frame reconstructions using estimated depth and ego-motion from adjacent frames. We also incorporate validity masks to avoid penalizing areas in which no useful information exists. We test our algorithm on the KITTI dataset and on a video dataset captured on an uncalibrated mobile phone camera. Our proposed approach consistently improves depth estimates on both datasets, and outperforms the state-of-the-art for both depth and ego-motion. Because we only require a simple video, learning depth and ego-motion on large and varied datasets becomes possible. We demonstrate this by training on the low quality uncalibrated video dataset and evaluating on KITTI, ranking among top performing prior methods which are trained on KITTI itself.
TensorFlow Estimators: Managing Simplicity vs. Flexibility in High-Level Machine Learning Frameworks
Aug 08, 2017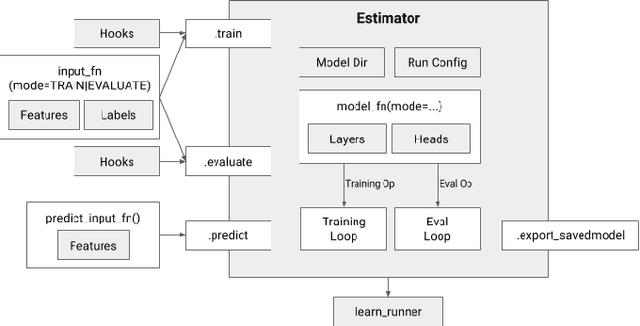
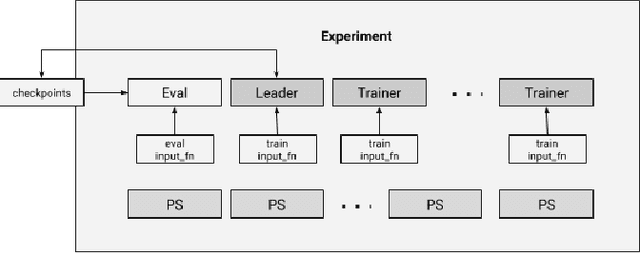
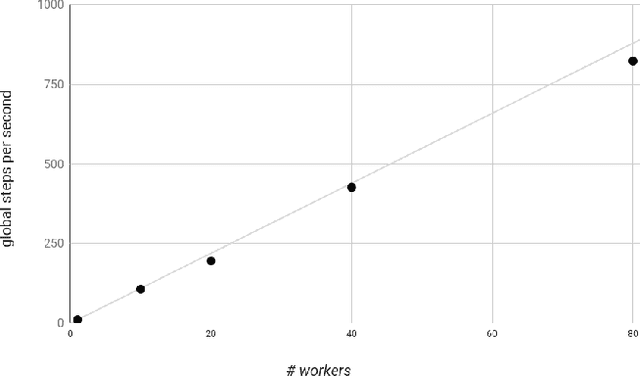
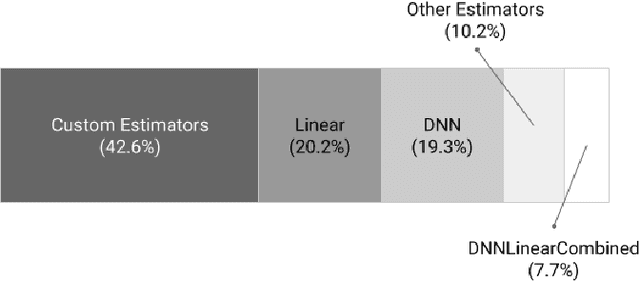
We present a framework for specifying, training, evaluating, and deploying machine learning models. Our focus is on simplifying cutting edge machine learning for practitioners in order to bring such technologies into production. Recognizing the fast evolution of the field of deep learning, we make no attempt to capture the design space of all possible model architectures in a domain- specific language (DSL) or similar configuration language. We allow users to write code to define their models, but provide abstractions that guide develop- ers to write models in ways conducive to productionization. We also provide a unifying Estimator interface, making it possible to write downstream infrastructure (e.g. distributed training, hyperparameter tuning) independent of the model implementation. We balance the competing demands for flexibility and simplicity by offering APIs at different levels of abstraction, making common model architectures available out of the box, while providing a library of utilities designed to speed up experimentation with model architectures. To make out of the box models flexible and usable across a wide range of problems, these canned Estimators are parameterized not only over traditional hyperparameters, but also using feature columns, a declarative specification describing how to interpret input data. We discuss our experience in using this framework in re- search and production environments, and show the impact on code health, maintainability, and development speed.
Geometry-Based Next Frame Prediction from Monocular Video
Jun 12, 2017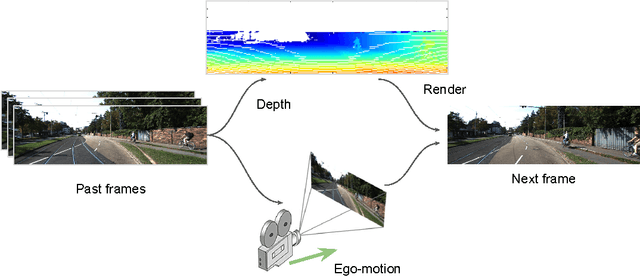

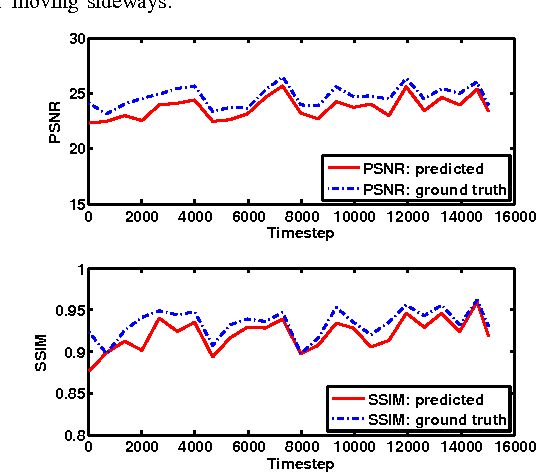

We consider the problem of next frame prediction from video input. A recurrent convolutional neural network is trained to predict depth from monocular video input, which, along with the current video image and the camera trajectory, can then be used to compute the next frame. Unlike prior next-frame prediction approaches, we take advantage of the scene geometry and use the predicted depth for generating the next frame prediction. Our approach can produce rich next frame predictions which include depth information attached to each pixel. Another novel aspect of our approach is that it predicts depth from a sequence of images (e.g. in a video), rather than from a single still image. We evaluate the proposed approach on the KITTI dataset, a standard dataset for benchmarking tasks relevant to autonomous driving. The proposed method produces results which are visually and numerically superior to existing methods that directly predict the next frame. We show that the accuracy of depth prediction improves as more prior frames are considered.
TensorFlow: A system for large-scale machine learning
May 31, 2016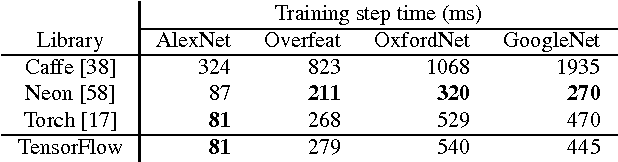

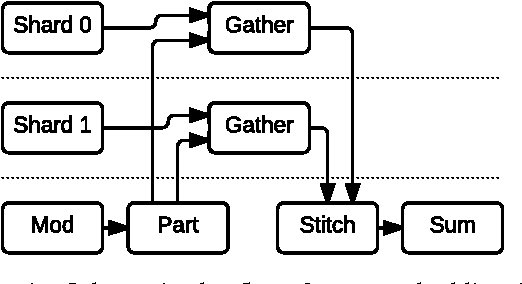
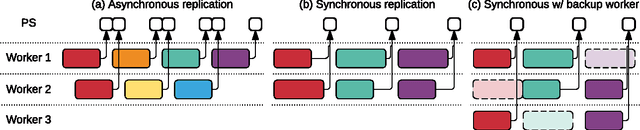
TensorFlow is a machine learning system that operates at large scale and in heterogeneous environments. TensorFlow uses dataflow graphs to represent computation, shared state, and the operations that mutate that state. It maps the nodes of a dataflow graph across many machines in a cluster, and within a machine across multiple computational devices, including multicore CPUs, general-purpose GPUs, and custom designed ASICs known as Tensor Processing Units (TPUs). This architecture gives flexibility to the application developer: whereas in previous "parameter server" designs the management of shared state is built into the system, TensorFlow enables developers to experiment with novel optimizations and training algorithms. TensorFlow supports a variety of applications, with particularly strong support for training and inference on deep neural networks. Several Google services use TensorFlow in production, we have released it as an open-source project, and it has become widely used for machine learning research. In this paper, we describe the TensorFlow dataflow model in contrast to existing systems, and demonstrate the compelling performance that TensorFlow achieves for several real-world applications.
TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems
Mar 16, 2016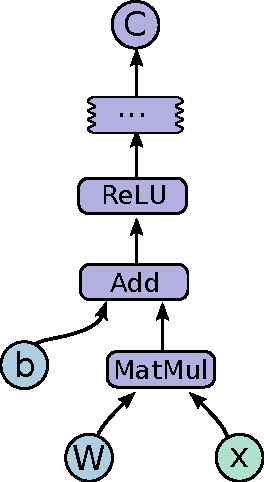

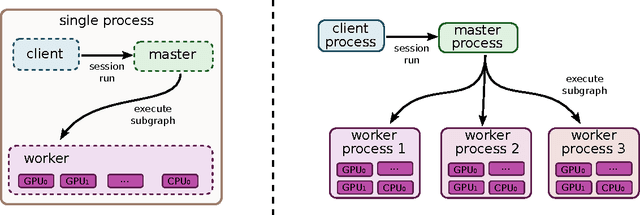
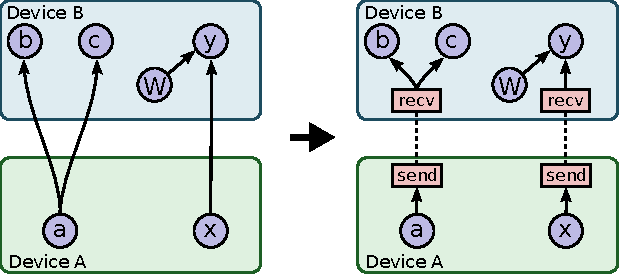
TensorFlow is an interface for expressing machine learning algorithms, and an implementation for executing such algorithms. A computation expressed using TensorFlow can be executed with little or no change on a wide variety of heterogeneous systems, ranging from mobile devices such as phones and tablets up to large-scale distributed systems of hundreds of machines and thousands of computational devices such as GPU cards. The system is flexible and can be used to express a wide variety of algorithms, including training and inference algorithms for deep neural network models, and it has been used for conducting research and for deploying machine learning systems into production across more than a dozen areas of computer science and other fields, including speech recognition, computer vision, robotics, information retrieval, natural language processing, geographic information extraction, and computational drug discovery. This paper describes the TensorFlow interface and an implementation of that interface that we have built at Google. The TensorFlow API and a reference implementation were released as an open-source package under the Apache 2.0 license in November, 2015 and are available at www.tensorflow.org.